 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Challenge to Build Neuro-Symbolic Video Agents
May 20, 2025Modern video understanding systems excel at tasks such as scene classification, object detection, and short video retrieval. However, as video analysis becomes increasingly central to real-world applications, there is a growing need for proactive video agents for the systems that not only interpret video streams but also reason about events and take informed actions. A key obstacle in this direction is temporal reasoning: while deep learning models have made remarkable progress in recognizing patterns within individual frames or short clips, they struggle to understand the sequencing and dependencies of events over time, which is critical for action-driven decision-making. Addressing this limitation demands moving beyond conventional deep learning approaches. We posit that tackling this challenge requires a neuro-symbolic perspective, where video queries are decomposed into atomic events, structured into coherent sequences, and validated against temporal constraints. Such an approach can enhance interpretability, enable structured reasoning, and provide stronger guarantees on system behavior, all key properties for advancing trustworthy video agents. To this end, we present a grand challenge to the research community: developing the next generation of intelligent video agents that integrate three core capabilities: (1) autonomous video search and analysis, (2) seamless real-world interaction, and (3) advanced content generation. By addressing these pillars, we can transition from passive perception to intelligent video agents that reason, predict, and act, pushing the boundaries of video understanding.
We'll Fix it in Post: Improving Text-to-Video Generation with Neuro-Symbolic Feedback
Apr 24, 2025
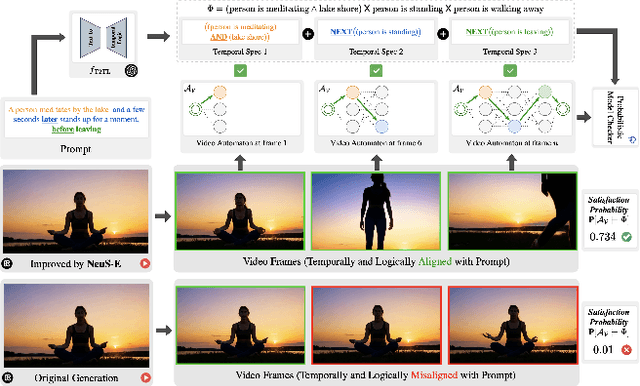


Current text-to-video (T2V) generation models are increasingly popular due to their ability to produce coherent videos from textual prompts. However, these models often struggle to generate semantically and temporally consistent videos when dealing with longer, more complex prompts involving multiple objects or sequential events. Additionally, the high computational costs associated with training or fine-tuning make direct improvements impractical. To overcome these limitations, we introduce \(\projectname\), a novel zero-training video refinement pipeline that leverages neuro-symbolic feedback to automatically enhance video generation, achieving superior alignment with the prompts. Our approach first derives the neuro-symbolic feedback by analyzing a formal video representation and pinpoints semantically inconsistent events, objects, and their corresponding frames. This feedback then guides targeted edits to the original video. Extensive empirical evaluations on both open-source and proprietary T2V models demonstrate that \(\projectname\) significantly enhances temporal and logical alignment across diverse prompts by almost $40\%$.
LLM-Assist: Enhancing Closed-Loop Planning with Language-Based Reasoning
Dec 30, 2023Although planning is a crucial component of the autonomous driving stack, researchers have yet to develop robust planning algorithms that are capable of safely handling the diverse range of possible driving scenarios. Learning-based planners suffer from overfitting and poor long-tail performance. On the other hand, rule-based planners generalize well, but might fail to handle scenarios that require complex driving maneuvers. To address these limitations, we investigate the possibility of leveraging the common-sense reasoning capabilities of Large Language Models (LLMs) such as GPT4 and Llama2 to generate plans for self-driving vehicles. In particular, we develop a novel hybrid planner that leverages a conventional rule-based planner in conjunction with an LLM-based planner. Guided by commonsense reasoning abilities of LLMs, our approach navigates complex scenarios which existing planners struggle with, produces well-reasoned outputs while also remaining grounded through working alongside the rule-based approach. Through extensive evaluation on the nuPlan benchmark, we achieve state-of-the-art performance, outperforming all existing pure learning- and rule-based methods across most metrics. Our code will be available at https://llmassist.github.io.
Outline, Then Details: Syntactically Guided Coarse-To-Fine Code Generation
May 08, 2023



