 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryoFastAR: Fast Cryo-EM Ab Initio Reconstruction Made Easy
Jun 06, 2025Pose estimation from unordered images is fundamental for 3D reconstruction, robotics, and scientific imaging. Recent geometric foundation models, such as DUSt3R, enable end-to-end dense 3D reconstruction but remain underexplored in scientific imaging fields like cryo-electron microscopy (cryo-EM) for near-atomic protein reconstruction. In cryo-EM, pose estimation and 3D reconstruction from unordered particle images still depend on time-consuming iterative optimization, primarily due to challenges such as low signal-to-noise ratios (SNR) and distortions from the contrast transfer function (CTF). We introduce CryoFastAR, the first geometric foundation model that can directly predict poses from Cryo-EM noisy images for Fast ab initio Reconstruction. By integrating multi-view features and training on large-scale simulated cryo-EM data with realistic noise and CTF modulations, CryoFastAR enhances pose estimation accuracy and generalization. To enhance training stability, we propose a progressive training strategy that first allows the model to extract essential features under simpler conditions before gradually increasing difficulty to improve robustness. Experiments show that CryoFastAR achieves comparable quality while significantly accelerating inference over traditional iterative approaches on both synthetic and real datasets.
DRACO: A Denoising-Reconstruction Autoencoder for Cryo-EM
Oct 15, 2024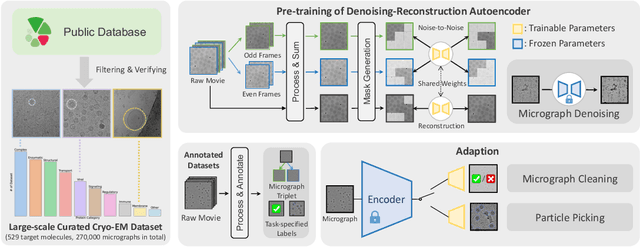
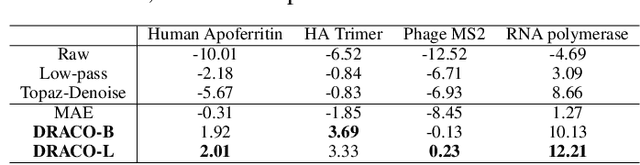
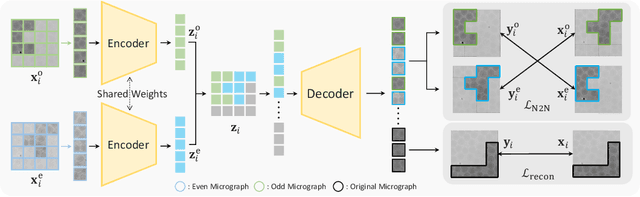

Foundation models in computer vision have demonstrated exceptional performance in zero-shot and few-shot tasks by extracting multi-purpose features from large-scale datasets through self-supervised pre-training methods. However, these models often overlook the severe corruption in cryogenic electron microscopy (cryo-EM) images by high-level noises. We introduce DRACO, a Denoising-Reconstruction Autoencoder for CryO-EM, inspired by the Noise2Noise (N2N) approach. By processing cryo-EM movies into odd and even images and treating them as independent noisy observations, we apply a denoising-reconstruction hybrid training scheme. We mask both images to create denoising and reconstruction tasks. For DRACO's pre-training, the quality of the dataset is essential, we hence build a high-quality, diverse dataset from an uncurated public database, including over 270,000 movies or micrographs. After pre-training, DRACO naturally serves as a generalizable cryo-EM image denoiser and a foundation model for various cryo-EM downstream tasks. DRACO demonstrates the best performance in denoising, micrograph curation, and particle picking tasks compared to state-of-the-art baselines. We will release the code, pre-trained models, and the curated dataset to stimulate further research.
