 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordLight: Learning Decentralized Coordination for Network-Wide Traffic Signal Control
Mar 25, 2026Adaptive traffic signal control (ATSC) is crucial in alleviating congestion, maximizing throughput and promoting sustainable mobility in ever-expanding cities. Multi-Agent Reinforcement Learning (MARL) has recently shown significant potential in addressing complex traffic dynamics, but the intricacies of partial observability and coordination in decentralized environments still remain key challenges in formulating scalable and efficient control strategies. To address these challenges, we present CoordLight, a MARL-based framework designed to improve intra-neighborhood traffic by enhancing decision-making at individual junctions (agents), as well as coordination with neighboring agents, thereby scaling up to network-level traffic optimization. Specifically, we introduce the Queue Dynamic State Encoding (QDSE), a novel state representation based on vehicle queuing models, which strengthens the agents' capability to analyze, predict, and respond to local traffic dynamics. We further propose an advanced MARL algorithm, named Neighbor-aware Policy Optimization (NAPO). It integrates an attention mechanism that discerns the state and action dependencies among adjacent agents, aiming to facilitate more coordinated decision-making, and to improve policy learning updates through robust advantage calculation. This enables agents to identify and prioritize crucial interactions with influential neighbors, thus enhancing the targeted coordination and collaboration among agents. Through comprehensive evaluations against state-of-the-art traffic signal control methods over three real-world traffic datasets composed of up to 196 intersections, we empirically show that CoordLight consistently exhibits superior performance across diverse traffic networks with varying traffic flows. The code is available at https://github.com/marmotlab/CoordLight
SSR: A Generic Framework for Text-Aided Map Compression for Localization
Mar 04, 2026Mapping is crucial in robotics for localization and downstream decision-making. As robots are deployed in ever-broader settings, the maps they rely on continue to increase in size. However, storing these maps indefinitely (cold storage), transferring them across networks, or sending localization queries to cloud-hosted maps imposes prohibitive memory and bandwidth costs. We propose a text-enhanced compression framework that reduces both memory and bandwidth footprints while retaining high-fidelity localization. The key idea is to treat text as an alternative modality: one that can be losslessly compressed with large language models. We propose leveraging lightweight text descriptions combined with very small image feature vectors, which capture "complementary information" as a compact representation for the mapping task. Building on this, our novel technique, Similarity Space Replication (SSR), learns an adaptive image embedding in one shot that captures only the information "complementary" to the text descriptions. We validate our compression framework on multiple downstream localization tasks, including Visual Place Recognition as well as object-centric Monte Carlo localization in both indoor and outdoor settings. SSR achieves 2 times better compression than competing baselines on state-of-the-art datasets, including TokyoVal, Pittsburgh30k, Replica, and KITTI.
A Challenge to Build Neuro-Symbolic Video Agents
May 20, 2025Modern video understanding systems excel at tasks such as scene classification, object detection, and short video retrieval. However, as video analysis becomes increasingly central to real-world applications, there is a growing need for proactive video agents for the systems that not only interpret video streams but also reason about events and take informed actions. A key obstacle in this direction is temporal reasoning: while deep learning models have made remarkable progress in recognizing patterns within individual frames or short clips, they struggle to understand the sequencing and dependencies of events over time, which is critical for action-driven decision-making. Addressing this limitation demands moving beyond conventional deep learning approaches. We posit that tackling this challenge requires a neuro-symbolic perspective, where video queries are decomposed into atomic events, structured into coherent sequences, and validated against temporal constraints. Such an approach can enhance interpretability, enable structured reasoning, and provide stronger guarantees on system behavior, all key properties for advancing trustworthy video agents. To this end, we present a grand challenge to the research community: developing the next generation of intelligent video agents that integrate three core capabilities: (1) autonomous video search and analysis, (2) seamless real-world interaction, and (3) advanced content generation. By addressing these pillars, we can transition from passive perception to intelligent video agents that reason, predict, and act, pushing the boundaries of video understanding.
