 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnfolding Videos Dynamics via Taylor Expansion
Sep 04, 2024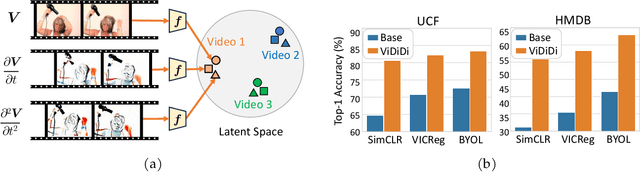

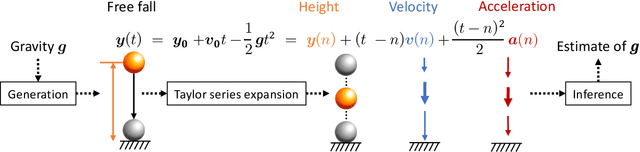

Taking inspiration from physical motion, we present a new self-supervised dynamics learning strategy for videos: Video Time-Differentiation for Instance Discrimination (ViDiDi). ViDiDi is a simple and data-efficient strategy, readily applicable to existing self-supervised video representation learning frameworks based on instance discrimination. At its core, ViDiDi observes different aspects of a video through various orders of temporal derivatives of its frame sequence. These derivatives, along with the original frames, support the Taylor series expansion of the underlying continuous dynamics at discrete times, where higher-order derivatives emphasize higher-order motion features. ViDiDi learns a single neural network that encodes a video and its temporal derivatives into consistent embeddings following a balanced alternating learning algorithm. By learning consistent representations for original frames and derivatives, the encoder is steered to emphasize motion features over static backgrounds and uncover the hidden dynamics in original frames. Hence, video representations are better separated by dynamic features. We integrate ViDiDi into existing instance discrimination frameworks (VICReg, BYOL, and SimCLR) for pretraining on UCF101 or Kinetics and test on standard benchmarks including video retrieval, action recognition, and action detection. The performances are enhanced by a significant margin without the need for large models or extensive datasets.
A Dual-Stream Neural Network Explains the Functional Segregation of Dorsal and Ventral Visual Pathways in Human Brains
Oct 20, 2023



The human visual system uses two parallel pathways for spatial processing and object recognition. In contrast, computer vision systems tend to use a single feedforward pathway, rendering them less robust, adaptive, or efficient than human vision. To bridge this gap, we developed a dual-stream vision model inspired by the human eyes and brain. At the input level, the model samples two complementary visual patterns to mimic how the human eyes use magnocellular and parvocellular retinal ganglion cells to separate retinal inputs to the brain. At the backend, the model processes the separate input patterns through two branches of convolutional neural networks (CNN) to mimic how the human brain uses the dorsal and ventral cortical pathways for parallel visual processing. The first branch (WhereCNN) samples a global view to learn spatial attention and control eye movements. The second branch (WhatCNN) samples a local view to represent the object around the fixation. Over time, the two branches interact recurrently to build a scene representation from moving fixations. We compared this model with the human brains processing the same movie and evaluated their functional alignment by linear transformation. The WhereCNN and WhatCNN branches were found to differentially match the dorsal and ventral pathways of the visual cortex, respectively, primarily due to their different learning objectives. These model-based results lead us to speculate that the distinct responses and representations of the ventral and dorsal streams are more influenced by their distinct goals in visual attention and object recognition than by their specific bias or selectivity in retinal inputs. This dual-stream model takes a further step in brain-inspired computer vision, enabling parallel neural networks to actively explore and understand the visual surroundings.
