 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianHair: Hair Modeling and Rendering with Light-aware Gaussians
Feb 16, 2024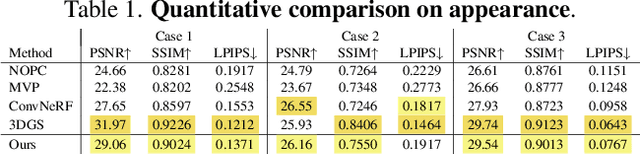

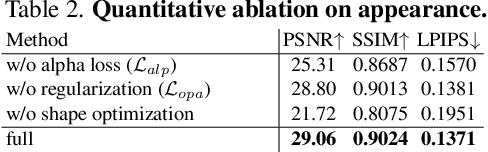

Hairstyle reflects culture and ethnicity at first glance. In the digital era, various realistic human hairstyles are also critical to high-fidelity digital human assets for beauty and inclusivity. Yet, realistic hair modeling and real-time rendering for animation is a formidable challenge due to its sheer number of strands, complicated structures of geometry, and sophisticated interaction with light. This paper presents GaussianHair, a novel explicit hair representation. It enables comprehensive modeling of hair geometry and appearance from images, fostering innovative illumination effects and dynamic animation capabilities. At the heart of GaussianHair is the novel concept of representing each hair strand as a sequence of connected cylindrical 3D Gaussian primitives. This approach not only retains the hair's geometric structure and appearance but also allows for efficient rasterization onto a 2D image plane, facilitating differentiable volumetric rendering. We further enhance this model with the "GaussianHair Scattering Model", adept at recreating the slender structure of hair strands and accurately capturing their local diffuse color in uniform lighting. Through extensive experiments, we substantiate that GaussianHair achieves breakthroughs in both geometric and appearance fidelity, transcending the limitations encountered in state-of-the-art methods for hair reconstruction. Beyond representation, GaussianHair extends to support editing, relighting, and dynamic rendering of hair, offering seamless integration with conventional CG pipeline workflows. Complementing these advancements, we have compiled an extensive dataset of real human hair, each with meticulously detailed strand geometry, to propel further research in this field.
MVHuman: Tailoring 2D Diffusion with Multi-view Sampling For Realistic 3D Human Generation
Dec 15, 2023Recent months have witnessed rapid progress in 3D generation based on diffusion models. Most advances require fine-tuning existing 2D Stable Diffsuions into multi-view settings or tedious distilling operations and hence fall short of 3D human generation due to the lack of diverse 3D human datasets. We present an alternative scheme named MVHuman to generate human radiance fields from text guidance, with consistent multi-view images directly sampled from pre-trained Stable Diffsuions without any fine-tuning or distilling. Our core is a multi-view sampling strategy to tailor the denoising processes of the pre-trained network for generating consistent multi-view images. It encompasses view-consistent conditioning, replacing the original noises with ``consistency-guided noises'', optimizing latent codes, as well as utilizing cross-view attention layers. With the multi-view images through the sampling process, we adopt geometry refinement and 3D radiance field generation followed by a subsequent neural blending scheme for free-view rendering. Extensive experiments demonstrate the efficacy of our method, as well as its superiority to state-of-the-art 3D human generation methods.
HumanGen: Generating Human Radiance Fields with Explicit Priors
Dec 10, 2022



