 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
Biologically Plausible Online Hebbian Meta-Learning: Two-Timescale Local Rules for Spiking Neural Brain Interfaces
Sep 19, 2025


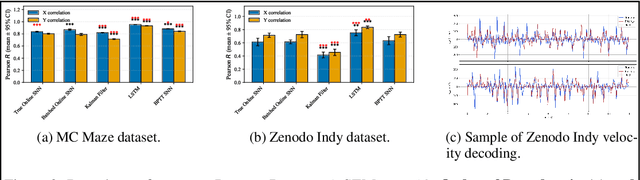
Brain-Computer Interfaces face challenges from neural signal instability and memory constraints for real-time implantable applications. We introduce an online SNN decoder using local three-factor learning rules with dual-timescale eligibility traces that avoid backpropagation through time while maintaining competitive performance. Our approach combines error-modulated Hebbian updates, fast/slow trace consolidation, and adaptive learning rate control, requiring only O(1) memory versus O(T) for BPTT methods. Evaluations on two primate datasets achieve comparable decoding accuracy (Pearson $R \geq 0.63$ Zenodo, $R \geq 0.81$ MC Maze) with 28-35% memory reduction and faster convergence than BPTT-trained SNNs. Closed-loop simulations with synthetic neural populations demonstrate adaptation to neural disruptions and learning from scratch without offline calibration. This work enables memory-efficient, continuously adaptive neural decoding suitable for resource-constrained implantable BCI systems.
A Challenge to Build Neuro-Symbolic Video Agents
May 20, 2025Modern video understanding systems excel at tasks such as scene classification, object detection, and short video retrieval. However, as video analysis becomes increasingly central to real-world applications, there is a growing need for proactive video agents for the systems that not only interpret video streams but also reason about events and take informed actions. A key obstacle in this direction is temporal reasoning: while deep learning models have made remarkable progress in recognizing patterns within individual frames or short clips, they struggle to understand the sequencing and dependencies of events over time, which is critical for action-driven decision-making. Addressing this limitation demands moving beyond conventional deep learning approaches. We posit that tackling this challenge requires a neuro-symbolic perspective, where video queries are decomposed into atomic events, structured into coherent sequences, and validated against temporal constraints. Such an approach can enhance interpretability, enable structured reasoning, and provide stronger guarantees on system behavior, all key properties for advancing trustworthy video agents. To this end, we present a grand challenge to the research community: developing the next generation of intelligent video agents that integrate three core capabilities: (1) autonomous video search and analysis, (2) seamless real-world interaction, and (3) advanced content generation. By addressing these pillars, we can transition from passive perception to intelligent video agents that reason, predict, and act, pushing the boundaries of video understanding.
Real-Time Privacy Preservation for Robot Visual Perception
May 08, 2025



Many robots (e.g., iRobot's Roomba) operate based on visual observations from live video streams, and such observations may inadvertently include privacy-sensitive objects, such as personal identifiers. Existing approaches for preserving privacy rely on deep learning models, differential privacy, or cryptography. They lack guarantees for the complete concealment of all sensitive objects. Guaranteeing concealment requires post-processing techniques and thus is inadequate for real-time video streams. We develop a method for privacy-constrained video streaming, PCVS, that conceals sensitive objects within real-time video streams. PCVS takes a logical specification constraining the existence of privacy-sensitive objects, e.g., never show faces when a person exists. It uses a detection model to evaluate the existence of these objects in each incoming frame. Then, it blurs out a subset of objects such that the existence of the remaining objects satisfies the specification. We then propose a conformal prediction approach to (i) establish a theoretical lower bound on the probability of the existence of these objects in a sequence of frames satisfying the specification and (ii) update the bound with the arrival of each subsequent frame. Quantitative evaluations show that PCVS achieves over 95 percent specification satisfaction rate in multiple datasets, significantly outperforming other methods. The satisfaction rate is consistently above the theoretical bounds across all datasets, indicating that the established bounds hold. Additionally, we deploy PCVS on robots in real-time operation and show that the robots operate normally without being compromised when PCVS conceals objects.
