 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefracGS: Novel View Synthesis Through Refractive Water Surfaces with 3D Gaussian Ray Tracing
Mar 23, 2026Novel view synthesis (NVS) through non-planar refractive surfaces presents fundamental challenges due to severe, spatially varying optical distortions. While recent representations like NeRF and 3D Gaussian Splatting (3DGS) excel at NVS, their assumption of straight-line ray propagation fails under these conditions, leading to significant artifacts. To overcome this limitation, we introduce RefracGS, a framework that jointly reconstructs the refractive water surface and the scene beneath the interface. Our key insight is to explicitly decouple the refractive boundary from the target objects: the refractive surface is modeled via a neural height field, capturing wave geometry, while the underlying scene is represented as a 3D Gaussian field. We formulate a refraction-aware Gaussian ray tracing approach that accurately computes non-linear ray trajectories using Snell's law and efficiently renders the underlying Gaussian field while backpropagating the loss gradients to the parameterized refractive surface. Through end-to-end joint optimization of both representations, our method ensures high-fidelity NVS and view-consistent surface recovery. Experiments on both synthetic and real-world scenes with complex waves demonstrate that RefracGS outperforms prior refractive methods in visual quality, while achieving 15x faster training and real-time rendering at 200 FPS. The project page for RefracGS is available at https://yimgshao.github.io/refracgs/.
Recovering 3D Shapes from Ultra-Fast Motion-Blurred Images
Feb 08, 2026We consider the problem of 3D shape recovery from ultra-fast motion-blurred images. While 3D reconstruction from static images has been extensively studied, recovering geometry from extreme motion-blurred images remains challenging. Such scenarios frequently occur in both natural and industrial settings, such as fast-moving objects in sports (e.g., balls) or rotating machinery, where rapid motion distorts object appearance and makes traditional 3D reconstruction techniques like Multi-View Stereo (MVS) ineffective. In this paper, we propose a novel inverse rendering approach for shape recovery from ultra-fast motion-blurred images. While conventional rendering techniques typically synthesize blur by averaging across multiple frames, we identify a major computational bottleneck in the repeated computation of barycentric weights. To address this, we propose a fast barycentric coordinate solver, which significantly reduces computational overhead and achieves a speedup of up to 4.57x, enabling efficient and photorealistic simulation of high-speed motion. Crucially, our method is fully differentiable, allowing gradients to propagate from rendered images to the underlying 3D shape, thereby facilitating shape recovery through inverse rendering. We validate our approach on two representative motion types: rapid translation and rotation. Experimental results demonstrate that our method enables efficient and realistic modeling of ultra-fast moving objects in the forward simulation. Moreover, it successfully recovers 3D shapes from 2D imagery of objects undergoing extreme translational and rotational motion, advancing the boundaries of vision-based 3D reconstruction. Project page: https://maxmilite.github.io/rec-from-ultrafast-blur/
Robust Single-shot Structured Light 3D Imaging via Neural Feature Decoding
Dec 16, 2025We consider the problem of active 3D imaging using single-shot structured light systems, which are widely employed in commercial 3D sensing devices such as Apple Face ID and Intel RealSense. Traditional structured light methods typically decode depth correspondences through pixel-domain matching algorithms, resulting in limited robustness under challenging scenarios like occlusions, fine-structured details, and non-Lambertian surfaces. Inspired by recent advances in neural feature matching, we propose a learning-based structured light decoding framework that performs robust correspondence matching within feature space rather than the fragile pixel domain. Our method extracts neural features from the projected patterns and captured infrared (IR) images, explicitly incorporating their geometric priors by building cost volumes in feature space, achieving substantial performance improvements over pixel-domain decoding approaches. To further enhance depth quality, we introduce a depth refinement module that leverages strong priors from large-scale monocular depth estimation models, improving fine detail recovery and global structural coherence. To facilitate effective learning, we develop a physically-based structured light rendering pipeline, generating nearly one million synthetic pattern-image pairs with diverse objects and materials for indoor settings. Experiments demonstrate that our method, trained exclusively on synthetic data with multiple structured light patterns, generalizes well to real-world indoor environments, effectively processes various pattern types without retraining, and consistently outperforms both commercial structured light systems and passive stereo RGB-based depth estimation methods. Project page: https://namisntimpot.github.io/NSLweb/.
