 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
Jun 05, 2026Open-vocabulary long-horizon manipulation requires robots to reason over flexible instructions and complex multi-object scenes while adaptively planning, executing, monitoring, and recovering from failures. We address these demands with a closed agent loop in which a VLM orchestrates heterogeneous robot capabilities as interruptible tools. Unlike in virtual AI agents, the timing of decisions, actions and tool calls is important in a physical world that does not pause for reasoning. We refer to this setting as Physical Orchestration, and propose VoLoAgent, a VLM that plans, monitors, and recovers by treating a VLA/WAM as an interruptible tool it steers mid-rollout alongside vision models and action primitives. To evaluate these long-horizon capabilities, we introduce RoboVoLo, a high-fidelity benchmark for open-vocabulary long-horizon manipulation across common sense, memory/state tracking, complex references, and world knowledge, with both task-level success and failure-mode diagnostics. Experiments show VoLoAgent substantially outperforms single VLA/VLM or tool-based systems, with validation on real-robot experiments. Project page: https://chicychen.github.io/VoLo/
On the Limits of Token Reduction for Efficient Unified Vision Language Training
May 31, 2026Unified vision-language models (VLMs) integrate visual understanding and visual generation within a single autoregressive backbone, but their joint training is computationally expensive and largely overlooked from an efficiency perspective. In this work, we study the feasibility and limits of token-reduction-based acceleration for unified VLM training. Through a systematic analysis of layerwise attention allocation, we uncover a fundamental asymmetry: visual understanding exhibits substantial late-layer visual redundancy, whereas visual generation maintains persistent dependence on image tokens across depth. Guided by this observation, we design task-specific accelerators that selectively reduce image-token computation for each objective. While these methods achieve significant efficiency gains in isolated settings, we observe a consistent synergy loss under unified training -- task-specific token dropping necessitates divergent parameter pathways and eliminates the mutual performance gains typically observed in joint optimization. Our findings suggest that efficient unified modeling requires preserving shared cross-task structures, highlighting the need for synergy-aware acceleration strategies. Project page: https://chicychen.github.io/TokenReductionUnifiedVLM/.
ForcingDAS: Unified and Robust Data Assimilation via Diffusion Forcing
May 14, 2026Data assimilation (DA) estimates the state of an evolving dynamical system from noisy, partial observations, and is widely used in scientific simulation as well as weather and climate science. In practice, filtering methods rely on frame-to-frame transition models. However, these models are fragile when observations are non-Markovian (when they form only a partial slice of a higher-dimensional latent state as in real-world weather data): they tend to accumulate errors over long horizons. At the same time, learned DA methods typically commit to a single regime, either filtering (nowcasting, real-time forecasting) or smoothing (retrospective reanalysis), which splits what should be a shared prior across application-specific pipelines. To address both issues, we introduce ForcingDAS, a unified and robust DA framework. Built on Diffusion Forcing with an independent noise level assigned to each frame, ForcingDAS learns a joint-trajectory prior instead of frame-to-frame transitions. This allows it to capture long-horizon temporal dependencies and reduce error accumulation. In addition, the same trained model spans the full filtering to smoothing spectrum at inference time. Specifically, nowcasting, fixed-lag smoothing, and batch reanalysis are selected through the inference schedule alone, without retraining. We evaluate ForcingDAS on 2D Navier-Stokes vorticity, precipitation nowcasting, and global atmospheric state estimation. Across all settings, a single model is competitive with or outperforms both learned and classical baselines that are specialized for individual regimes, with the largest gains observed on real-world weather benchmarks.
LychSim: A Controllable and Interactive Simulation Framework for Vision Research
May 12, 2026While self-supervised pretraining has reduced vision systems' reliance on synthetic data, simulation remains an indispensable tool for closed-loop optimization and rigorous out-of-distribution (OOD) evaluation. However, modern simulation platforms often present steep technical barriers, requiring extensive expertise in computer graphics and game development. In this work, we present LychSim, a highly controllable and interactive simulation framework built upon Unreal Engine 5 to bridge this gap. LychSim is built around three key designs: (1) a streamlined Python API that abstracts away underlying engine complexities; (2) a procedural data pipeline capable of generating diverse, high-fidelity environments with varying out-of-distribution (OOD) visual challenges, paired with rich 2D and 3D ground truths; and (3) a native integration of the Model Context Protocol (MCP) that transforms the simulator into a dynamic, closed-loop playground for reasoning agentic LLMs. We further annotate scene-level procedural rules and object-level pose alignments to enable semantically aligned 3D ground truths and automated scene modification. We demonstrate LychSim's capability across multiple downstream applications, including serving as a synthetic data engine, powering reinforcement learning-based adversarial examiners, and facilitating interactive, language-driven scene layout generation. To benefit the broader vision community, LychSim will be made publicly available, including full source code and various data annotations.