We'll Fix it in Post: Improving Text-to-Video Generation with Neuro-Symbolic Feedback
Apr 24, 2025
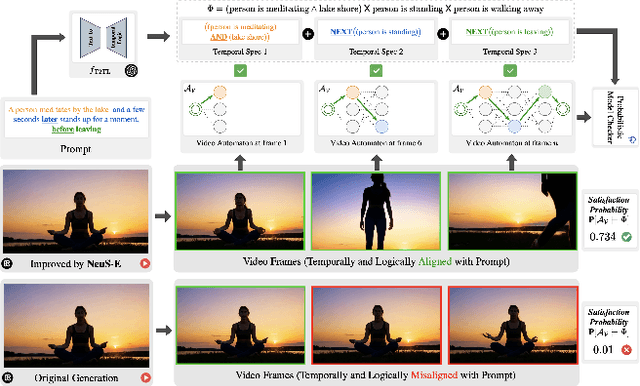


Current text-to-video (T2V) generation models are increasingly popular due to their ability to produce coherent videos from textual prompts. However, these models often struggle to generate semantically and temporally consistent videos when dealing with longer, more complex prompts involving multiple objects or sequential events. Additionally, the high computational costs associated with training or fine-tuning make direct improvements impractical. To overcome these limitations, we introduce \(\projectname\), a novel zero-training video refinement pipeline that leverages neuro-symbolic feedback to automatically enhance video generation, achieving superior alignment with the prompts. Our approach first derives the neuro-symbolic feedback by analyzing a formal video representation and pinpoints semantically inconsistent events, objects, and their corresponding frames. This feedback then guides targeted edits to the original video. Extensive empirical evaluations on both open-source and proprietary T2V models demonstrate that \(\projectname\) significantly enhances temporal and logical alignment across diverse prompts by almost $40\%$.
SynDiff-AD: Improving Semantic Segmentation and End-to-End Autonomous Driving with Synthetic Data from Latent Diffusion Models
Nov 25, 2024In recent years, significant progress has been made in collecting large-scale datasets to improve segmentation and autonomous driving models. These large-scale datasets are often dominated by common environmental conditions such as "Clear and Day" weather, leading to decreased performance in under-represented conditions like "Rainy and Night". To address this issue, we introduce SynDiff-AD, a novel data augmentation pipeline that leverages diffusion models (DMs) to generate realistic images for such subgroups. SynDiff-AD uses ControlNet-a DM that guides data generation conditioned on semantic maps-along with a novel prompting scheme that generates subgroup-specific, semantically dense prompts. By augmenting datasets with SynDiff-AD, we improve the performance of segmentation models like Mask2Former and SegFormer by up to 1.2% and 2.3% on the Waymo dataset, and up to 1.4% and 0.7% on the DeepDrive dataset, respectively. Additionally, we demonstrate that our SynDiff-AD pipeline enhances the driving performance of end-to-end autonomous driving models, like AIM-2D and AIM-BEV, by up to 20% across diverse environmental conditions in the CARLA autonomous driving simulator, providing a more robust model.
Neuro-Symbolic Evaluation of Text-to-Video Models using Formalf Verification
Nov 22, 2024Recent advancements in text-to-video models such as Sora, Gen-3, MovieGen, and CogVideoX are pushing the boundaries of synthetic video generation, with adoption seen in fields like robotics, autonomous driving, and entertainment. As these models become prevalent, various metrics and benchmarks have emerged to evaluate the quality of the generated videos. However, these metrics emphasize visual quality and smoothness, neglecting temporal fidelity and text-to-video alignment, which are crucial for safety-critical applications. To address this gap, we introduce NeuS-V, a novel synthetic video evaluation metric that rigorously assesses text-to-video alignment using neuro-symbolic formal verification techniques. Our approach first converts the prompt into a formally defined Temporal Logic (TL) specification and translates the generated video into an automaton representation. Then, it evaluates the text-to-video alignment by formally checking the video automaton against the TL specification. Furthermore, we present a dataset of temporally extended prompts to evaluate state-of-the-art video generation models against our benchmark. We find that NeuS-V demonstrates a higher correlation by over 5x with human evaluations when compared to existing metrics. Our evaluation further reveals that current video generation models perform poorly on these temporally complex prompts, highlighting the need for future work in improving text-to-video generation capabilities.
