 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirector: Instance-aware Gaussian Splatting for Dynamic Scene Modeling and Understanding
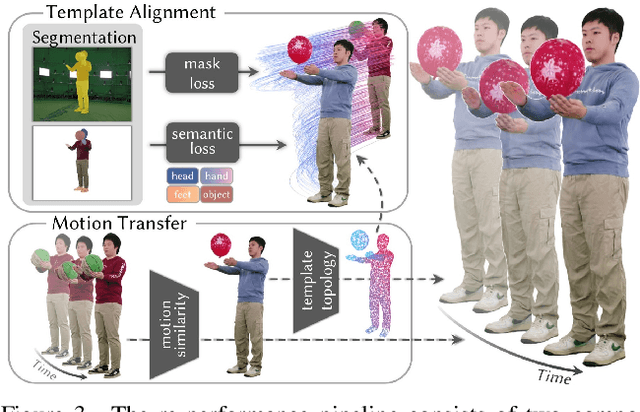
Apr 02, 2026Volumetric video seeks to model dynamic scenes as temporally coherent 4D representations. While recent Gaussian-based approaches achieve impressive rendering fidelity, they primarily emphasize appearance but are largely agnostic to instance-level structure, limiting stable tracking and semantic reasoning in highly dynamic scenarios. In this paper, we present Director, a unified spatio-temporal Gaussian representation that jointly models human performance, high-fidelity rendering, and instance-level semantics. Our key insight is that embedding instance-consistent semantics naturally complements 4D modeling, enabling more accurate scene decomposition while supporting robust dynamic scene understanding. To this end, we leverage temporally aligned instance masks and sentence embeddings derived from Multimodal Large Language Models to supervise the learnable semantic features of each Gaussian via two MLP decoders, enabling language-aligned 4D representations and enforcing identity consistency over time. To enhance temporal stability, we bridge 2D optical flow with 4D Gaussians and finetune their motions, yielding reliable initialization and reducing drift. For the training, we further introduce a geometry-aware SDF constraints, along with regularization terms that enforces surface continuity, enhancing temporal coherence in dynamic foreground modeling. Experiments demonstrate that Director achieves temporally coherent 4D reconstructions while simultaneously enabling instance segmentation and open-vocabulary querying.
RePerformer: Immersive Human-centric Volumetric Videos from Playback to Photoreal Reperformance
Mar 15, 2025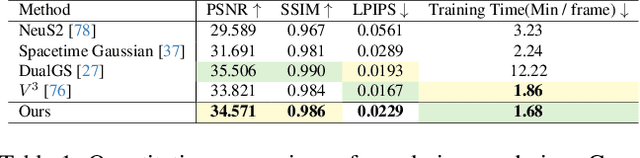
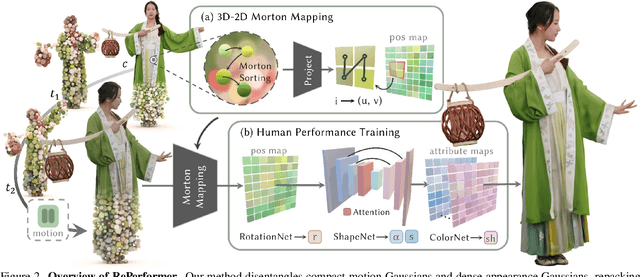
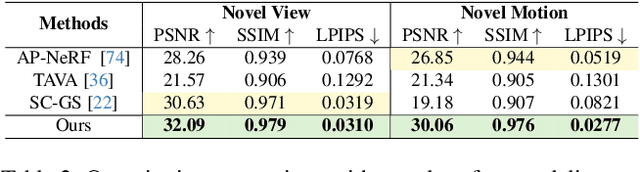
Human-centric volumetric videos offer immersive free-viewpoint experiences, yet existing methods focus either on replaying general dynamic scenes or animating human avatars, limiting their ability to re-perform general dynamic scenes. In this paper, we present RePerformer, a novel Gaussian-based representation that unifies playback and re-performance for high-fidelity human-centric volumetric videos. Specifically, we hierarchically disentangle the dynamic scenes into motion Gaussians and appearance Gaussians which are associated in the canonical space. We further employ a Morton-based parameterization to efficiently encode the appearance Gaussians into 2D position and attribute maps. For enhanced generalization, we adopt 2D CNNs to map position maps to attribute maps, which can be assembled into appearance Gaussians for high-fidelity rendering of the dynamic scenes. For re-performance, we develop a semantic-aware alignment module and apply deformation transfer on motion Gaussians, enabling photo-real rendering under novel motions. Extensive experiments validate the robustness and effectiveness of RePerformer, setting a new benchmark for playback-then-reperformance paradigm in human-centric volumetric videos.