We'll Fix it in Post: Improving Text-to-Video Generation with Neuro-Symbolic Feedback
Apr 24, 2025
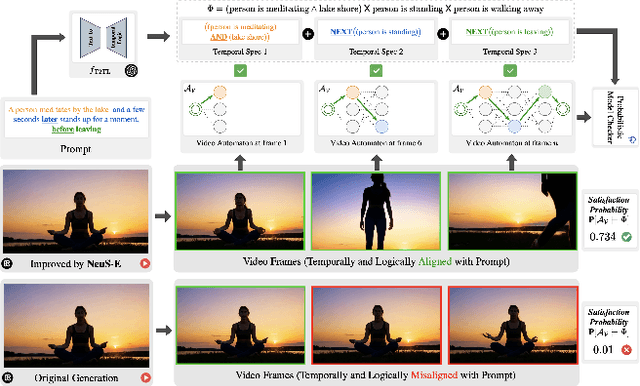


Current text-to-video (T2V) generation models are increasingly popular due to their ability to produce coherent videos from textual prompts. However, these models often struggle to generate semantically and temporally consistent videos when dealing with longer, more complex prompts involving multiple objects or sequential events. Additionally, the high computational costs associated with training or fine-tuning make direct improvements impractical. To overcome these limitations, we introduce \(\projectname\), a novel zero-training video refinement pipeline that leverages neuro-symbolic feedback to automatically enhance video generation, achieving superior alignment with the prompts. Our approach first derives the neuro-symbolic feedback by analyzing a formal video representation and pinpoints semantically inconsistent events, objects, and their corresponding frames. This feedback then guides targeted edits to the original video. Extensive empirical evaluations on both open-source and proprietary T2V models demonstrate that \(\projectname\) significantly enhances temporal and logical alignment across diverse prompts by almost $40\%$.
Acoustic Analysis of Uneven Blade Spacing and Toroidal Geometry for Reducing Propeller Annoyance
Apr 17, 2025Unmanned aerial vehicles (UAVs) are becoming more commonly used in populated areas, raising concerns about noise pollution generated from their propellers. This study investigates the acoustic performance of unconventional propeller designs, specifically toroidal and uneven-blade spaced propellers, for their potential in reducing psychoacoustic annoyance. Our experimental results show that these designs noticeably reduced acoustic characteristics associated with noise annoyance.
Neuro-Symbolic Evaluation of Text-to-Video Models using Formalf Verification
Nov 22, 2024Recent advancements in text-to-video models such as Sora, Gen-3, MovieGen, and CogVideoX are pushing the boundaries of synthetic video generation, with adoption seen in fields like robotics, autonomous driving, and entertainment. As these models become prevalent, various metrics and benchmarks have emerged to evaluate the quality of the generated videos. However, these metrics emphasize visual quality and smoothness, neglecting temporal fidelity and text-to-video alignment, which are crucial for safety-critical applications. To address this gap, we introduce NeuS-V, a novel synthetic video evaluation metric that rigorously assesses text-to-video alignment using neuro-symbolic formal verification techniques. Our approach first converts the prompt into a formally defined Temporal Logic (TL) specification and translates the generated video into an automaton representation. Then, it evaluates the text-to-video alignment by formally checking the video automaton against the TL specification. Furthermore, we present a dataset of temporally extended prompts to evaluate state-of-the-art video generation models against our benchmark. We find that NeuS-V demonstrates a higher correlation by over 5x with human evaluations when compared to existing metrics. Our evaluation further reveals that current video generation models perform poorly on these temporally complex prompts, highlighting the need for future work in improving text-to-video generation capabilities.
Neuro-Symbolic Video Search
Mar 16, 2024The unprecedented surge in video data production in recent years necessitates efficient tools to extract meaningful frames from videos for downstream tasks. Long-term temporal reasoning is a key desideratum for frame retrieval systems. While state-of-the-art foundation models, like VideoLLaMA and ViCLIP, are proficient in short-term semantic understanding, they surprisingly fail at long-term reasoning across frames. A key reason for this failure is that they intertwine per-frame perception and temporal reasoning into a single deep network. Hence, decoupling but co-designing semantic understanding and temporal reasoning is essential for efficient scene identification. We propose a system that leverages vision-language models for semantic understanding of individual frames but effectively reasons about the long-term evolution of events using state machines and temporal logic (TL) formulae that inherently capture memory. Our TL-based reasoning improves the F1 score of complex event identification by 9-15% compared to benchmarks that use GPT4 for reasoning on state-of-the-art self-driving datasets such as Waymo and NuScenes.