PhysSFI-Net: Physics-informed Geometric Learning of Skeletal and Facial Interactions for Orthognathic Surgical Outcome Prediction
Jan 06, 2026Orthognathic surgery repositions jaw bones to restore occlusion and enhance facial aesthetics. Accurate simulation of postoperative facial morphology is essential for preoperative planning. However, traditional biomechanical models are computationally expensive, while geometric deep learning approaches often lack interpretability. In this study, we develop and validate a physics-informed geometric deep learning framework named PhysSFI-Net for precise prediction of soft tissue deformation following orthognathic surgery. PhysSFI-Net consists of three components: a hierarchical graph module with craniofacial and surgical plan encoders combined with attention mechanisms to extract skeletal-facial interaction features; a Long Short-Term Memory (LSTM)-based sequential predictor for incremental soft tissue deformation; and a biomechanics-inspired module for high-resolution facial surface reconstruction. Model performance was assessed using point cloud shape error (Hausdorff distance), surface deviation error, and landmark localization error (Euclidean distances of craniomaxillofacial landmarks) between predicted facial shapes and corresponding ground truths. A total of 135 patients who underwent combined orthodontic and orthognathic treatment were included for model training and validation. Quantitative analysis demonstrated that PhysSFI-Net achieved a point cloud shape error of 1.070 +/- 0.088 mm, a surface deviation error of 1.296 +/- 0.349 mm, and a landmark localization error of 2.445 +/- 1.326 mm. Comparative experiments indicated that PhysSFI-Net outperformed the state-of-the-art method ACMT-Net in prediction accuracy. In conclusion, PhysSFI-Net enables interpretable, high-resolution prediction of postoperative facial morphology with superior accuracy, showing strong potential for clinical application in orthognathic surgical planning and simulation.
Understanding Generalization in Diffusion Models via Probability Flow Distance
May 26, 2025Diffusion models have emerged as a powerful class of generative models, capable of producing high-quality samples that generalize beyond the training data. However, evaluating this generalization remains challenging: theoretical metrics are often impractical for high-dimensional data, while no practical metrics rigorously measure generalization. In this work, we bridge this gap by introducing probability flow distance ($\texttt{PFD}$), a theoretically grounded and computationally efficient metric to measure distributional generalization. Specifically, $\texttt{PFD}$ quantifies the distance between distributions by comparing their noise-to-data mappings induced by the probability flow ODE. Moreover, by using $\texttt{PFD}$ under a teacher-student evaluation protocol, we empirically uncover several key generalization behaviors in diffusion models, including: (1) scaling behavior from memorization to generalization, (2) early learning and double descent training dynamics, and (3) bias-variance decomposition. Beyond these insights, our work lays a foundation for future empirical and theoretical studies on generalization in diffusion models.
The Dual Power of Interpretable Token Embeddings: Jailbreaking Attacks and Defenses for Diffusion Model Unlearning
Apr 30, 2025Despite the remarkable generalization capabilities of diffusion models, recent studies have shown that these models can memorize and generate harmful content when prompted with specific text instructions. Although fine-tuning approaches have been developed to mitigate this issue by unlearning harmful concepts, these methods can be easily circumvented through jailbreaking attacks. This indicates that the harmful concept has not been fully erased from the model. However, existing attack methods, while effective, lack interpretability regarding why unlearned models still retain the concept, thereby hindering the development of defense strategies. In this work, we address these limitations by proposing an attack method that learns an orthogonal set of interpretable attack token embeddings. The attack token embeddings can be decomposed into human-interpretable textual elements, revealing that unlearned models still retain the target concept through implicit textual components. Furthermore, these attack token embeddings are robust and transferable across text prompts, initial noises, and unlearned models. Finally, leveraging this diverse set of embeddings, we design a defense method applicable to both our proposed attack and existing attack methods. Experimental results demonstrate the effectiveness of both our attack and defense strategies.
Understanding Representation Dynamics of Diffusion Models via Low-Dimensional Modeling
Feb 09, 2025



This work addresses the critical question of why and when diffusion models, despite being designed for generative tasks, can excel at learning high-quality representations in a self-supervised manner. To address this, we develop a mathematical framework based on a low-dimensional data model and posterior estimation, revealing a fundamental trade-off between generation and representation quality near the final stage of image generation. Our analysis explains the unimodal representation dynamics across noise scales, mainly driven by the interplay between data denoising and class specification. Building on these insights, we propose an ensemble method that aggregates features across noise levels, significantly improving both clean performance and robustness under label noise. Extensive experiments on both synthetic and real-world datasets validate our findings.
