 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Domain Generalization on EEG-based Emotion Recognition
Apr 18, 2022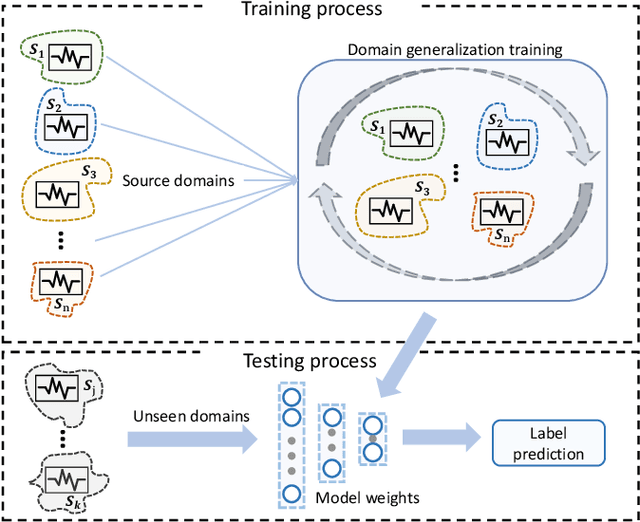
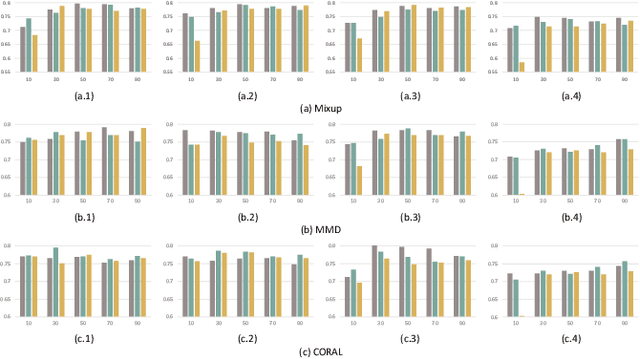
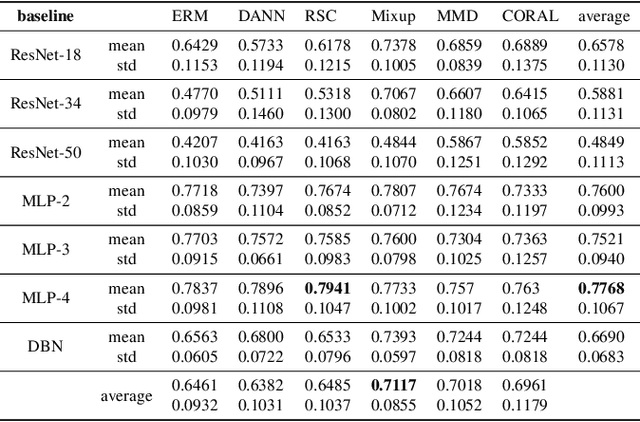
Electroencephalography (EEG) based emotion recognition has demonstrated tremendous improvement in recent years. Specifically, numerous domain adaptation (DA) algorithms have been exploited in the past five years to enhance the generalization of emotion recognition models across subjects. The DA methods assume that calibration data (although unlabeled) exists in the target domain (new user). However, this assumption conflicts with the application scenario that the model should be deployed without the time-consuming calibration experiments. We argue that domain generalization (DG) is more reasonable than DA in these applications. DG learns how to generalize to unseen target domains by leveraging knowledge from multiple source domains, which provides a new possibility to train general models. In this paper, we for the first time benchmark state-of-the-art DG algorithms on EEG-based emotion recognition. Since convolutional neural network (CNN), deep brief network (DBN) and multilayer perceptron (MLP) have been proved to be effective emotion recognition models, we use these three models as solid baselines. Experimental results show that DG achieves an accuracy of up to 79.41\% on the SEED dataset for recognizing three emotions, indicting the potential of DG in zero-training emotion recognition when multiple sources are available.