Recent years have witnessed the tremendous progress of 3D GANs for generating view-consistent radiance fields with photo-realism. Yet, high-quality generation of human radiance fields remains challenging, partially due to the limited human-related priors adopted in existing methods. We present HumanGen, a novel 3D human generation scheme with detailed geometry and $\text{360}^{\circ}$ realistic free-view rendering. It explicitly marries the 3D human generation with various priors from the 2D generator and 3D reconstructor of humans through the design of "anchor image". We introduce a hybrid feature representation using the anchor image to bridge the latent space of HumanGen with the existing 2D generator. We then adopt a pronged design to disentangle the generation of geometry and appearance. With the aid of the anchor image, we adapt a 3D reconstructor for fine-grained details synthesis and propose a two-stage blending scheme to boost appearance generation. Extensive experiments demonstrate our effectiveness for state-of-the-art 3D human generation regarding geometry details, texture quality, and free-view performance. Notably, HumanGen can also incorporate various off-the-shelf 2D latent editing methods, seamlessly lifting them into 3D.
NeuralHOFusion: Neural Volumetric Rendering under Human-object Interactions
Mar 28, 2022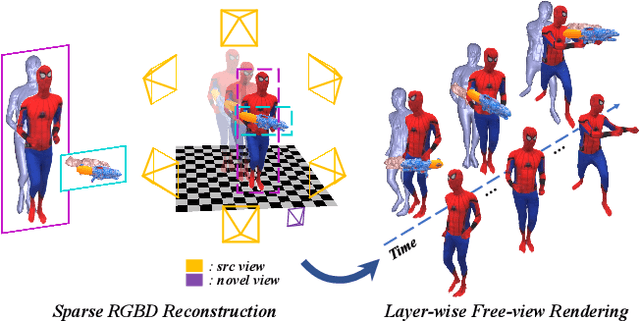
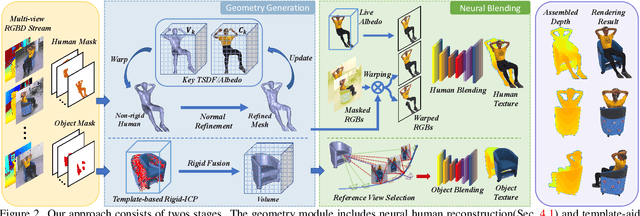
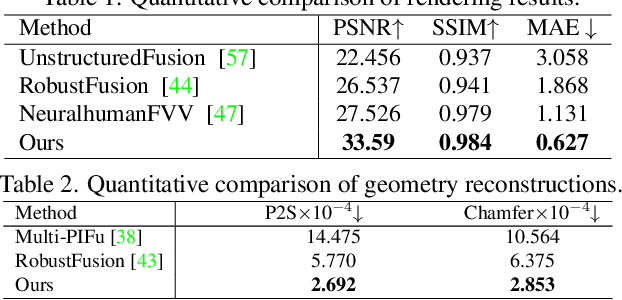
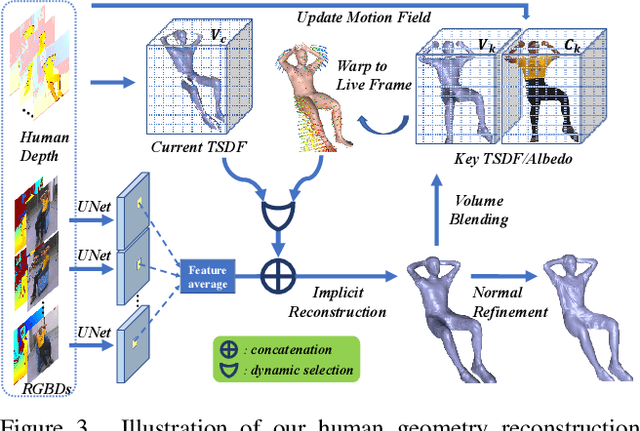
4D modeling of human-object interactions is critical for numerous applications. However, efficient volumetric capture and rendering of complex interaction scenarios, especially from sparse inputs, remain challenging. In this paper, we propose NeuralHOFusion, a neural approach for volumetric human-object capture and rendering using sparse consumer RGBD sensors. It marries traditional non-rigid fusion with recent neural implicit modeling and blending advances, where the captured humans and objects are layerwise disentangled. For geometry modeling, we propose a neural implicit inference scheme with non-rigid key-volume fusion, as well as a template-aid robust object tracking pipeline. Our scheme enables detailed and complete geometry generation under complex interactions and occlusions. Moreover, we introduce a layer-wise human-object texture rendering scheme, which combines volumetric and image-based rendering in both spatial and temporal domains to obtain photo-realistic results. Extensive experiments demonstrate the effectiveness and efficiency of our approach in synthesizing photo-realistic free-view results under complex human-object interactions.