LightCAM: A Fast and Light Implementation of Context-Aware Masking based D-TDNN for Speaker Verification
Feb 12, 2024
Traditional Time Delay Neural Networks (TDNN) have achieved state-of-the-art performance at the cost of high computational complexity and slower inference speed, making them difficult to implement in an industrial environment. The Densely Connected Time Delay Neural Network (D-TDNN) with Context Aware Masking (CAM) module has proven to be an efficient structure to reduce complexity while maintaining system performance. In this paper, we propose a fast and lightweight model, LightCAM, which further adopts a depthwise separable convolution module (DSM) and uses multi-scale feature aggregation (MFA) for feature fusion at different levels. Extensive experiments are conducted on VoxCeleb dataset, the comparative results show that it has achieved an EER of 0.83 and MinDCF of 0.0891 in VoxCeleb1-O, which outperforms the other mainstream speaker verification methods. In addition, complexity analysis further demonstrates that the proposed architecture has lower computational cost and faster inference speed.
GenEM: Physics-Informed Generative Cryo-Electron Microscopy
Dec 04, 2023


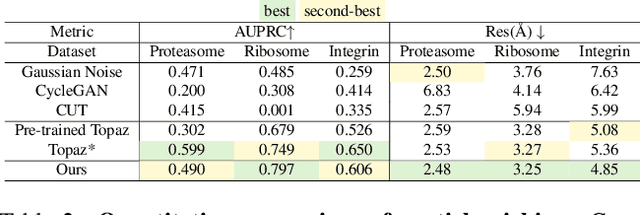
In the past decade, deep conditional generative models have revolutionized the generation of realistic images, extending their application from entertainment to scientific domains. Single-particle cryo-electron microscopy (cryo-EM) is crucial in resolving near-atomic resolution 3D structures of proteins, such as the SARS-COV-2 spike protein. To achieve high-resolution reconstruction, AI models for particle picking and pose estimation have been adopted. However, their performance is still limited as they lack high-quality annotated datasets. To address this, we introduce physics-informed generative cryo-electron microscopy (GenEM), which for the first time integrates physical-based cryo-EM simulation with a generative unpaired noise translation to generate physically correct synthetic cryo-EM datasets with realistic noises. Initially, GenEM simulates the cryo-EM imaging process based on a virtual specimen. To generate realistic noises, we leverage an unpaired noise translation via contrastive learning with a novel mask-guided sampling scheme. Extensive experiments show that GenEM is capable of generating realistic cryo-EM images. The generated dataset can further enhance particle picking and pose estimation models, eventually improving the reconstruction resolution. We will release our code and annotated synthetic datasets.
CryoFormer: Continuous Reconstruction of 3D Structures from Cryo-EM Data using Transformer-based Neural Representations
Mar 28, 2023High-resolution heterogeneous reconstruction of 3D structures of proteins and other biomolecules using cryo-electron microscopy (cryo-EM) is essential for understanding fundamental processes of life. However, it is still challenging to reconstruct the continuous motions of 3D structures from hundreds of thousands of noisy and randomly oriented 2D cryo-EM images. Existing methods based on coordinate-based neural networks show compelling results to model continuous conformations of 3D structures in the Fourier domain, but they suffer from a limited ability to model local flexible regions and lack interpretability. We propose a novel approach, cryoFormer, that utilizes a transformer-based network architecture for continuous heterogeneous cryo-EM reconstruction. We for the first time directly reconstruct continuous conformations of 3D structures using an implicit feature volume in the 3D spatial domain. A novel deformation transformer decoder further improves reconstruction quality and, more importantly, locates and robustly tackles flexible 3D regions caused by conformations. In experiments, our method outperforms current approaches on three public datasets (1 synthetic and 2 experimental) and a new synthetic dataset of PEDV spike protein. The code and new synthetic dataset will be released for better reproducibility of our results. Project page: https://cryoformer.github.io.