Joining datasets via data augmentation in the label space for neural networks
Jun 17, 2021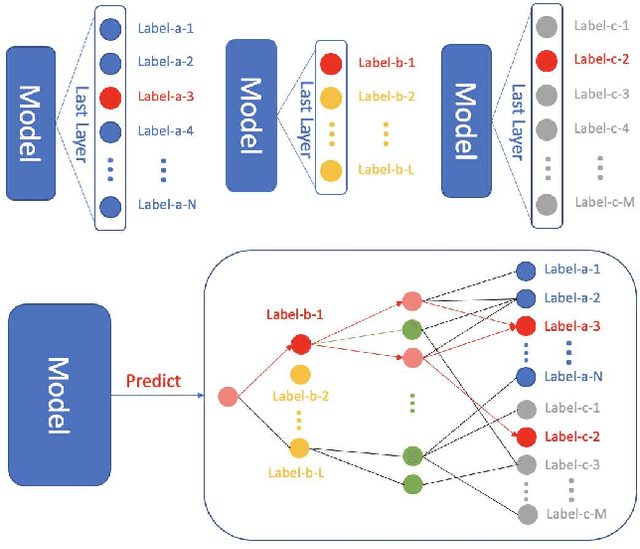
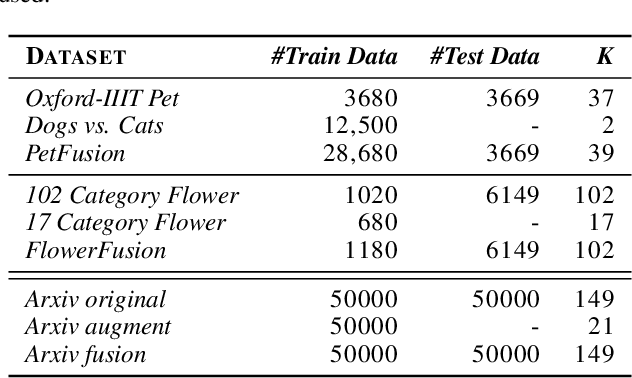
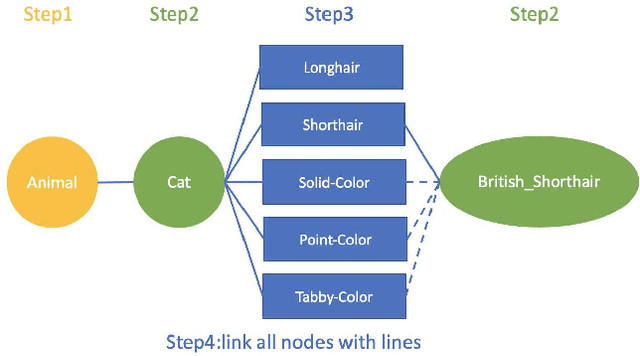
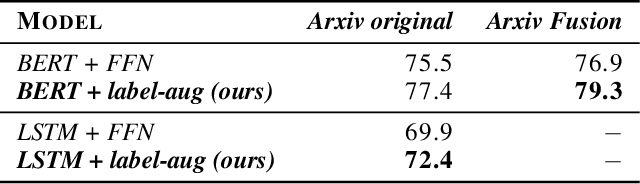
Most, if not all, modern deep learning systems restrict themselves to a single dataset for neural network training and inference. In this article, we are interested in systematic ways to join datasets that are made of similar purposes. Unlike previous published works that ubiquitously conduct the dataset joining in the uninterpretable latent vectorial space, the core to our method is an augmentation procedure in the label space. The primary challenge to address the label space for dataset joining is the discrepancy between labels: non-overlapping label annotation sets, different labeling granularity or hierarchy and etc. Notably we propose a new technique leveraging artificially created knowledge graph, recurrent neural networks and policy gradient that successfully achieve the dataset joining in the label space. Empirical results on both image and text classification justify the validity of our approach.