BEAM: Bridging Physically-based Rendering and Gaussian Modeling for Relightable Volumetric Video
Feb 12, 2025Volumetric video enables immersive experiences by capturing dynamic 3D scenes, enabling diverse applications for virtual reality, education, and telepresence. However, traditional methods struggle with fixed lighting conditions, while neural approaches face trade-offs in efficiency, quality, or adaptability for relightable scenarios. To address these limitations, we present BEAM, a novel pipeline that bridges 4D Gaussian representations with physically-based rendering (PBR) to produce high-quality, relightable volumetric videos from multi-view RGB footage. BEAM recovers detailed geometry and PBR properties via a series of available Gaussian-based techniques. It first combines Gaussian-based performance tracking with geometry-aware rasterization in a coarse-to-fine optimization framework to recover spatially and temporally consistent geometries. We further enhance Gaussian attributes by incorporating PBR properties step by step. We generate roughness via a multi-view-conditioned diffusion model, and then derive AO and base color using a 2D-to-3D strategy, incorporating a tailored Gaussian-based ray tracer for efficient visibility computation. Once recovered, these dynamic, relightable assets integrate seamlessly into traditional CG pipelines, supporting real-time rendering with deferred shading and offline rendering with ray tracing. By offering realistic, lifelike visualizations under diverse lighting conditions, BEAM opens new possibilities for interactive entertainment, storytelling, and creative visualization.
Robust Dual Gaussian Splatting for Immersive Human-centric Volumetric Videos
Sep 12, 2024Volumetric video represents a transformative advancement in visual media, enabling users to freely navigate immersive virtual experiences and narrowing the gap between digital and real worlds. However, the need for extensive manual intervention to stabilize mesh sequences and the generation of excessively large assets in existing workflows impedes broader adoption. In this paper, we present a novel Gaussian-based approach, dubbed \textit{DualGS}, for real-time and high-fidelity playback of complex human performance with excellent compression ratios. Our key idea in DualGS is to separately represent motion and appearance using the corresponding skin and joint Gaussians. Such an explicit disentanglement can significantly reduce motion redundancy and enhance temporal coherence. We begin by initializing the DualGS and anchoring skin Gaussians to joint Gaussians at the first frame. Subsequently, we employ a coarse-to-fine training strategy for frame-by-frame human performance modeling. It includes a coarse alignment phase for overall motion prediction as well as a fine-grained optimization for robust tracking and high-fidelity rendering. To integrate volumetric video seamlessly into VR environments, we efficiently compress motion using entropy encoding and appearance using codec compression coupled with a persistent codebook. Our approach achieves a compression ratio of up to 120 times, only requiring approximately 350KB of storage per frame. We demonstrate the efficacy of our representation through photo-realistic, free-view experiences on VR headsets, enabling users to immersively watch musicians in performance and feel the rhythm of the notes at the performers' fingertips.