For a complicated algorithm, its implementation by a human programmer usually starts with outlining a rough control flow followed by iterative enrichments, eventually yielding carefully generated syntactic structures and variables in a hierarchy. However, state-of-the-art large language models generate codes in a single pass, without intermediate warm-ups to reflect the structured thought process of "outline-then-detail". Inspired by the recent success of chain-of-thought prompting, we propose ChainCoder, a program synthesis language model that generates Python code progressively, i.e. from coarse to fine in multiple passes. We first decompose source code into layout frame components and accessory components via abstract syntax tree parsing to construct a hierarchical representation. We then reform our prediction target into a multi-pass objective, each pass generates a subsequence, which is concatenated in the hierarchy. Finally, a tailored transformer architecture is leveraged to jointly encode the natural language descriptions and syntactically aligned I/O data samples. Extensive evaluations show that ChainCoder outperforms state-of-the-arts, demonstrating that our progressive generation eases the reasoning procedure and guides the language model to generate higher-quality solutions. Our codes are available at: https://github.com/VITA-Group/ChainCoder.
Symbolic Visual Reinforcement Learning: A Scalable Framework with Object-Level Abstraction and Differentiable Expression Search
Dec 30, 2022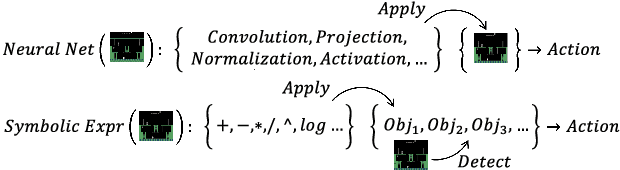
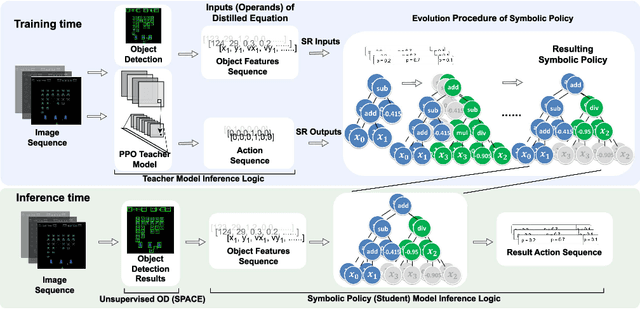
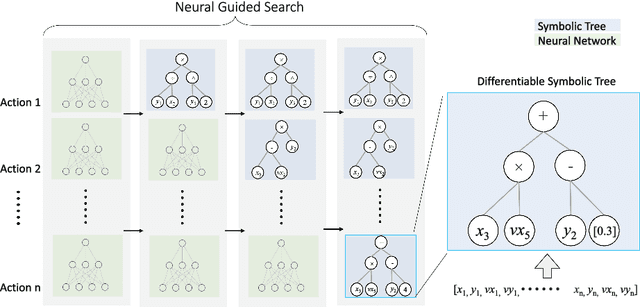
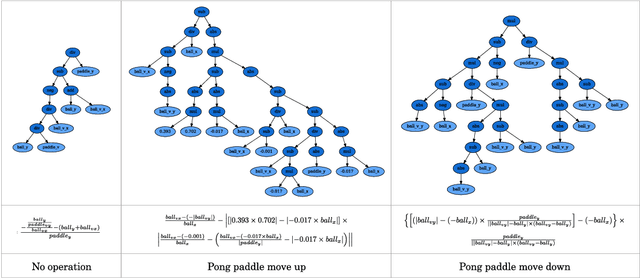
Learning efficient and interpretable policies has been a challenging task in reinforcement learning (RL), particularly in the visual RL setting with complex scenes. While neural networks have achieved competitive performance, the resulting policies are often over-parameterized black boxes that are difficult to interpret and deploy efficiently. More recent symbolic RL frameworks have shown that high-level domain-specific programming logic can be designed to handle both policy learning and symbolic planning. However, these approaches rely on coded primitives with little feature learning, and when applied to high-dimensional visual scenes, they can suffer from scalability issues and perform poorly when images have complex object interactions. To address these challenges, we propose \textit{Differentiable Symbolic Expression Search} (DiffSES), a novel symbolic learning approach that discovers discrete symbolic policies using partially differentiable optimization. By using object-level abstractions instead of raw pixel-level inputs, DiffSES is able to leverage the simplicity and scalability advantages of symbolic expressions, while also incorporating the strengths of neural networks for feature learning and optimization. Our experiments demonstrate that DiffSES is able to generate symbolic policies that are simpler and more and scalable than state-of-the-art symbolic RL methods, with a reduced amount of symbolic prior knowledge.
Symbolic Distillation for Learned TCP Congestion Control
Oct 24, 2022



Recent advances in TCP congestion control (CC) have achieved tremendous success with deep reinforcement learning (RL) approaches, which use feedforward neural networks (NN) to learn complex environment conditions and make better decisions. However, such "black-box" policies lack interpretability and reliability, and often, they need to operate outside the traditional TCP datapath due to the use of complex NNs. This paper proposes a novel two-stage solution to achieve the best of both worlds: first to train a deep RL agent, then distill its (over-)parameterized NN policy into white-box, light-weight rules in the form of symbolic expressions that are much easier to understand and to implement in constrained environments. At the core of our proposal is a novel symbolic branching algorithm that enables the rule to be aware of the context in terms of various network conditions, eventually converting the NN policy into a symbolic tree. The distilled symbolic rules preserve and often improve performance over state-of-the-art NN policies while being faster and simpler than a standard neural network. We validate the performance of our distilled symbolic rules on both simulation and emulation environments. Our code is available at https://github.com/VITA-Group/SymbolicPCC.