 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Eyes Inspired Recurrent Neural Networks are More Robust Against Adversarial Noises
Paper and Code
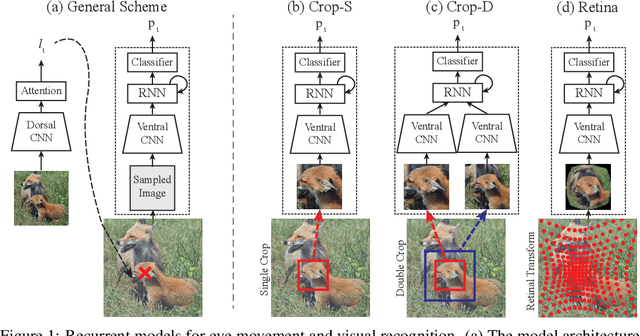

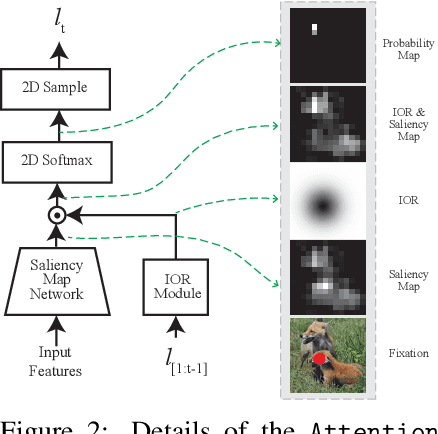

Compared to human vision, computer vision based on convolutional neural networks (CNN) are more vulnerable to adversarial noises. This difference is likely attributable to how the eyes sample visual input and how the brain processes retinal samples through its dorsal and ventral visual pathways, which are under-explored for computer vision. Inspired by the brain, we design recurrent neural networks, including an input sampler that mimics the human retina, a dorsal network that guides where to look next, and a ventral network that represents the retinal samples. Taking these modules together, the models learn to take multiple glances at an image, attend to a salient part at each glance, and accumulate the representation over time to recognize the image. We test such models for their robustness against a varying level of adversarial noises with a special focus on the effect of different input sampling strategies. Our findings suggest that retinal foveation and sampling renders a model more robust against adversarial noises, and the model may correct itself from an attack when it is given a longer time to take more glances at an image. In conclusion, robust visual recognition can benefit from the combined use of three brain-inspired mechanisms: retinal transformation, attention guided eye movement, and recurrent processing, as opposed to feedforward-only CNNs.