A critical look at the current train/test split in machine learning
Jun 08, 2021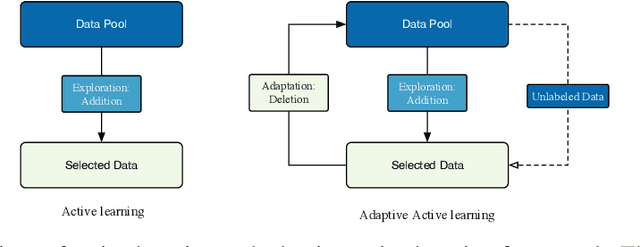

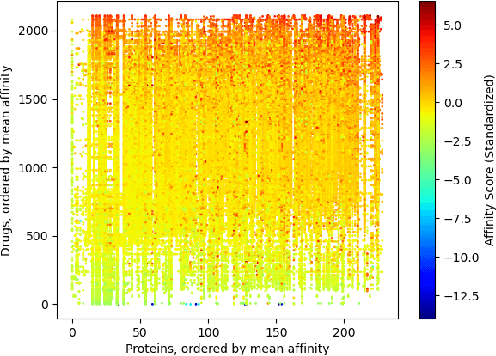
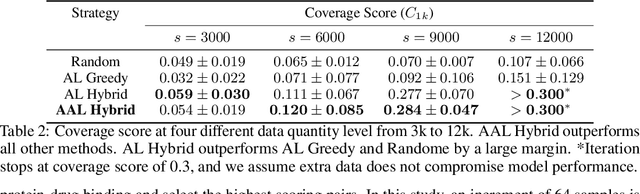
The randomized or cross-validated split of training and testing sets has been adopted as the gold standard of machine learning for decades. The establishment of these split protocols are based on two assumptions: (i)-fixing the dataset to be eternally static so we could evaluate different machine learning algorithms or models; (ii)-there is a complete set of annotated data available to researchers or industrial practitioners. However, in this article, we intend to take a closer and critical look at the split protocol itself and point out its weakness and limitation, especially for industrial applications. In many real-world problems, we must acknowledge that there are numerous situations where assumption (ii) does not hold. For instance, for interdisciplinary applications like drug discovery, it often requires real lab experiments to annotate data which poses huge costs in both time and financial considerations. In other words, it can be very difficult or even impossible to satisfy assumption (ii). In this article, we intend to access this problem and reiterate the paradigm of active learning, and investigate its potential on solving problems under unconventional train/test split protocols. We further propose a new adaptive active learning architecture (AAL) which involves an adaptation policy, in comparison with the traditional active learning that only unidirectionally adds data points to the training pool. We primarily justify our points by extensively investigating an interdisciplinary drug-protein binding problem. We additionally evaluate AAL on more conventional machine learning benchmarking datasets like CIFAR-10 to demonstrate the generalizability and efficacy of the new framework.
Levenshtein Transformer
May 27, 2019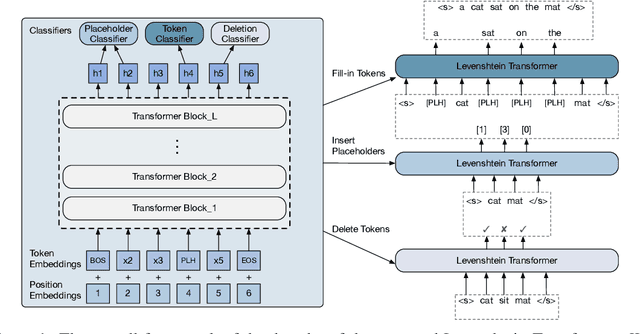
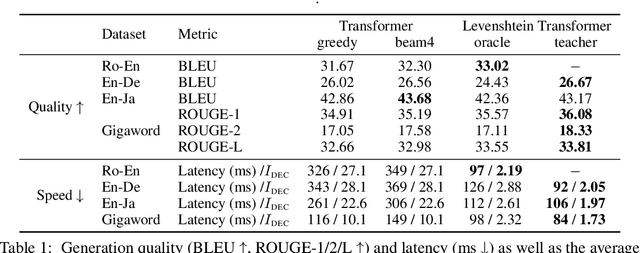
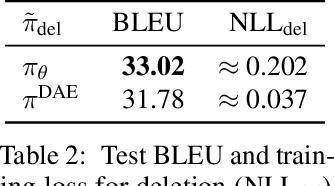
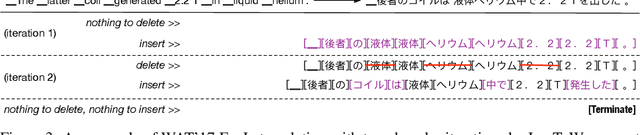
Modern neural sequence generation models are built to either generate tokens step-by-step from scratch or (iteratively) modify a sequence of tokens bounded by a fixed length. In this work, we develop Levenshtein Transformer, a new partially autoregressive model devised for more flexible and amenable sequence generation. Unlike previous approaches, the atomic operations of our model are insertion and deletion. The combination of them facilitates not only generation but also sequence refinement allowing dynamic length changes. We also propose a set of new training techniques dedicated at them, effectively exploiting one as the other's learning signal thanks to their complementary nature. Experiments applying the proposed model achieve comparable performance but much-improved efficiency on both generation (e.g. machine translation, text summarization) and refinement tasks (e.g. automatic post-editing). We further confirm the flexibility of our model by showing a Levenshtein Transformer trained by machine translation can straightforwardly be used for automatic post-editing.
