 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR: A Generic Framework for Text-Aided Map Compression for Localization
Mar 04, 2026Mapping is crucial in robotics for localization and downstream decision-making. As robots are deployed in ever-broader settings, the maps they rely on continue to increase in size. However, storing these maps indefinitely (cold storage), transferring them across networks, or sending localization queries to cloud-hosted maps imposes prohibitive memory and bandwidth costs. We propose a text-enhanced compression framework that reduces both memory and bandwidth footprints while retaining high-fidelity localization. The key idea is to treat text as an alternative modality: one that can be losslessly compressed with large language models. We propose leveraging lightweight text descriptions combined with very small image feature vectors, which capture "complementary information" as a compact representation for the mapping task. Building on this, our novel technique, Similarity Space Replication (SSR), learns an adaptive image embedding in one shot that captures only the information "complementary" to the text descriptions. We validate our compression framework on multiple downstream localization tasks, including Visual Place Recognition as well as object-centric Monte Carlo localization in both indoor and outdoor settings. SSR achieves 2 times better compression than competing baselines on state-of-the-art datasets, including TokyoVal, Pittsburgh30k, Replica, and KITTI.
A Challenge to Build Neuro-Symbolic Video Agents
May 20, 2025Modern video understanding systems excel at tasks such as scene classification, object detection, and short video retrieval. However, as video analysis becomes increasingly central to real-world applications, there is a growing need for proactive video agents for the systems that not only interpret video streams but also reason about events and take informed actions. A key obstacle in this direction is temporal reasoning: while deep learning models have made remarkable progress in recognizing patterns within individual frames or short clips, they struggle to understand the sequencing and dependencies of events over time, which is critical for action-driven decision-making. Addressing this limitation demands moving beyond conventional deep learning approaches. We posit that tackling this challenge requires a neuro-symbolic perspective, where video queries are decomposed into atomic events, structured into coherent sequences, and validated against temporal constraints. Such an approach can enhance interpretability, enable structured reasoning, and provide stronger guarantees on system behavior, all key properties for advancing trustworthy video agents. To this end, we present a grand challenge to the research community: developing the next generation of intelligent video agents that integrate three core capabilities: (1) autonomous video search and analysis, (2) seamless real-world interaction, and (3) advanced content generation. By addressing these pillars, we can transition from passive perception to intelligent video agents that reason, predict, and act, pushing the boundaries of video understanding.
Real-Time Privacy Preservation for Robot Visual Perception
May 08, 2025



Many robots (e.g., iRobot's Roomba) operate based on visual observations from live video streams, and such observations may inadvertently include privacy-sensitive objects, such as personal identifiers. Existing approaches for preserving privacy rely on deep learning models, differential privacy, or cryptography. They lack guarantees for the complete concealment of all sensitive objects. Guaranteeing concealment requires post-processing techniques and thus is inadequate for real-time video streams. We develop a method for privacy-constrained video streaming, PCVS, that conceals sensitive objects within real-time video streams. PCVS takes a logical specification constraining the existence of privacy-sensitive objects, e.g., never show faces when a person exists. It uses a detection model to evaluate the existence of these objects in each incoming frame. Then, it blurs out a subset of objects such that the existence of the remaining objects satisfies the specification. We then propose a conformal prediction approach to (i) establish a theoretical lower bound on the probability of the existence of these objects in a sequence of frames satisfying the specification and (ii) update the bound with the arrival of each subsequent frame. Quantitative evaluations show that PCVS achieves over 95 percent specification satisfaction rate in multiple datasets, significantly outperforming other methods. The satisfaction rate is consistently above the theoretical bounds across all datasets, indicating that the established bounds hold. Additionally, we deploy PCVS on robots in real-time operation and show that the robots operate normally without being compromised when PCVS conceals objects.
We'll Fix it in Post: Improving Text-to-Video Generation with Neuro-Symbolic Feedback
Apr 24, 2025
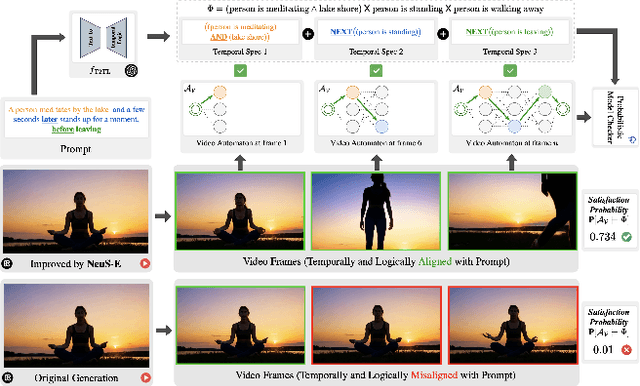