Human Eyes Inspired Recurrent Neural Networks are More Robust Against Adversarial Noises
Jun 15, 2022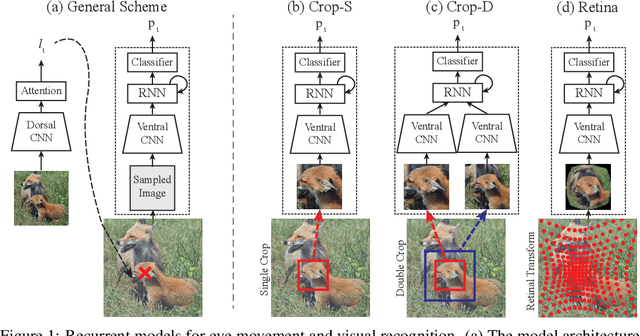

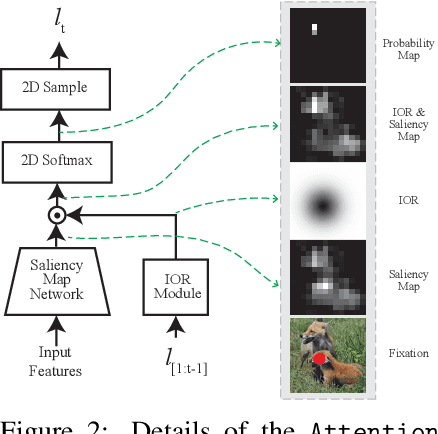

Compared to human vision, computer vision based on convolutional neural networks (CNN) are more vulnerable to adversarial noises. This difference is likely attributable to how the eyes sample visual input and how the brain processes retinal samples through its dorsal and ventral visual pathways, which are under-explored for computer vision. Inspired by the brain, we design recurrent neural networks, including an input sampler that mimics the human retina, a dorsal network that guides where to look next, and a ventral network that represents the retinal samples. Taking these modules together, the models learn to take multiple glances at an image, attend to a salient part at each glance, and accumulate the representation over time to recognize the image. We test such models for their robustness against a varying level of adversarial noises with a special focus on the effect of different input sampling strategies. Our findings suggest that retinal foveation and sampling renders a model more robust against adversarial noises, and the model may correct itself from an attack when it is given a longer time to take more glances at an image. In conclusion, robust visual recognition can benefit from the combined use of three brain-inspired mechanisms: retinal transformation, attention guided eye movement, and recurrent processing, as opposed to feedforward-only CNNs.
Explainable Semantic Space by Grounding Language to Vision with Cross-Modal Contrastive Learning
Nov 13, 2021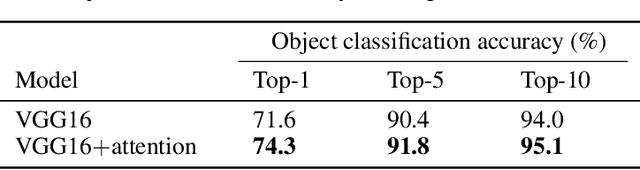
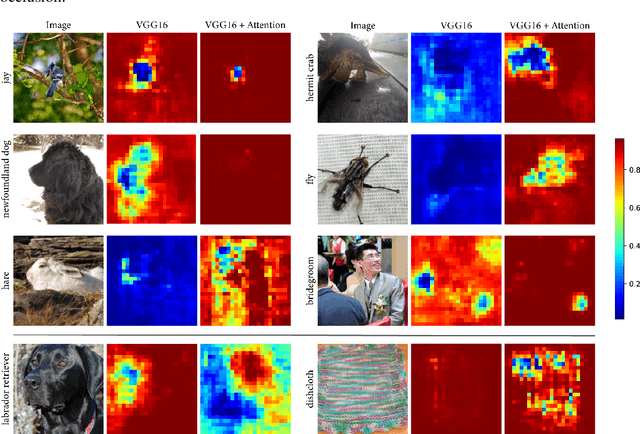
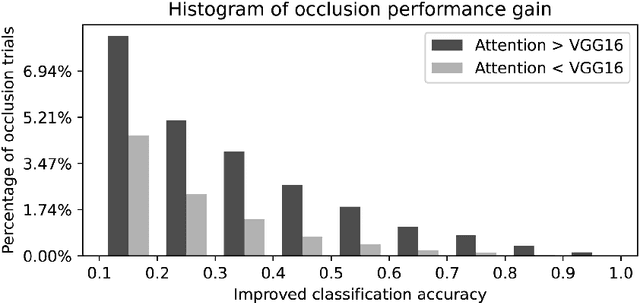

In natural language processing, most models try to learn semantic representations merely from texts. The learned representations encode the distributional semantics but fail to connect to any knowledge about the physical world. In contrast, humans learn language by grounding concepts in perception and action and the brain encodes grounded semantics for cognition. Inspired by this notion and recent work in vision-language learning, we design a two-stream model for grounding language learning in vision. The model includes a VGG-based visual stream and a Bert-based language stream. The two streams merge into a joint representational space. Through cross-modal contrastive learning, the model first learns to align visual and language representations with the MS COCO dataset. The model further learns to retrieve visual objects with language queries through a cross-modal attention module and to infer the visual relations between the retrieved objects through a bilinear operator with the Visual Genome dataset. After training, the language stream of this model is a stand-alone language model capable of embedding concepts in a visually grounded semantic space. This semantic space manifests principal dimensions explainable with human intuition and neurobiological knowledge. Word embeddings in this semantic space are predictive of human-defined norms of semantic features and are segregated into perceptually distinctive clusters. Furthermore, the visually grounded language model also enables compositional language understanding based on visual knowledge and multimodal image search with queries based on images, texts, or their combinations.