HiFi4G: High-Fidelity Human Performance Rendering via Compact Gaussian Splatting
Dec 07, 2023



We have recently seen tremendous progress in photo-real human modeling and rendering. Yet, efficiently rendering realistic human performance and integrating it into the rasterization pipeline remains challenging. In this paper, we present HiFi4G, an explicit and compact Gaussian-based approach for high-fidelity human performance rendering from dense footage. Our core intuition is to marry the 3D Gaussian representation with non-rigid tracking, achieving a compact and compression-friendly representation. We first propose a dual-graph mechanism to obtain motion priors, with a coarse deformation graph for effective initialization and a fine-grained Gaussian graph to enforce subsequent constraints. Then, we utilize a 4D Gaussian optimization scheme with adaptive spatial-temporal regularizers to effectively balance the non-rigid prior and Gaussian updating. We also present a companion compression scheme with residual compensation for immersive experiences on various platforms. It achieves a substantial compression rate of approximately 25 times, with less than 2MB of storage per frame. Extensive experiments demonstrate the effectiveness of our approach, which significantly outperforms existing approaches in terms of optimization speed, rendering quality, and storage overhead.
Instant-NVR: Instant Neural Volumetric Rendering for Human-object Interactions from Monocular RGBD Stream
Apr 06, 2023Convenient 4D modeling of human-object interactions is essential for numerous applications. However, monocular tracking and rendering of complex interaction scenarios remain challenging. In this paper, we propose Instant-NVR, a neural approach for instant volumetric human-object tracking and rendering using a single RGBD camera. It bridges traditional non-rigid tracking with recent instant radiance field techniques via a multi-thread tracking-rendering mechanism. In the tracking front-end, we adopt a robust human-object capture scheme to provide sufficient motion priors. We further introduce a separated instant neural representation with a novel hybrid deformation module for the interacting scene. We also provide an on-the-fly reconstruction scheme of the dynamic/static radiance fields via efficient motion-prior searching. Moreover, we introduce an online key frame selection scheme and a rendering-aware refinement strategy to significantly improve the appearance details for online novel-view synthesis. Extensive experiments demonstrate the effectiveness and efficiency of our approach for the instant generation of human-object radiance fields on the fly, notably achieving real-time photo-realistic novel view synthesis under complex human-object interactions.
Human Performance Modeling and Rendering via Neural Animated Mesh
Sep 18, 2022

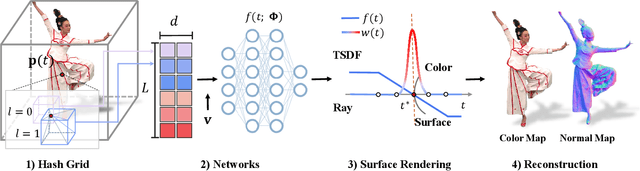
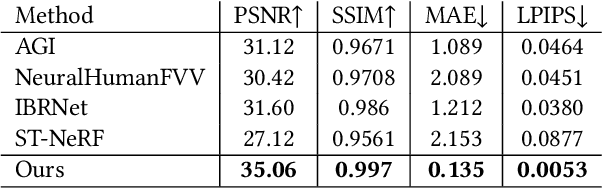
We have recently seen tremendous progress in the neural advances for photo-real human modeling and rendering. However, it's still challenging to integrate them into an existing mesh-based pipeline for downstream applications. In this paper, we present a comprehensive neural approach for high-quality reconstruction, compression, and rendering of human performances from dense multi-view videos. Our core intuition is to bridge the traditional animated mesh workflow with a new class of highly efficient neural techniques. We first introduce a neural surface reconstructor for high-quality surface generation in minutes. It marries the implicit volumetric rendering of the truncated signed distance field (TSDF) with multi-resolution hash encoding. We further propose a hybrid neural tracker to generate animated meshes, which combines explicit non-rigid tracking with implicit dynamic deformation in a self-supervised framework. The former provides the coarse warping back into the canonical space, while the latter implicit one further predicts the displacements using the 4D hash encoding as in our reconstructor. Then, we discuss the rendering schemes using the obtained animated meshes, ranging from dynamic texturing to lumigraph rendering under various bandwidth settings. To strike an intricate balance between quality and bandwidth, we propose a hierarchical solution by first rendering 6 virtual views covering the performer and then conducting occlusion-aware neural texture blending. We demonstrate the efficacy of our approach in a variety of mesh-based applications and photo-realistic free-view experiences on various platforms, i.e., inserting virtual human performances into real environments through mobile AR or immersively watching talent shows with VR headsets.