Current text-to-video (T2V) generation models are increasingly popular due to their ability to produce coherent videos from textual prompts. However, these models often struggle to generate semantically and temporally consistent videos when dealing with longer, more complex prompts involving multiple objects or sequential events. Additionally, the high computational costs associated with training or fine-tuning make direct improvements impractical. To overcome these limitations, we introduce \(\projectname\), a novel zero-training video refinement pipeline that leverages neuro-symbolic feedback to automatically enhance video generation, achieving superior alignment with the prompts. Our approach first derives the neuro-symbolic feedback by analyzing a formal video representation and pinpoints semantically inconsistent events, objects, and their corresponding frames. This feedback then guides targeted edits to the original video. Extensive empirical evaluations on both open-source and proprietary T2V models demonstrate that \(\projectname\) significantly enhances temporal and logical alignment across diverse prompts by almost $40\%$.
Neuro-Symbolic Evaluation of Text-to-Video Models using Formalf Verification
Nov 22, 2024Recent advancements in text-to-video models such as Sora, Gen-3, MovieGen, and CogVideoX are pushing the boundaries of synthetic video generation, with adoption seen in fields like robotics, autonomous driving, and entertainment. As these models become prevalent, various metrics and benchmarks have emerged to evaluate the quality of the generated videos. However, these metrics emphasize visual quality and smoothness, neglecting temporal fidelity and text-to-video alignment, which are crucial for safety-critical applications. To address this gap, we introduce NeuS-V, a novel synthetic video evaluation metric that rigorously assesses text-to-video alignment using neuro-symbolic formal verification techniques. Our approach first converts the prompt into a formally defined Temporal Logic (TL) specification and translates the generated video into an automaton representation. Then, it evaluates the text-to-video alignment by formally checking the video automaton against the TL specification. Furthermore, we present a dataset of temporally extended prompts to evaluate state-of-the-art video generation models against our benchmark. We find that NeuS-V demonstrates a higher correlation by over 5x with human evaluations when compared to existing metrics. Our evaluation further reveals that current video generation models perform poorly on these temporally complex prompts, highlighting the need for future work in improving text-to-video generation capabilities.
PEERNet: An End-to-End Profiling Tool for Real-Time Networked Robotic Systems
Sep 09, 2024Networked robotic systems balance compute, power, and latency constraints in applications such as self-driving vehicles, drone swarms, and teleoperated surgery. A core problem in this domain is deciding when to offload a computationally expensive task to the cloud, a remote server, at the cost of communication latency. Task offloading algorithms often rely on precise knowledge of system-specific performance metrics, such as sensor data rates, network bandwidth, and machine learning model latency. While these metrics can be modeled during system design, uncertainties in connection quality, server load, and hardware conditions introduce real-time performance variations, hindering overall performance. We introduce PEERNet, an end-to-end and real-time profiling tool for cloud robotics. PEERNet enables performance monitoring on heterogeneous hardware through targeted yet adaptive profiling of system components such as sensors, networks, deep-learning pipelines, and devices. We showcase PEERNet's capabilities through networked robotics tasks, such as image-based teleoperation of a Franka Emika Panda arm and querying vision language models using an Nvidia Jetson Orin. PEERNet reveals non-intuitive behavior in robotic systems, such as asymmetric network transmission and bimodal language model output. Our evaluation underscores the effectiveness and importance of benchmarking in networked robotics, demonstrating PEERNet's adaptability. Our code is open-source and available at github.com/UTAustin-SwarmLab/PEERNet.
Unfolding Videos Dynamics via Taylor Expansion
Sep 04, 2024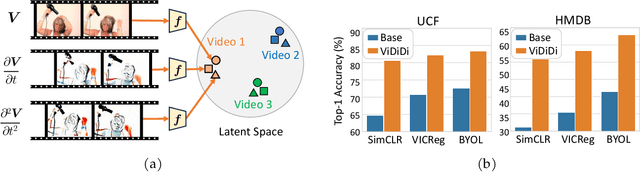