Human Performance Modeling and Rendering via Neural Animated Mesh
Sep 18, 2022

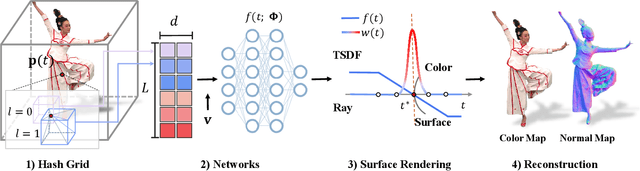
We have recently seen tremendous progress in the neural advances for photo-real human modeling and rendering. However, it's still challenging to integrate them into an existing mesh-based pipeline for downstream applications. In this paper, we present a comprehensive neural approach for high-quality reconstruction, compression, and rendering of human performances from dense multi-view videos. Our core intuition is to bridge the traditional animated mesh workflow with a new class of highly efficient neural techniques. We first introduce a neural surface reconstructor for high-quality surface generation in minutes. It marries the implicit volumetric rendering of the truncated signed distance field (TSDF) with multi-resolution hash encoding. We further propose a hybrid neural tracker to generate animated meshes, which combines explicit non-rigid tracking with implicit dynamic deformation in a self-supervised framework. The former provides the coarse warping back into the canonical space, while the latter implicit one further predicts the displacements using the 4D hash encoding as in our reconstructor. Then, we discuss the rendering schemes using the obtained animated meshes, ranging from dynamic texturing to lumigraph rendering under various bandwidth settings. To strike an intricate balance between quality and bandwidth, we propose a hierarchical solution by first rendering 6 virtual views covering the performer and then conducting occlusion-aware neural texture blending. We demonstrate the efficacy of our approach in a variety of mesh-based applications and photo-realistic free-view experiences on various platforms, i.e., inserting virtual human performances into real environments through mobile AR or immersively watching talent shows with VR headsets.
Fourier PlenOctrees for Dynamic Radiance Field Rendering in Real-time
Feb 22, 2022
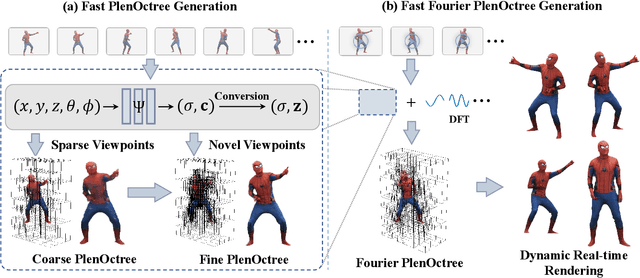

Implicit neural representations such as Neural Radiance Field (NeRF) have focused mainly on modeling static objects captured under multi-view settings where real-time rendering can be achieved with smart data structures, e.g., PlenOctree. In this paper, we present a novel Fourier PlenOctree (FPO) technique to tackle efficient neural modeling and real-time rendering of dynamic scenes captured under the free-view video (FVV) setting. The key idea in our FPO is a novel combination of generalized NeRF, PlenOctree representation, volumetric fusion and Fourier transform. To accelerate FPO construction, we present a novel coarse-to-fine fusion scheme that leverages the generalizable NeRF technique to generate the tree via spatial blending. To tackle dynamic scenes, we tailor the implicit network to model the Fourier coefficients of timevarying density and color attributes. Finally, we construct the FPO and train the Fourier coefficients directly on the leaves of a union PlenOctree structure of the dynamic sequence. We show that the resulting FPO enables compact memory overload to handle dynamic objects and supports efficient fine-tuning. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF and achieves over an order of magnitude acceleration over SOTA while preserving high visual quality for the free-viewpoint rendering of unseen dynamic scenes.