NeuralHOFusion: Neural Volumetric Rendering under Human-object Interactions
Mar 28, 2022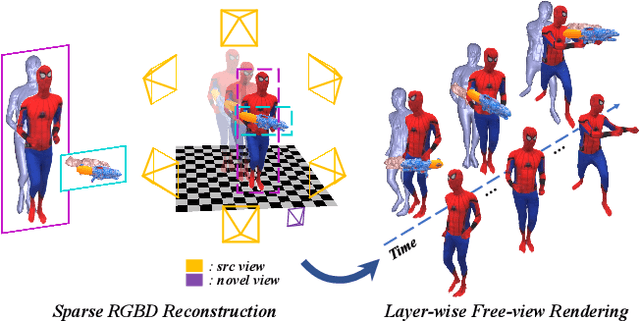
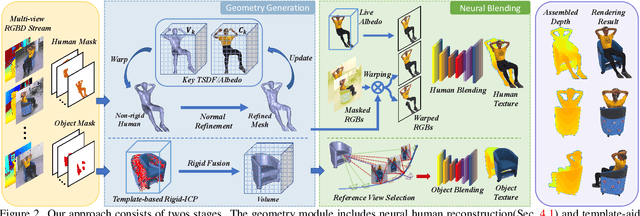
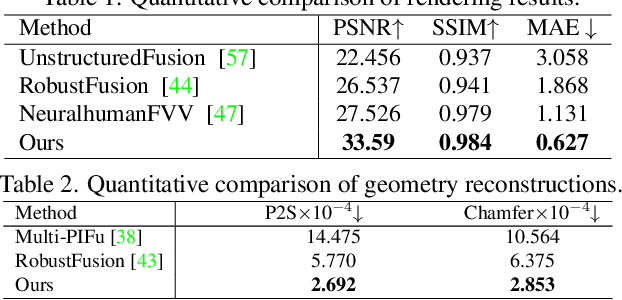
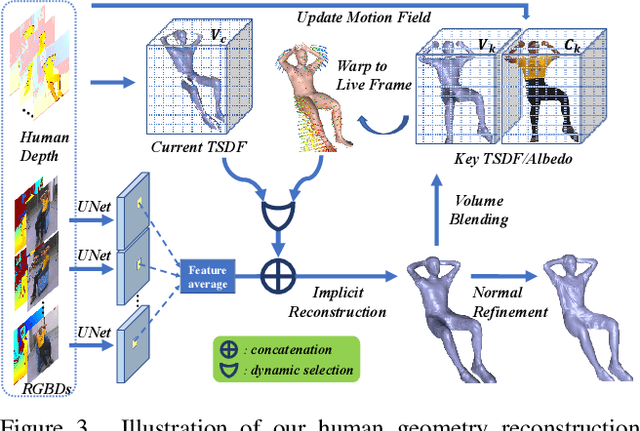
4D modeling of human-object interactions is critical for numerous applications. However, efficient volumetric capture and rendering of complex interaction scenarios, especially from sparse inputs, remain challenging. In this paper, we propose NeuralHOFusion, a neural approach for volumetric human-object capture and rendering using sparse consumer RGBD sensors. It marries traditional non-rigid fusion with recent neural implicit modeling and blending advances, where the captured humans and objects are layerwise disentangled. For geometry modeling, we propose a neural implicit inference scheme with non-rigid key-volume fusion, as well as a template-aid robust object tracking pipeline. Our scheme enables detailed and complete geometry generation under complex interactions and occlusions. Moreover, we introduce a layer-wise human-object texture rendering scheme, which combines volumetric and image-based rendering in both spatial and temporal domains to obtain photo-realistic results. Extensive experiments demonstrate the effectiveness and efficiency of our approach in synthesizing photo-realistic free-view results under complex human-object interactions.