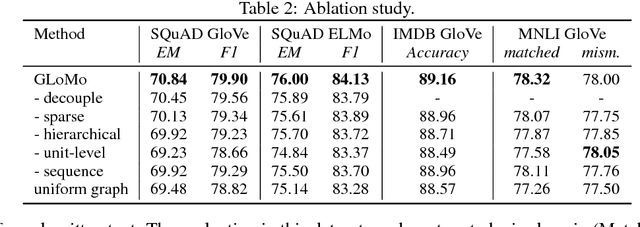
GLoMo: Unsupervisedly Learned Relational Graphs as Transferable Representations
Jul 02, 2018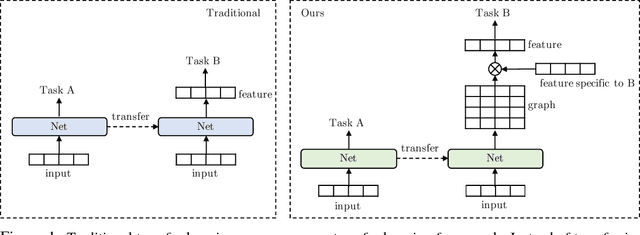
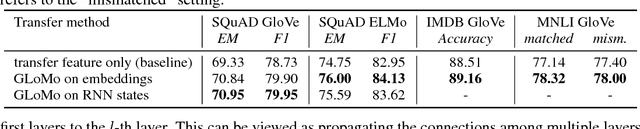
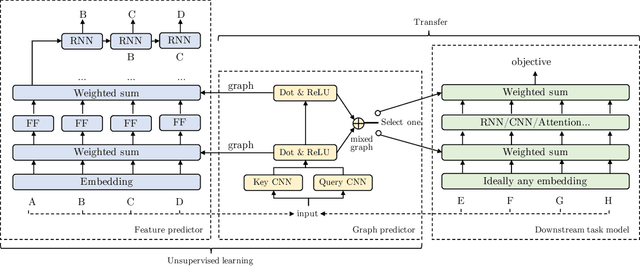
Modern deep transfer learning approaches have mainly focused on learning generic feature vectors from one task that are transferable to other tasks, such as word embeddings in language and pretrained convolutional features in vision. However, these approaches usually transfer unary features and largely ignore more structured graphical representations. This work explores the possibility of learning generic latent relational graphs that capture dependencies between pairs of data units (e.g., words or pixels) from large-scale unlabeled data and transferring the graphs to downstream tasks. Our proposed transfer learning framework improves performance on various tasks including question answering, natural language inference, sentiment analysis, and image classification. We also show that the learned graphs are generic enough to be transferred to different embeddings on which the graphs have not been trained (including GloVe embeddings, ELMo embeddings, and task-specific RNN hidden unit), or embedding-free units such as image pixels.
Adversarially Regularized Autoencoders
Jun 29, 2018
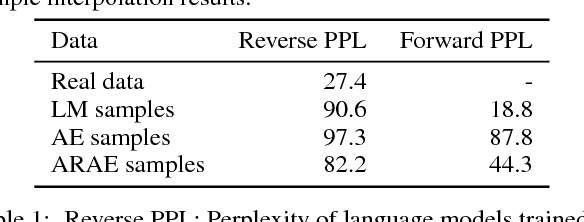


Deep latent variable models, trained using variational autoencoders or generative adversarial networks, are now a key technique for representation learning of continuous structures. However, applying similar methods to discrete structures, such as text sequences or discretized images, has proven to be more challenging. In this work, we propose a flexible method for training deep latent variable models of discrete structures. Our approach is based on the recently-proposed Wasserstein autoencoder (WAE) which formalizes the adversarial autoencoder (AAE) as an optimal transport problem. We first extend this framework to model discrete sequences, and then further explore different learned priors targeting a controllable representation. This adversarially regularized autoencoder (ARAE) allows us to generate natural textual outputs as well as perform manipulations in the latent space to induce change in the output space. Finally we show that the latent representation can be trained to perform unaligned textual style transfer, giving improvements both in automatic/human evaluation compared to existing methods.