Explaining and Mitigating the Modality Gap in Contrastive Multimodal Learning
Dec 10, 2024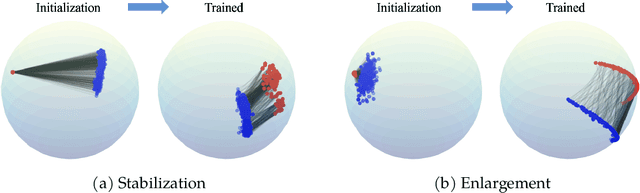

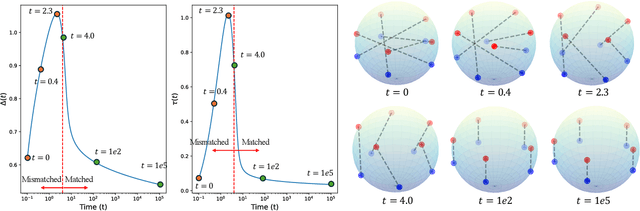
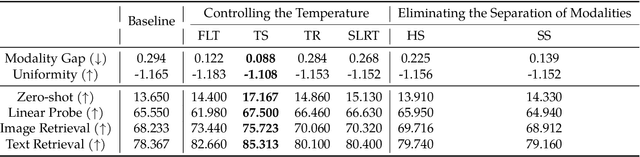
Multimodal learning has recently gained significant popularity, demonstrating impressive performance across various zero-shot classification tasks and a range of perceptive and generative applications. Models such as Contrastive Language-Image Pretraining (CLIP) are designed to bridge different modalities, such as images and text, by learning a shared representation space through contrastive learning. Despite their success, the working mechanisms underlying multimodal learning are not yet well understood. Notably, these models often exhibit a modality gap, where different modalities occupy distinct regions within the shared representation space. In this work, we conduct an in-depth analysis of the emergence of modality gap by characterizing the gradient flow learning dynamics. Specifically, we identify the critical roles of mismatched data pairs and a learnable temperature parameter in causing and perpetuating the modality gap during training. Furthermore, our theoretical insights are validated through experiments on practical CLIP models. These findings provide principled guidance for mitigating the modality gap, including strategies such as appropriate temperature scheduling and modality swapping. Additionally, we demonstrate that closing the modality gap leads to improved performance on tasks such as image-text retrieval.
Learning Diffusion Model from Noisy Measurement using Principled Expectation-Maximization Method
Oct 15, 2024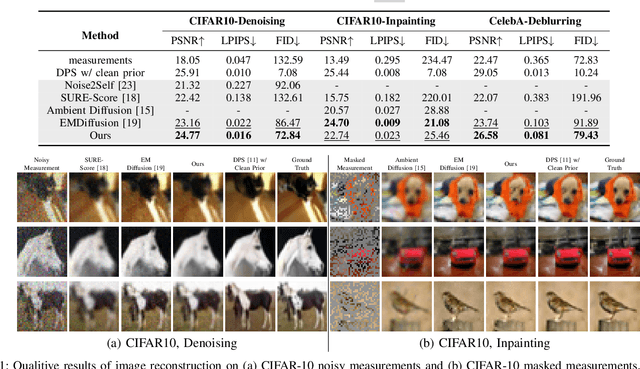


Diffusion models have demonstrated exceptional ability in modeling complex image distributions, making them versatile plug-and-play priors for solving imaging inverse problems. However, their reliance on large-scale clean datasets for training limits their applicability in scenarios where acquiring clean data is costly or impractical. Recent approaches have attempted to learn diffusion models directly from corrupted measurements, but these methods either lack theoretical convergence guarantees or are restricted to specific types of data corruption. In this paper, we propose a principled expectation-maximization (EM) framework that iteratively learns diffusion models from noisy data with arbitrary corruption types. Our framework employs a plug-and-play Monte Carlo method to accurately estimate clean images from noisy measurements, followed by training the diffusion model using the reconstructed images. This process alternates between estimation and training until convergence. We evaluate the performance of our method across various imaging tasks, including inpainting, denoising, and deblurring. Experimental results demonstrate that our approach enables the learning of high-fidelity diffusion priors from noisy data, significantly enhancing reconstruction quality in imaging inverse problems.