Artemis: Articulated Neural Pets with Appearance and Motion synthesis
Feb 11, 2022
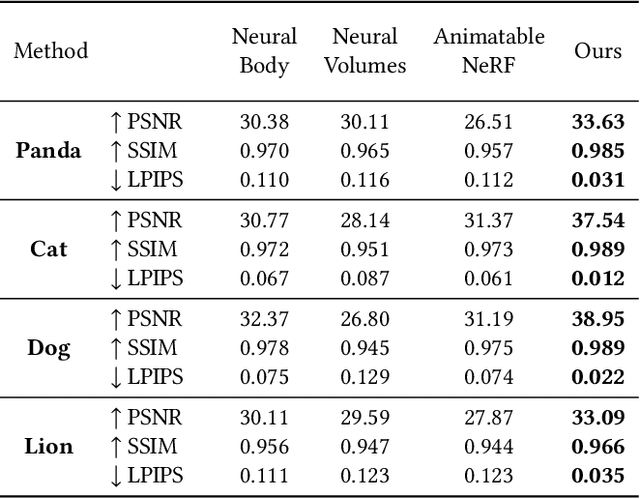
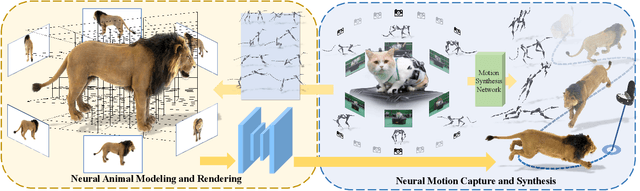
We human are entering into a virtual era, and surely want to bring animals to virtual world as well for companion. Yet, computer-generated (CGI) furry animals is limited by tedious off-line rendering, let alone interactive motion control. In this paper, we present ARTEMIS, a novel neural modeling and rendering pipeline for generating ARTiculated neural pets with appEarance and Motion synthesIS. Our ARTEMIS enables interactive motion control, real-time animation and photo-realistic rendering of furry animals. The core of ARTEMIS is a neural-generated (NGI) animal engine, which adopts an efficient octree based representation for animal animation and fur rendering. The animation then becomes equivalent to voxel level skeleton based deformation. We further use a fast octree indexing, an efficient volumetric rendering scheme to generate appearance and density features maps. Finally, we propose a novel shading network to generate high-fidelity details of appearance and opacity under novel poses. For the motion control module in ARTEMIS, we combine state-of-the-art animal motion capture approach with neural character control scheme. We introduce an effective optimization scheme to reconstruct skeletal motion of real animals captured by a multi-view RGB and Vicon camera array. We feed the captured motion into a neural character control scheme to generate abstract control signals with motion styles. We further integrate ARTEMIS into existing engines that support VR headsets, providing an unprecedented immersive experience where a user can intimately interact with a variety of virtual animals with vivid movements and photo-realistic appearance. Extensive experiments and showcases demonstrate the effectiveness of our ARTEMIS system to achieve highly realistic rendering of NGI animals in real-time, providing daily immersive and interactive experience with digital animals unseen before.