Retrieval-Augmented Convolutional Neural Networks for Improved Robustness against Adversarial Examples
Feb 26, 2018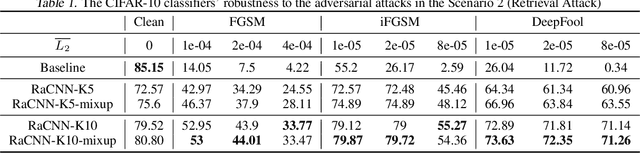
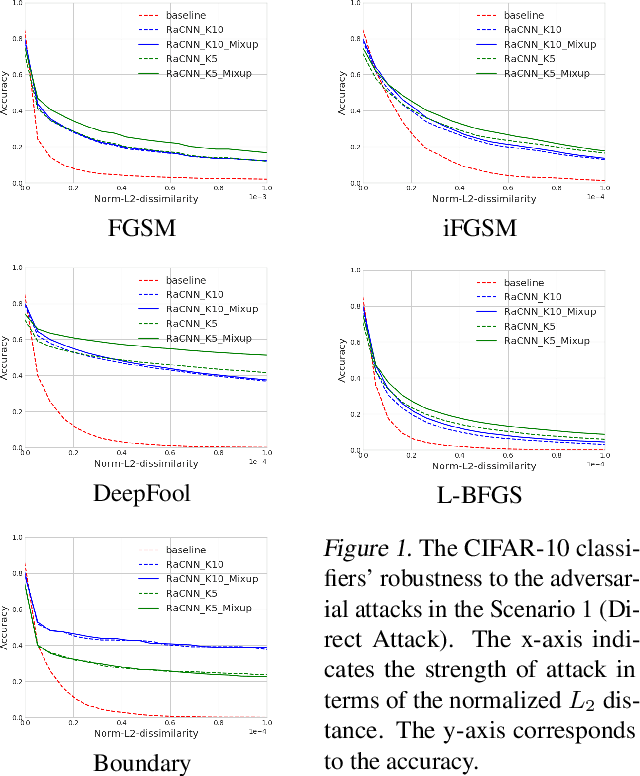
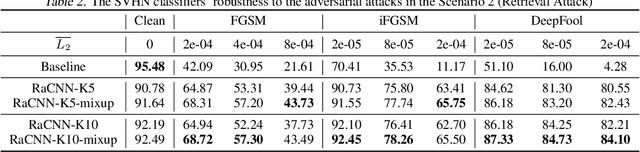
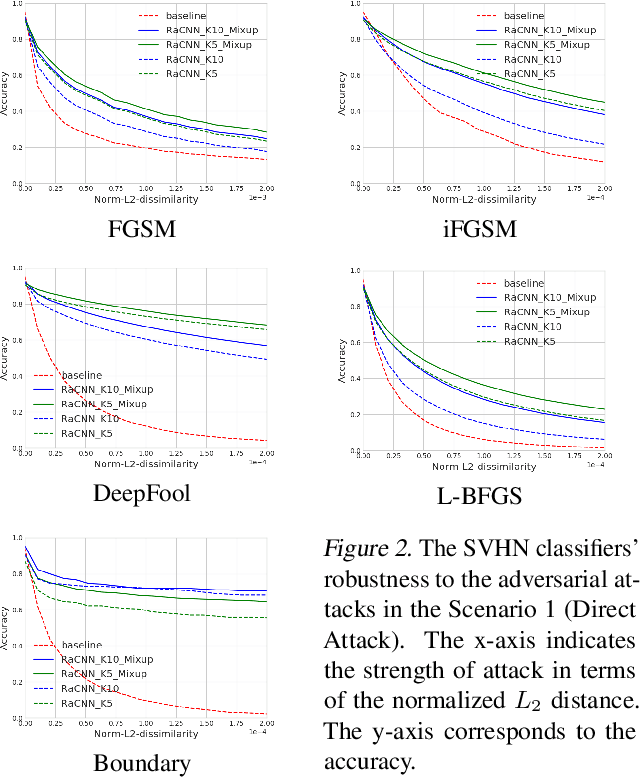
We propose a retrieval-augmented convolutional network and propose to train it with local mixup, a novel variant of the recently proposed mixup algorithm. The proposed hybrid architecture combining a convolutional network and an off-the-shelf retrieval engine was designed to mitigate the adverse effect of off-manifold adversarial examples, while the proposed local mixup addresses on-manifold ones by explicitly encouraging the classifier to locally behave linearly on the data manifold. Our evaluation of the proposed approach against five readily-available adversarial attacks on three datasets--CIFAR-10, SVHN and ImageNet--demonstrate the improved robustness compared to the vanilla convolutional network.