From Orbit to Ground: Generative City Photogrammetry from Extreme Off-Nadir Satellite Images
Dec 09, 2025City-scale 3D reconstruction from satellite imagery presents the challenge of extreme viewpoint extrapolation, where our goal is to synthesize ground-level novel views from sparse orbital images with minimal parallax. This requires inferring nearly $90^\circ$ viewpoint gaps from image sources with severely foreshortened facades and flawed textures, causing state-of-the-art reconstruction engines such as NeRF and 3DGS to fail. To address this problem, we propose two design choices tailored for city structures and satellite inputs. First, we model city geometry as a 2.5D height map, implemented as a Z-monotonic signed distance field (SDF) that matches urban building layouts from top-down viewpoints. This stabilizes geometry optimization under sparse, off-nadir satellite views and yields a watertight mesh with crisp roofs and clean, vertically extruded facades. Second, we paint the mesh appearance from satellite images via differentiable rendering techniques. While the satellite inputs may contain long-range, blurry captures, we further train a generative texture restoration network to enhance the appearance, recovering high-frequency, plausible texture details from degraded inputs. Our method's scalability and robustness are demonstrated through extensive experiments on large-scale urban reconstruction. For example, in our teaser figure, we reconstruct a $4\,\mathrm{km}^2$ real-world region from only a few satellite images, achieving state-of-the-art performance in synthesizing photorealistic ground views. The resulting models are not only visually compelling but also serve as high-fidelity, application-ready assets for downstream tasks like urban planning and simulation. Project page can be found at https://pku-vcl-geometry.github.io/Orbit2Ground/.
InstantViR: Real-Time Video Inverse Problem Solver with Distilled Diffusion Prior
Nov 18, 2025Video inverse problems are fundamental to streaming, telepresence, and AR/VR, where high perceptual quality must coexist with tight latency constraints. Diffusion-based priors currently deliver state-of-the-art reconstructions, but existing approaches either adapt image diffusion models with ad hoc temporal regularizers - leading to temporal artifacts - or rely on native video diffusion models whose iterative posterior sampling is far too slow for real-time use. We introduce InstantViR, an amortized inference framework for ultra-fast video reconstruction powered by a pre-trained video diffusion prior. We distill a powerful bidirectional video diffusion model (teacher) into a causal autoregressive student that maps a degraded video directly to its restored version in a single forward pass, inheriting the teacher's strong temporal modeling while completely removing iterative test-time optimization. The distillation is prior-driven: it only requires the teacher diffusion model and known degradation operators, and does not rely on externally paired clean/noisy video data. To further boost throughput, we replace the video-diffusion backbone VAE with a high-efficiency LeanVAE via an innovative teacher-space regularized distillation scheme, enabling low-latency latent-space processing. Across streaming random inpainting, Gaussian deblurring and super-resolution, InstantViR matches or surpasses the reconstruction quality of diffusion-based baselines while running at over 35 FPS on NVIDIA A100 GPUs, achieving up to 100 times speedups over iterative video diffusion solvers. These results show that diffusion-based video reconstruction is compatible with real-time, interactive, editable, streaming scenarios, turning high-quality video restoration into a practical component of modern vision systems.
Let Language Constrain Geometry: Vision-Language Models as Semantic and Spatial Critics for 3D Generation
Nov 18, 2025
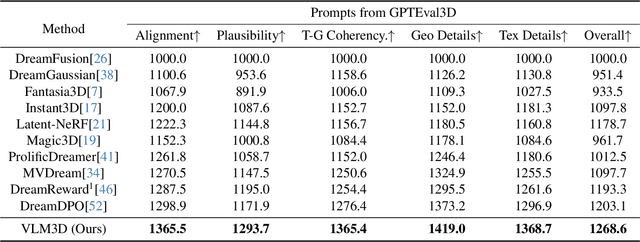
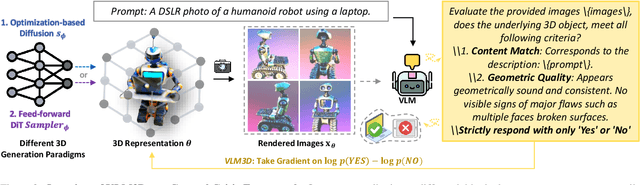
Text-to-3D generation has advanced rapidly, yet state-of-the-art models, encompassing both optimization-based and feed-forward architectures, still face two fundamental limitations. First, they struggle with coarse semantic alignment, often failing to capture fine-grained prompt details. Second, they lack robust 3D spatial understanding, leading to geometric inconsistencies and catastrophic failures in part assembly and spatial relationships. To address these challenges, we propose VLM3D, a general framework that repurposes large vision-language models (VLMs) as powerful, differentiable semantic and spatial critics. Our core contribution is a dual-query critic signal derived from the VLM's Yes or No log-odds, which assesses both semantic fidelity and geometric coherence. We demonstrate the generality of this guidance signal across two distinct paradigms: (1) As a reward objective for optimization-based pipelines, VLM3D significantly outperforms existing methods on standard benchmarks. (2) As a test-time guidance module for feed-forward pipelines, it actively steers the iterative sampling process of SOTA native 3D models to correct severe spatial errors. VLM3D establishes a principled and generalizable path to inject the VLM's rich, language-grounded understanding of both semantics and space into diverse 3D generative pipelines.