iButter: Neural Interactive Bullet Time Generator for Human Free-viewpoint Rendering
Aug 12, 2021
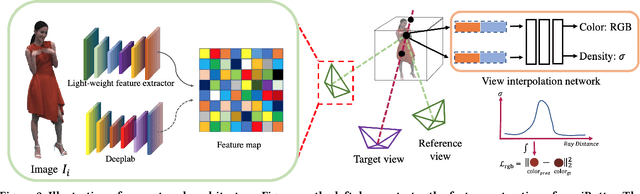
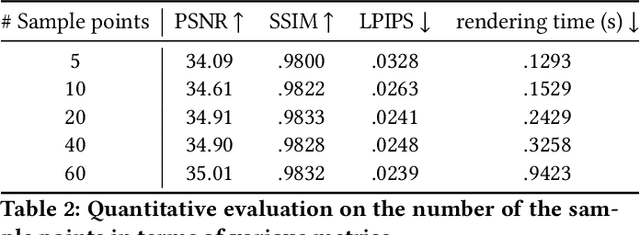
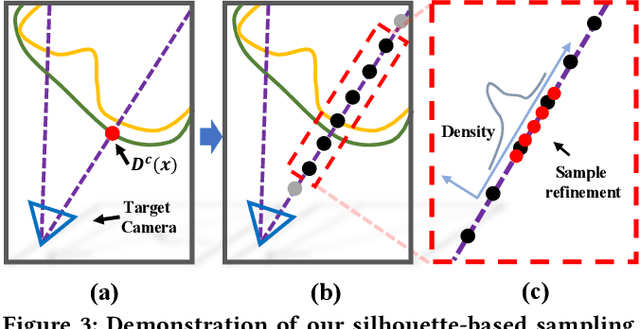
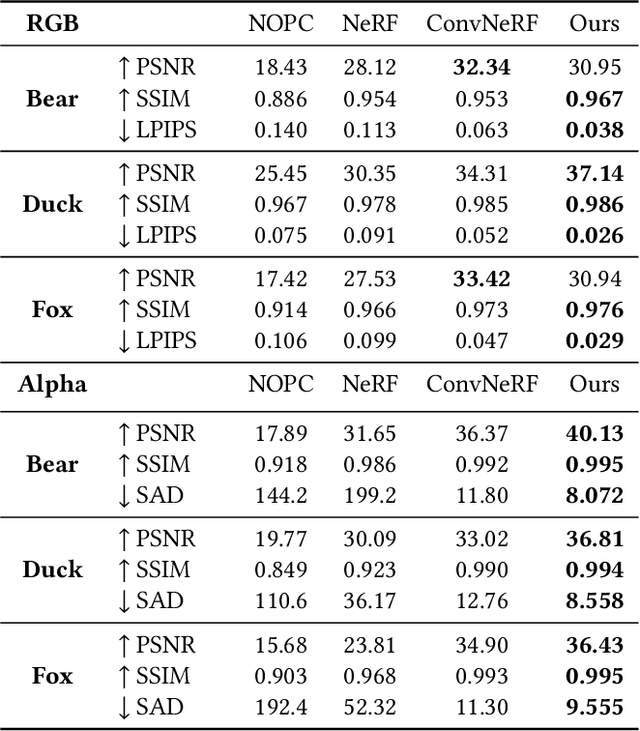
Generating ``bullet-time'' effects of human free-viewpoint videos is critical for immersive visual effects and VR/AR experience. Recent neural advances still lack the controllable and interactive bullet-time design ability for human free-viewpoint rendering, especially under the real-time, dynamic and general setting for our trajectory-aware task. To fill this gap, in this paper we propose a neural interactive bullet-time generator (iButter) for photo-realistic human free-viewpoint rendering from dense RGB streams, which enables flexible and interactive design for human bullet-time visual effects. Our iButter approach consists of a real-time preview and design stage as well as a trajectory-aware refinement stage. During preview, we propose an interactive bullet-time design approach by extending the NeRF rendering to a real-time and dynamic setting and getting rid of the tedious per-scene training. To this end, our bullet-time design stage utilizes a hybrid training set, light-weight network design and an efficient silhouette-based sampling strategy. During refinement, we introduce an efficient trajectory-aware scheme within 20 minutes, which jointly encodes the spatial, temporal consistency and semantic cues along the designed trajectory, achieving photo-realistic bullet-time viewing experience of human activities. Extensive experiments demonstrate the effectiveness of our approach for convenient interactive bullet-time design and photo-realistic human free-viewpoint video generation.