Neuro-Symbolic Video Search
Mar 16, 2024The unprecedented surge in video data production in recent years necessitates efficient tools to extract meaningful frames from videos for downstream tasks. Long-term temporal reasoning is a key desideratum for frame retrieval systems. While state-of-the-art foundation models, like VideoLLaMA and ViCLIP, are proficient in short-term semantic understanding, they surprisingly fail at long-term reasoning across frames. A key reason for this failure is that they intertwine per-frame perception and temporal reasoning into a single deep network. Hence, decoupling but co-designing semantic understanding and temporal reasoning is essential for efficient scene identification. We propose a system that leverages vision-language models for semantic understanding of individual frames but effectively reasons about the long-term evolution of events using state machines and temporal logic (TL) formulae that inherently capture memory. Our TL-based reasoning improves the F1 score of complex event identification by 9-15% compared to benchmarks that use GPT4 for reasoning on state-of-the-art self-driving datasets such as Waymo and NuScenes.
Reinforcement Learning for Agile Active Target Sensing with a UAV
Dec 16, 2022
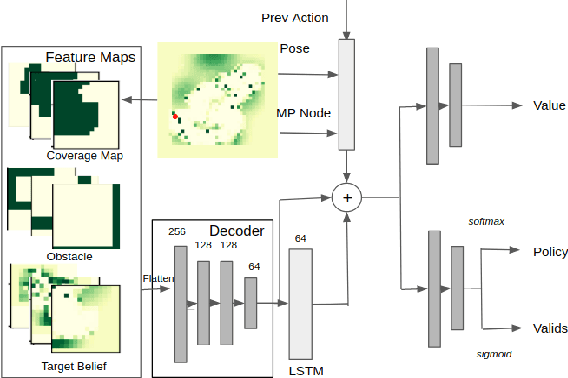
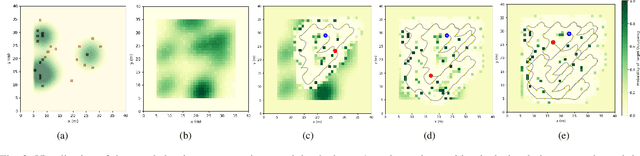
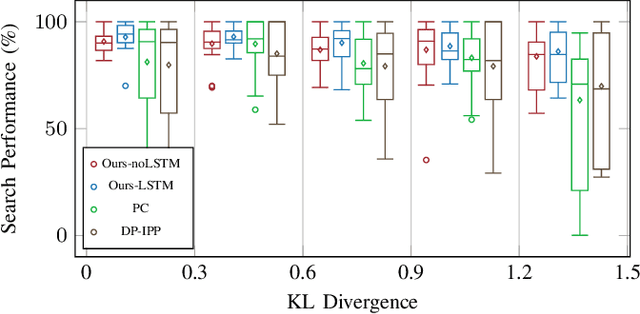
Active target sensing is the task of discovering and classifying an unknown number of targets in an environment and is critical in search-and-rescue missions. This paper develops a deep reinforcement learning approach to plan informative trajectories that increase the likelihood for an uncrewed aerial vehicle (UAV) to discover missing targets. Our approach efficiently (1) explores the environment to discover new targets, (2) exploits its current belief of the target states and incorporates inaccurate sensor models for high-fidelity classification, and (3) generates dynamically feasible trajectories for an agile UAV by employing a motion primitive library. Extensive simulations on randomly generated environments show that our approach is more efficient in discovering and classifying targets than several other baselines. A unique characteristic of our approach, in contrast to heuristic informative path planning approaches, is that it is robust to varying amounts of deviations of the prior belief from the true target distribution, thereby alleviating the challenge of designing heuristics specific to the application conditions.