Vision-Language Models as Differentiable Semantic and Spatial Rewards for Text-to-3D Generation
Sep 19, 2025
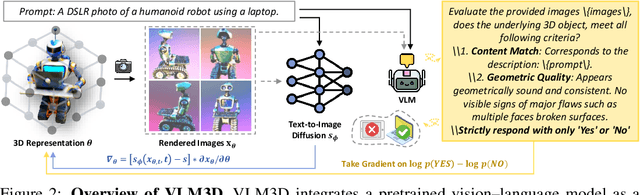


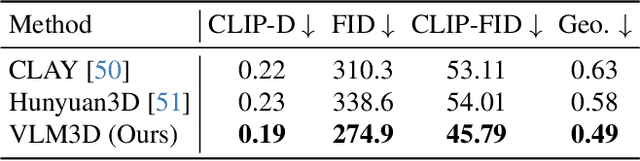
Score Distillation Sampling (SDS) enables high-quality text-to-3D generation by supervising 3D models through the denoising of multi-view 2D renderings, using a pretrained text-to-image diffusion model to align with the input prompt and ensure 3D consistency. However, existing SDS-based methods face two fundamental limitations: (1) their reliance on CLIP-style text encoders leads to coarse semantic alignment and struggles with fine-grained prompts; and (2) 2D diffusion priors lack explicit 3D spatial constraints, resulting in geometric inconsistencies and inaccurate object relationships in multi-object scenes. To address these challenges, we propose VLM3D, a novel text-to-3D generation framework that integrates large vision-language models (VLMs) into the SDS pipeline as differentiable semantic and spatial priors. Unlike standard text-to-image diffusion priors, VLMs leverage rich language-grounded supervision that enables fine-grained prompt alignment. Moreover, their inherent vision language modeling provides strong spatial understanding, which significantly enhances 3D consistency for single-object generation and improves relational reasoning in multi-object scenes. We instantiate VLM3D based on the open-source Qwen2.5-VL model and evaluate it on the GPTeval3D benchmark. Experiments across diverse objects and complex scenes show that VLM3D significantly outperforms prior SDS-based methods in semantic fidelity, geometric coherence, and spatial correctness.
Dive3D: Diverse Distillation-based Text-to-3D Generation via Score Implicit Matching
Jun 16, 2025Distilling pre-trained 2D diffusion models into 3D assets has driven remarkable advances in text-to-3D synthesis. However, existing methods typically rely on Score Distillation Sampling (SDS) loss, which involves asymmetric KL divergence--a formulation that inherently favors mode-seeking behavior and limits generation diversity. In this paper, we introduce Dive3D, a novel text-to-3D generation framework that replaces KL-based objectives with Score Implicit Matching (SIM) loss, a score-based objective that effectively mitigates mode collapse. Furthermore, Dive3D integrates both diffusion distillation and reward-guided optimization under a unified divergence perspective. Such reformulation, together with SIM loss, yields significantly more diverse 3D outputs while improving text alignment, human preference, and overall visual fidelity. We validate Dive3D across various 2D-to-3D prompts and find that it consistently outperforms prior methods in qualitative assessments, including diversity, photorealism, and aesthetic appeal. We further evaluate its performance on the GPTEval3D benchmark, comparing against nine state-of-the-art baselines. Dive3D also achieves strong results on quantitative metrics, including text-asset alignment, 3D plausibility, text-geometry consistency, texture quality, and geometric detail.