Deep Predictive Coding Network with Local Recurrent Processing for Object Recognition
Oct 26, 2018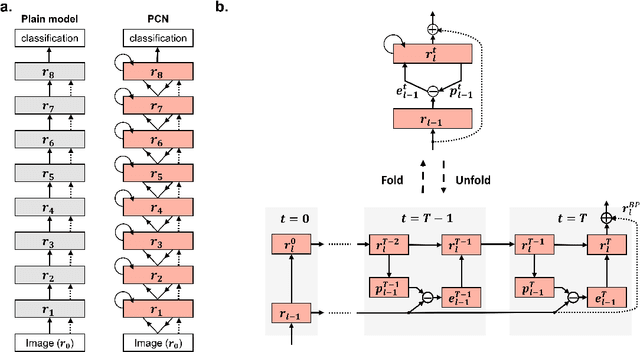
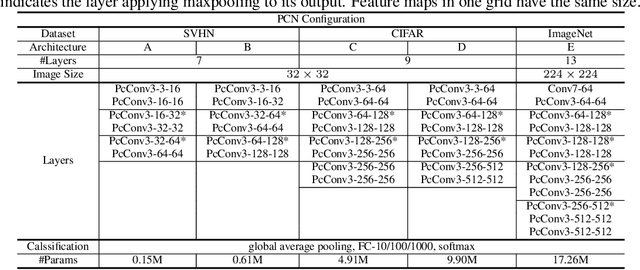
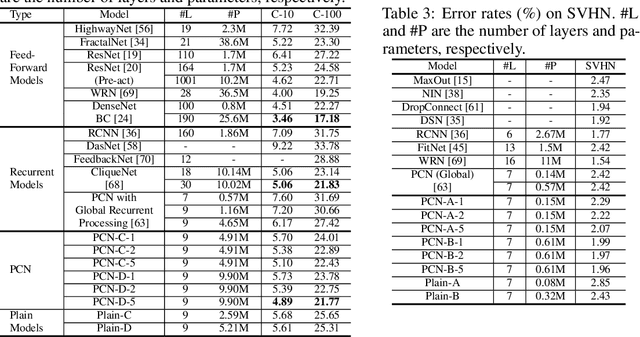
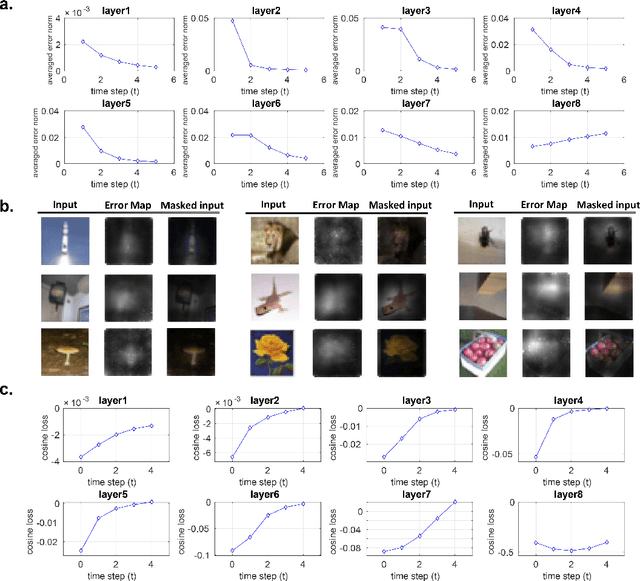
Inspired by "predictive coding" - a theory in neuroscience, we develop a bi-directional and dynamic neural network with local recurrent processing, namely predictive coding network (PCN). Unlike feedforward-only convolutional neural networks, PCN includes both feedback connections, which carry top-down predictions, and feedforward connections, which carry bottom-up errors of prediction. Feedback and feedforward connections enable adjacent layers to interact locally and recurrently to refine representations towards minimization of layer-wise prediction errors. When unfolded over time, the recurrent processing gives rise to an increasingly deeper hierarchy of non-linear transformation, allowing a shallow network to dynamically extend itself into an arbitrarily deep network. We train and test PCN for image classification with SVHN, CIFAR and ImageNet datasets. Despite notably fewer layers and parameters, PCN achieves competitive performance compared to classical and state-of-the-art models. Further analysis shows that the internal representations in PCN converge over time and yield increasingly better accuracy in object recognition. Errors of top-down prediction also reveal visual saliency or bottom-up attention.