NeuVV: Neural Volumetric Videos with Immersive Rendering and Editing
Feb 12, 2022



Some of the most exciting experiences that Metaverse promises to offer, for instance, live interactions with virtual characters in virtual environments, require real-time photo-realistic rendering. 3D reconstruction approaches to rendering, active or passive, still require extensive cleanup work to fix the meshes or point clouds. In this paper, we present a neural volumography technique called neural volumetric video or NeuVV to support immersive, interactive, and spatial-temporal rendering of volumetric video contents with photo-realism and in real-time. The core of NeuVV is to efficiently encode a dynamic neural radiance field (NeRF) into renderable and editable primitives. We introduce two types of factorization schemes: a hyper-spherical harmonics (HH) decomposition for modeling smooth color variations over space and time and a learnable basis representation for modeling abrupt density and color changes caused by motion. NeuVV factorization can be integrated into a Video Octree (VOctree) analogous to PlenOctree to significantly accelerate training while reducing memory overhead. Real-time NeuVV rendering further enables a class of immersive content editing tools. Specifically, NeuVV treats each VOctree as a primitive and implements volume-based depth ordering and alpha blending to realize spatial-temporal compositions for content re-purposing. For example, we demonstrate positioning varied manifestations of the same performance at different 3D locations with different timing, adjusting color/texture of the performer's clothing, casting spotlight shadows and synthesizing distance falloff lighting, etc, all at an interactive speed. We further develop a hybrid neural-rasterization rendering framework to support consumer-level VR headsets so that the aforementioned volumetric video viewing and editing, for the first time, can be conducted immersively in virtual 3D space.
HumanNeRF: Generalizable Neural Human Radiance Field from Sparse Inputs
Dec 15, 2021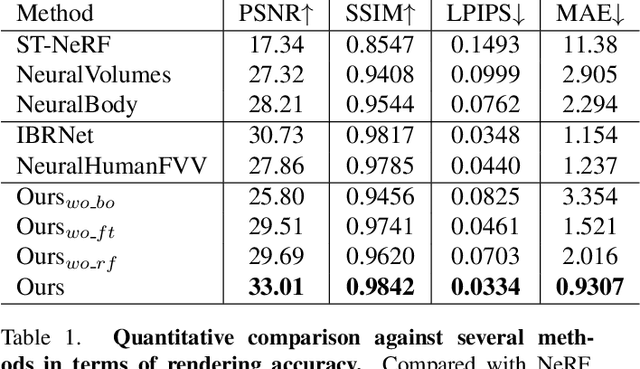

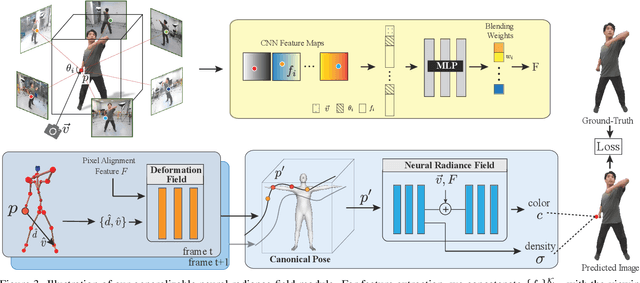

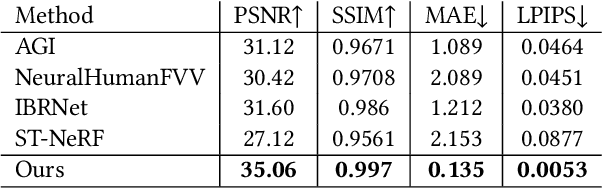
Recent neural human representations can produce high-quality multi-view rendering but require using dense multi-view inputs and costly training. They are hence largely limited to static models as training each frame is infeasible. We present HumanNeRF - a generalizable neural representation - for high-fidelity free-view synthesis of dynamic humans. Analogous to how IBRNet assists NeRF by avoiding per-scene training, HumanNeRF employs an aggregated pixel-alignment feature across multi-view inputs along with a pose embedded non-rigid deformation field for tackling dynamic motions. The raw HumanNeRF can already produce reasonable rendering on sparse video inputs of unseen subjects and camera settings. To further improve the rendering quality, we augment our solution with an appearance blending module for combining the benefits of both neural volumetric rendering and neural texture blending. Extensive experiments on various multi-view dynamic human datasets demonstrate the generalizability and effectiveness of our approach in synthesizing photo-realistic free-view humans under challenging motions and with very sparse camera view inputs.