End to End Learning for Self-Driving Cars
Apr 25, 2016


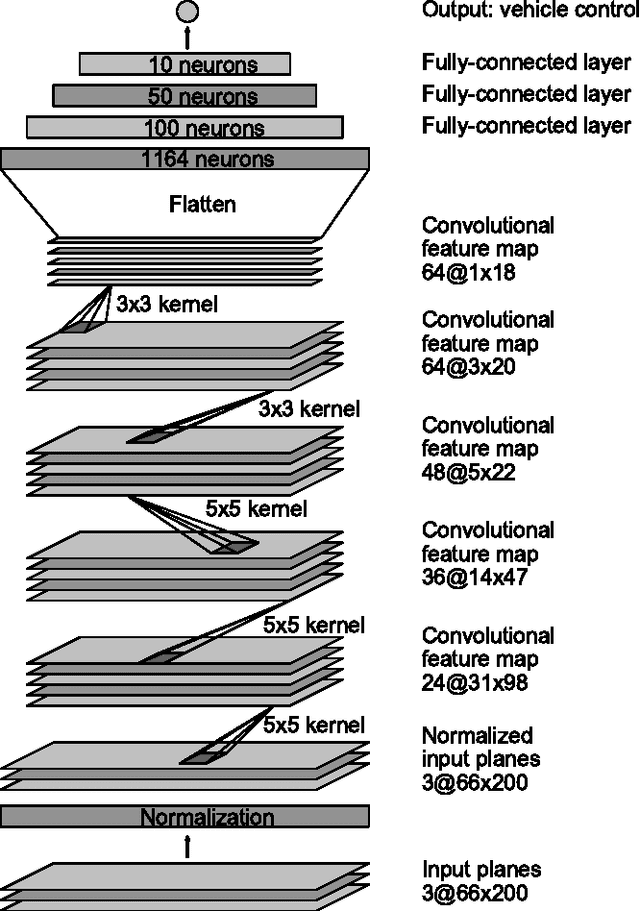
We trained a convolutional neural network (CNN) to map raw pixels from a single front-facing camera directly to steering commands. This end-to-end approach proved surprisingly powerful. With minimum training data from humans the system learns to drive in traffic on local roads with or without lane markings and on highways. It also operates in areas with unclear visual guidance such as in parking lots and on unpaved roads. The system automatically learns internal representations of the necessary processing steps such as detecting useful road features with only the human steering angle as the training signal. We never explicitly trained it to detect, for example, the outline of roads. Compared to explicit decomposition of the problem, such as lane marking detection, path planning, and control, our end-to-end system optimizes all processing steps simultaneously. We argue that this will eventually lead to better performance and smaller systems. Better performance will result because the internal components self-optimize to maximize overall system performance, instead of optimizing human-selected intermediate criteria, e.g., lane detection. Such criteria understandably are selected for ease of human interpretation which doesn't automatically guarantee maximum system performance. Smaller networks are possible because the system learns to solve the problem with the minimal number of processing steps. We used an NVIDIA DevBox and Torch 7 for training and an NVIDIA DRIVE(TM) PX self-driving car computer also running Torch 7 for determining where to drive. The system operates at 30 frames per second (FPS).