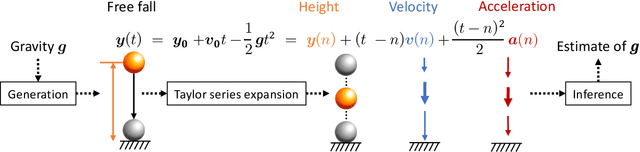

Taking inspiration from physical motion, we present a new self-supervised dynamics learning strategy for videos: Video Time-Differentiation for Instance Discrimination (ViDiDi). ViDiDi is a simple and data-efficient strategy, readily applicable to existing self-supervised video representation learning frameworks based on instance discrimination. At its core, ViDiDi observes different aspects of a video through various orders of temporal derivatives of its frame sequence. These derivatives, along with the original frames, support the Taylor series expansion of the underlying continuous dynamics at discrete times, where higher-order derivatives emphasize higher-order motion features. ViDiDi learns a single neural network that encodes a video and its temporal derivatives into consistent embeddings following a balanced alternating learning algorithm. By learning consistent representations for original frames and derivatives, the encoder is steered to emphasize motion features over static backgrounds and uncover the hidden dynamics in original frames. Hence, video representations are better separated by dynamic features. We integrate ViDiDi into existing instance discrimination frameworks (VICReg, BYOL, and SimCLR) for pretraining on UCF101 or Kinetics and test on standard benchmarks including video retrieval, action recognition, and action detection. The performances are enhanced by a significant margin without the need for large models or extensive datasets.
Temporal and Semantic Evaluation Metrics for Foundation Models in Post-Hoc Analysis of Robotic Sub-tasks
Mar 25, 2024Recent works in Task and Motion Planning (TAMP) show that training control policies on language-supervised robot trajectories with quality labeled data markedly improves agent task success rates. However, the scarcity of such data presents a significant hurdle to extending these methods to general use cases. To address this concern, we present an automated framework to decompose trajectory data into temporally bounded and natural language-based descriptive sub-tasks by leveraging recent prompting strategies for Foundation Models (FMs) including both Large Language Models (LLMs) and Vision Language Models (VLMs). Our framework provides both time-based and language-based descriptions for lower-level sub-tasks that comprise full trajectories. To rigorously evaluate the quality of our automatic labeling framework, we contribute an algorithm SIMILARITY to produce two novel metrics, temporal similarity and semantic similarity. The metrics measure the temporal alignment and semantic fidelity of language descriptions between two sub-task decompositions, namely an FM sub-task decomposition prediction and a ground-truth sub-task decomposition. We present scores for temporal similarity and semantic similarity above 90%, compared to 30% of a randomized baseline, for multiple robotic environments, demonstrating the effectiveness of our proposed framework. Our results enable building diverse, large-scale, language-supervised datasets for improved robotic TAMP.
Neuro-Symbolic Video Search
Mar 16, 2024The unprecedented surge in video data production in recent years necessitates efficient tools to extract meaningful frames from videos for downstream tasks. Long-term temporal reasoning is a key desideratum for frame retrieval systems. While state-of-the-art foundation models, like VideoLLaMA and ViCLIP, are proficient in short-term semantic understanding, they surprisingly fail at long-term reasoning across frames. A key reason for this failure is that they intertwine per-frame perception and temporal reasoning into a single deep network. Hence, decoupling but co-designing semantic understanding and temporal reasoning is essential for efficient scene identification. We propose a system that leverages vision-language models for semantic understanding of individual frames but effectively reasons about the long-term evolution of events using state machines and temporal logic (TL) formulae that inherently capture memory. Our TL-based reasoning improves the F1 score of complex event identification by 9-15% compared to benchmarks that use GPT4 for reasoning on state-of-the-art self-driving datasets such as Waymo and NuScenes.
A Dual-Stream Neural Network Explains the Functional Segregation of Dorsal and Ventral Visual Pathways in Human Brains
Oct 20, 2023



The human visual system uses two parallel pathways for spatial processing and object recognition. In contrast, computer vision systems tend to use a single feedforward pathway, rendering them less robust, adaptive, or efficient than human vision. To bridge this gap, we developed a dual-stream vision model inspired by the human eyes and brain. At the input level, the model samples two complementary visual patterns to mimic how the human eyes use magnocellular and parvocellular retinal ganglion cells to separate retinal inputs to the brain. At the backend, the model processes the separate input patterns through two branches of convolutional neural networks (CNN) to mimic how the human brain uses the dorsal and ventral cortical pathways for parallel visual processing. The first branch (WhereCNN) samples a global view to learn spatial attention and control eye movements. The second branch (WhatCNN) samples a local view to represent the object around the fixation. Over time, the two branches interact recurrently to build a scene representation from moving fixations. We compared this model with the human brains processing the same movie and evaluated their functional alignment by linear transformation. The WhereCNN and WhatCNN branches were found to differentially match the dorsal and ventral pathways of the visual cortex, respectively, primarily due to their different learning objectives. These model-based results lead us to speculate that the distinct responses and representations of the ventral and dorsal streams are more influenced by their distinct goals in visual attention and object recognition than by their specific bias or selectivity in retinal inputs. This dual-stream model takes a further step in brain-inspired computer vision, enabling parallel neural networks to actively explore and understand the visual surroundings.