Editable Free-viewpoint Video Using a Layered Neural Representation
Apr 30, 2021
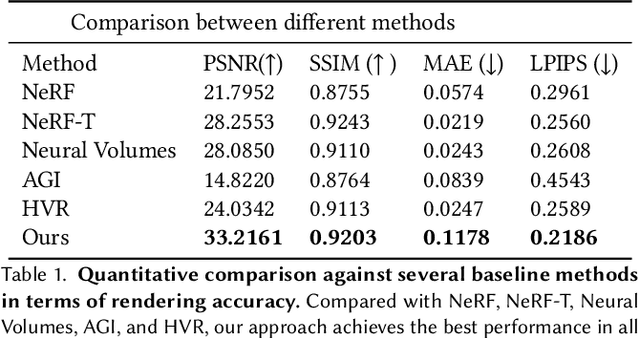
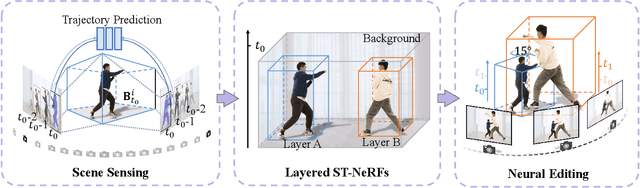
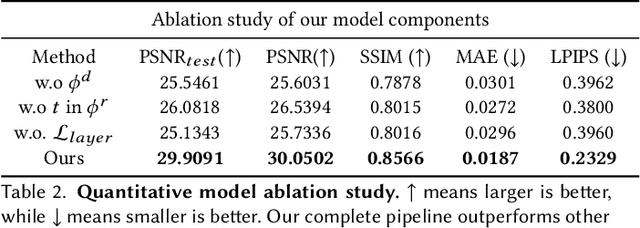
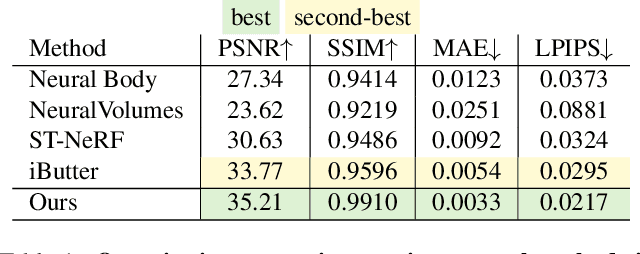
Generating free-viewpoint videos is critical for immersive VR/AR experience but recent neural advances still lack the editing ability to manipulate the visual perception for large dynamic scenes. To fill this gap, in this paper we propose the first approach for editable photo-realistic free-viewpoint video generation for large-scale dynamic scenes using only sparse 16 cameras. The core of our approach is a new layered neural representation, where each dynamic entity including the environment itself is formulated into a space-time coherent neural layered radiance representation called ST-NeRF. Such layered representation supports fully perception and realistic manipulation of the dynamic scene whilst still supporting a free viewing experience in a wide range. In our ST-NeRF, the dynamic entity/layer is represented as continuous functions, which achieves the disentanglement of location, deformation as well as the appearance of the dynamic entity in a continuous and self-supervised manner. We propose a scene parsing 4D label map tracking to disentangle the spatial information explicitly, and a continuous deform module to disentangle the temporal motion implicitly. An object-aware volume rendering scheme is further introduced for the re-assembling of all the neural layers. We adopt a novel layered loss and motion-aware ray sampling strategy to enable efficient training for a large dynamic scene with multiple performers, Our framework further enables a variety of editing functions, i.e., manipulating the scale and location, duplicating or retiming individual neural layers to create numerous visual effects while preserving high realism. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality, photo-realistic, and editable free-viewpoint video generation for dynamic scenes.