NLP Service APIs and Models for Efficient Registration of New Clients
Oct 04, 2020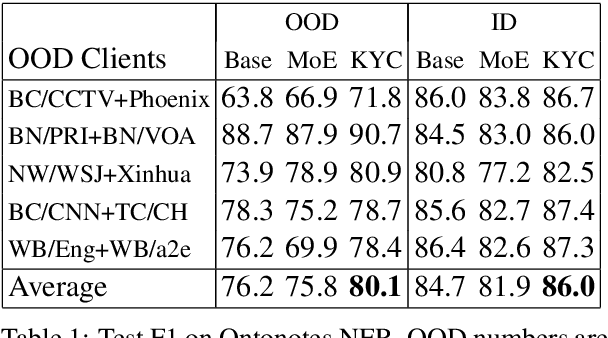
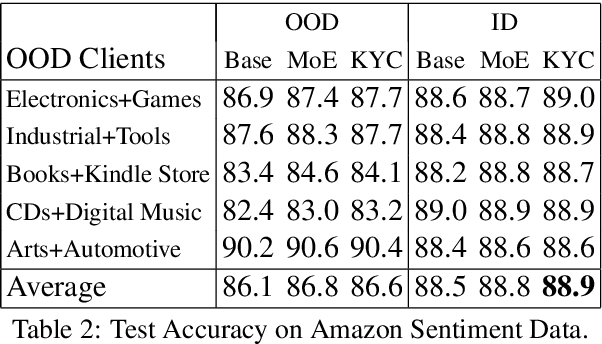
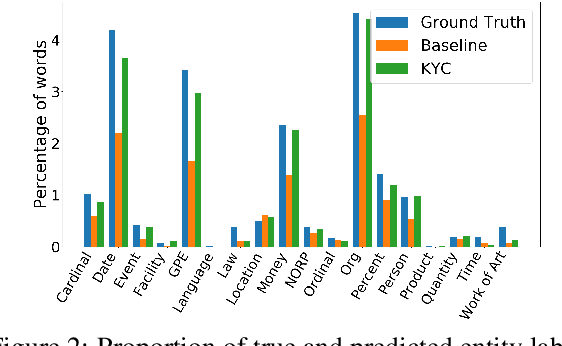
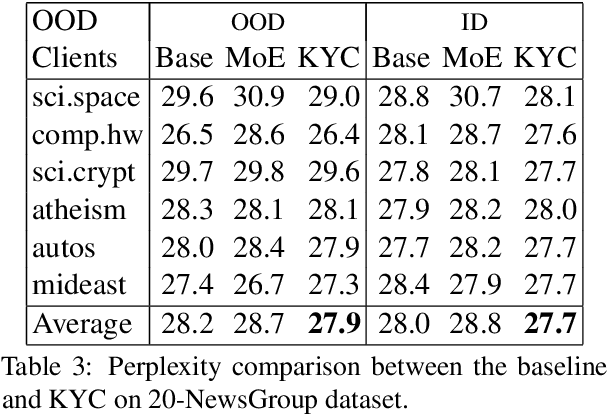
State-of-the-art NLP inference uses enormous neural architectures and models trained for GPU-months, well beyond the reach of most consumers of NLP. This has led to one-size-fits-all public API-based NLP service models by major AI companies, serving large numbers of clients. Neither (hardware deficient) clients nor (heavily subscribed) servers can afford traditional fine tuning. Many clients own little or no labeled data. We initiate a study of adaptation of centralized NLP services to clients, and present one practical and lightweight approach. Each client uses an unsupervised, corpus-based sketch to register to the service. The server uses an auxiliary network to map the sketch to an abstract vector representation, which then informs the main labeling network. When a new client registers with its sketch, it gets immediate accuracy benefits. We demonstrate the success of the proposed architecture using sentiment labeling, NER, and predictive language modeling
Lower Bounds for Policy Iteration on Multi-action MDPs
Sep 16, 2020
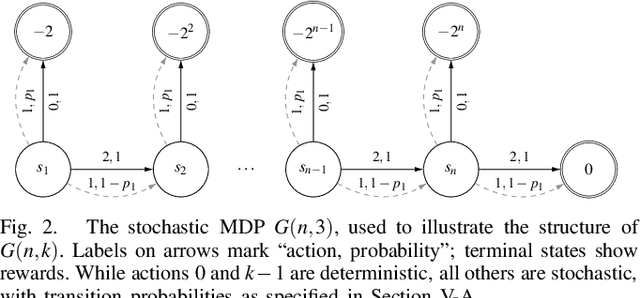

Policy Iteration (PI) is a classical family of algorithms to compute an optimal policy for any given Markov Decision Problem (MDP). The basic idea in PI is to begin with some initial policy and to repeatedly update the policy to one from an improving set, until an optimal policy is reached. Different variants of PI result from the (switching) rule used for improvement. An important theoretical question is how many iterations a specified PI variant will take to terminate as a function of the number of states $n$ and the number of actions $k$ in the input MDP. While there has been considerable progress towards upper-bounding this number, there are fewer results on lower bounds. In particular, existing lower bounds primarily focus on the special case of $k = 2$ actions. We devise lower bounds for $k \geq 3$. Our main result is that a particular variant of PI can take $\Omega(k^{n/2})$ iterations to terminate. We also generalise existing constructions on $2$-action MDPs to scale lower bounds by a factor of $k$ for some common deterministic variants of PI, and by $\log(k)$ for corresponding randomised variants.