 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NVIDIA PilotNet Experiments
Oct 17, 2020
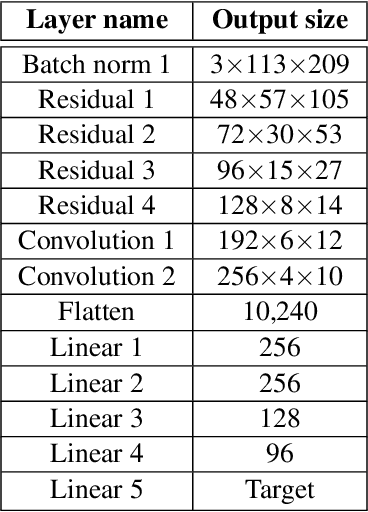


Four years ago, an experimental system known as PilotNet became the first NVIDIA system to steer an autonomous car along a roadway. This system represents a departure from the classical approach for self-driving in which the process is manually decomposed into a series of modules, each performing a different task. In PilotNet, on the other hand, a single deep neural network (DNN) takes pixels as input and produces a desired vehicle trajectory as output; there are no distinct internal modules connected by human-designed interfaces. We believe that handcrafted interfaces ultimately limit performance by restricting information flow through the system and that a learned approach, in combination with other artificial intelligence systems that add redundancy, will lead to better overall performing systems. We continue to conduct research toward that goal. This document describes the PilotNet lane-keeping effort, carried out over the past five years by our NVIDIA PilotNet group in Holmdel, New Jersey. Here we present a snapshot of system status in mid-2020 and highlight some of the work done by the PilotNet group.
Fast Incremental Learning for Off-Road Robot Navigation
Jun 26, 2016

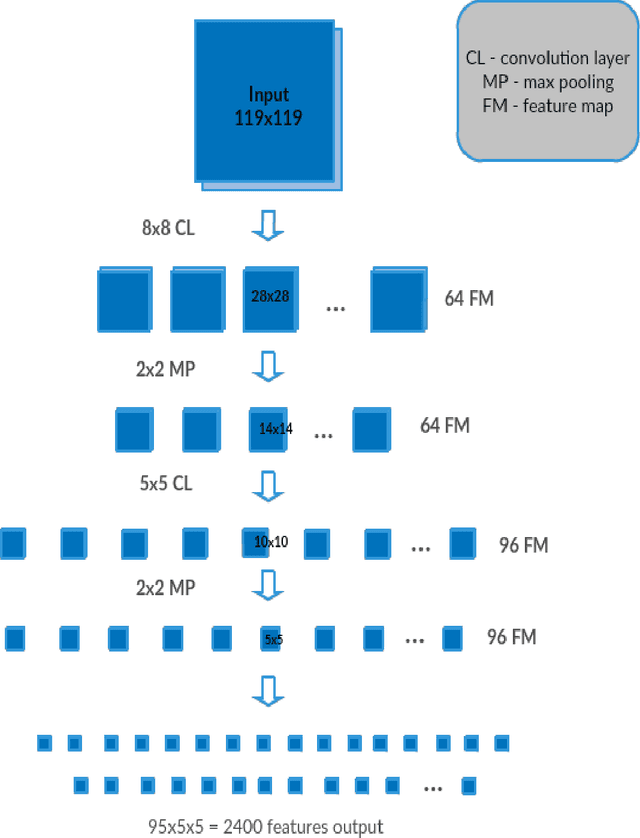

A promising approach to autonomous driving is machine learning. In such systems, training datasets are created that capture the sensory input to a vehicle as well as the desired response. A disadvantage of using a learned navigation system is that the learning process itself may require a huge number of training examples and a large amount of computing. To avoid the need to collect a large training set of driving examples, we describe a system that takes advantage of the huge number of training examples provided by ImageNet, but is able to adapt quickly using a small training set for the specific driving environment.
End to End Learning for Self-Driving Cars
Apr 25, 2016


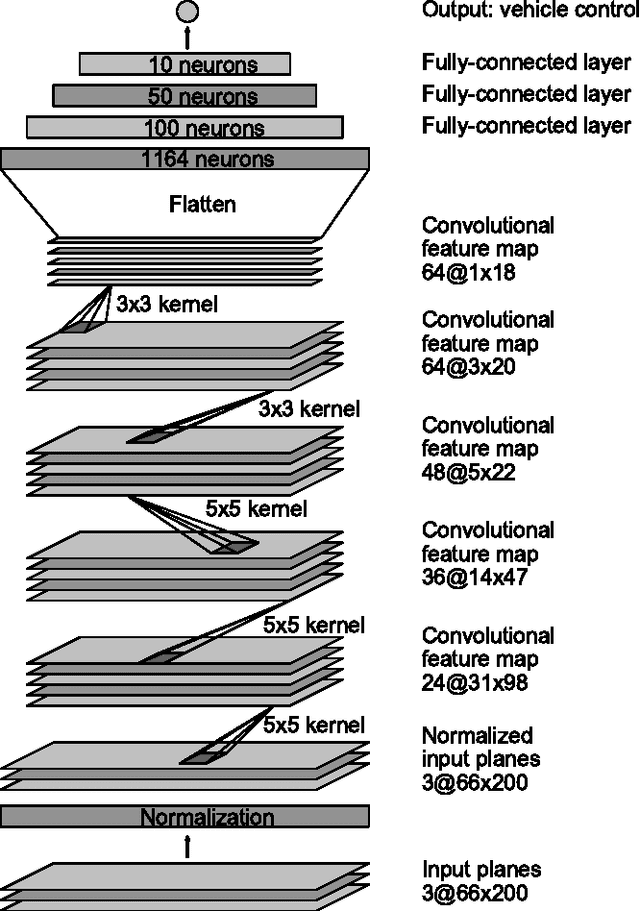
We trained a convolutional neural network (CNN) to map raw pixels from a single front-facing camera directly to steering commands. This end-to-end approach proved surprisingly powerful. With minimum training data from humans the system learns to drive in traffic on local roads with or without lane markings and on highways. It also operates in areas with unclear visual guidance such as in parking lots and on unpaved roads. The system automatically learns internal representations of the necessary processing steps such as detecting useful road features with only the human steering angle as the training signal. We never explicitly trained it to detect, for example, the outline of roads. Compared to explicit decomposition of the problem, such as lane marking detection, path planning, and control, our end-to-end system optimizes all processing steps simultaneously. We argue that this will eventually lead to better performance and smaller systems. Better performance will result because the internal components self-optimize to maximize overall system performance, instead of optimizing human-selected intermediate criteria, e.g., lane detection. Such criteria understandably are selected for ease of human interpretation which doesn't automatically guarantee maximum system performance. Smaller networks are possible because the system learns to solve the problem with the minimal number of processing steps. We used an NVIDIA DevBox and Torch 7 for training and an NVIDIA DRIVE(TM) PX self-driving car computer also running Torch 7 for determining where to drive. The system operates at 30 frames per second (FPS).