The Less You Depend, The More You Learn: Synthesizing Novel Views from Sparse, Unposed Images without Any 3D Knowledge
Jun 11, 2025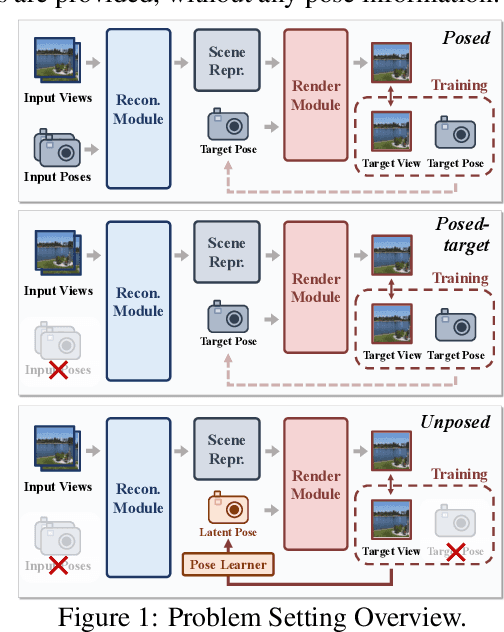
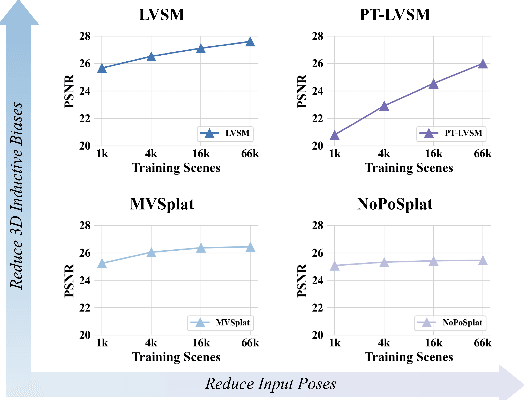
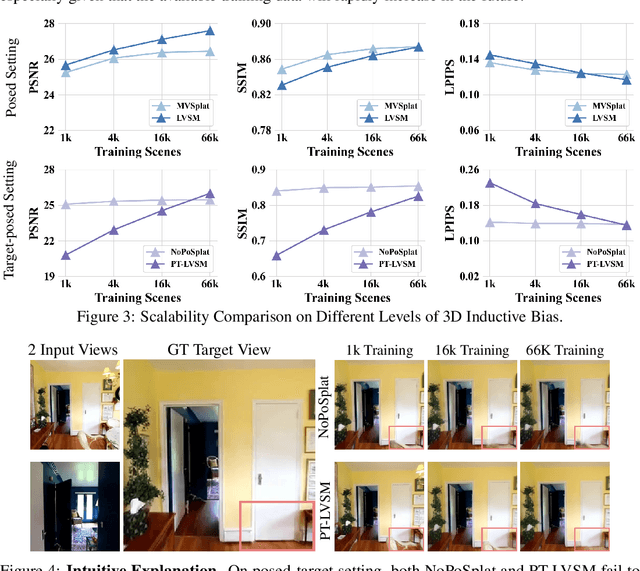
We consider the problem of generalizable novel view synthesis (NVS), which aims to generate photorealistic novel views from sparse or even unposed 2D images without per-scene optimization. This task remains fundamentally challenging, as it requires inferring 3D structure from incomplete and ambiguous 2D observations. Early approaches typically rely on strong 3D knowledge, including architectural 3D inductive biases (e.g., embedding explicit 3D representations, such as NeRF or 3DGS, into network design) and ground-truth camera poses for both input and target views. While recent efforts have sought to reduce the 3D inductive bias or the dependence on known camera poses of input views, critical questions regarding the role of 3D knowledge and the necessity of circumventing its use remain under-explored. In this work, we conduct a systematic analysis on the 3D knowledge and uncover a critical trend: the performance of methods that requires less 3D knowledge accelerates more as data scales, eventually achieving performance on par with their 3D knowledge-driven counterparts, which highlights the increasing importance of reducing dependence on 3D knowledge in the era of large-scale data. Motivated by and following this trend, we propose a novel NVS framework that minimizes 3D inductive bias and pose dependence for both input and target views. By eliminating this 3D knowledge, our method fully leverages data scaling and learns implicit 3D awareness directly from sparse 2D images, without any 3D inductive bias or pose annotation during training. Extensive experiments demonstrate that our model generates photorealistic and 3D-consistent novel views, achieving even comparable performance with methods that rely on posed inputs, thereby validating the feasibility and effectiveness of our data-centric paradigm. Project page: https://pku-vcl-geometry.github.io/Less3Depend/ .
RainyGS: Efficient Rain Synthesis with Physically-Based Gaussian Splatting
Mar 27, 2025We consider the problem of adding dynamic rain effects to in-the-wild scenes in a physically-correct manner. Recent advances in scene modeling have made significant progress, with NeRF and 3DGS techniques emerging as powerful tools for reconstructing complex scenes. However, while effective for novel view synthesis, these methods typically struggle with challenging scene editing tasks, such as physics-based rain simulation. In contrast, traditional physics-based simulations can generate realistic rain effects, such as raindrops and splashes, but they often rely on skilled artists to carefully set up high-fidelity scenes. This process lacks flexibility and scalability, limiting its applicability to broader, open-world environments. In this work, we introduce RainyGS, a novel approach that leverages the strengths of both physics-based modeling and 3DGS to generate photorealistic, dynamic rain effects in open-world scenes with physical accuracy. At the core of our method is the integration of physically-based raindrop and shallow water simulation techniques within the fast 3DGS rendering framework, enabling realistic and efficient simulations of raindrop behavior, splashes, and reflections. Our method supports synthesizing rain effects at over 30 fps, offering users flexible control over rain intensity -- from light drizzles to heavy downpours. We demonstrate that RainyGS performs effectively for both real-world outdoor scenes and large-scale driving scenarios, delivering more photorealistic and physically-accurate rain effects compared to state-of-the-art methods. Project page can be found at https://pku-vcl-geometry.github.io/RainyGS/