Deep Predictive Coding Network for Object Recognition
Jul 29, 2018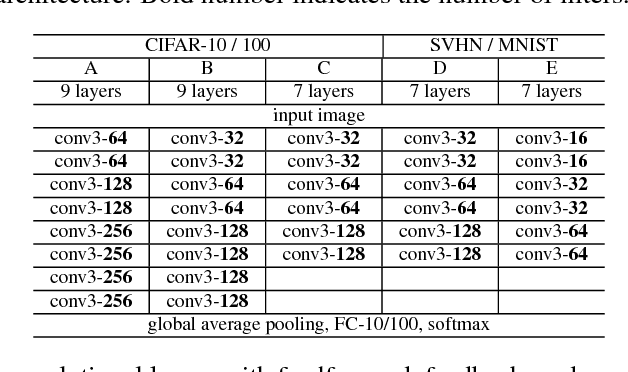
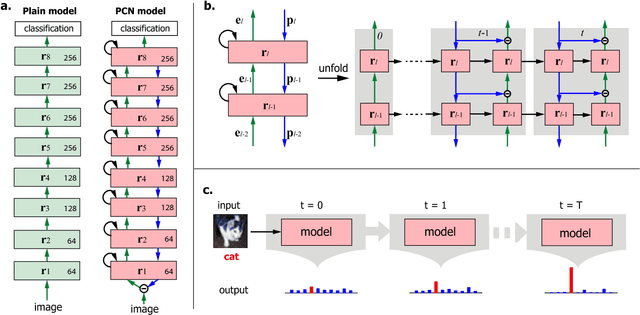
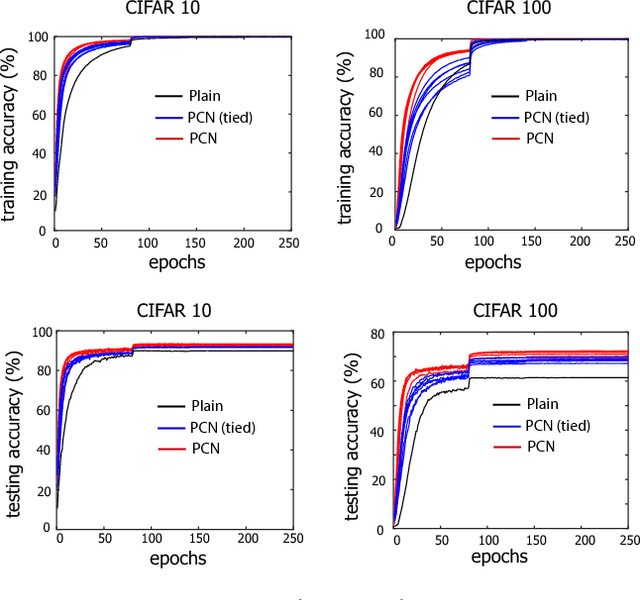
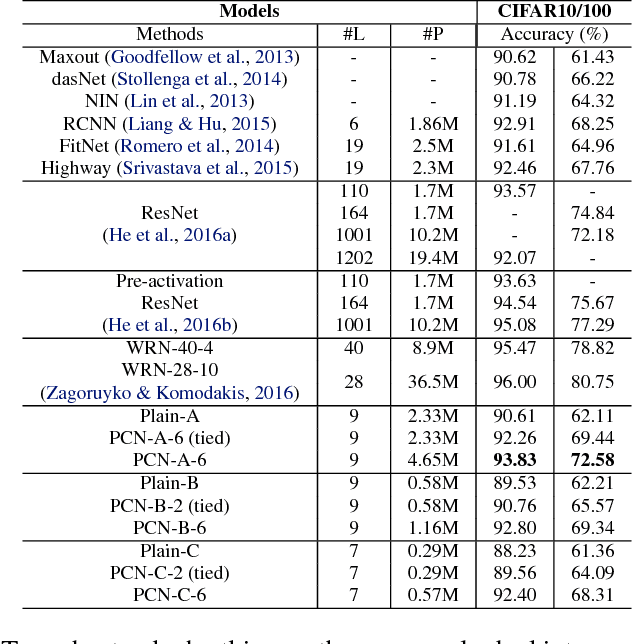
Based on the predictive coding theory in neuroscience, we designed a bi-directional and recurrent neural net, namely deep predictive coding networks (PCN). It has feedforward, feedback, and recurrent connections. Feedback connections from a higher layer carry the prediction of its lower-layer representation; feedforward connections carry the prediction errors to its higher-layer. Given image input, PCN runs recursive cycles of bottom-up and top-down computation to update its internal representations and reduce the difference between bottom-up input and top-down prediction at every layer. After multiple cycles of recursive updating, the representation is used for image classification. With benchmark data (CIFAR-10/100, SVHN, and MNIST), PCN was found to always outperform its feedforward-only counterpart: a model without any mechanism for recurrent dynamics. Its performance tended to improve given more cycles of computation over time. In short, PCN reuses a single architecture to recursively run bottom-up and top-down processes. As a dynamical system, PCN can be unfolded to a feedforward model that becomes deeper and deeper over time, while refining it representation towards more accurate and definitive object recognition.