 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Challenge to Build Neuro-Symbolic Video Agents
May 20, 2025Modern video understanding systems excel at tasks such as scene classification, object detection, and short video retrieval. However, as video analysis becomes increasingly central to real-world applications, there is a growing need for proactive video agents for the systems that not only interpret video streams but also reason about events and take informed actions. A key obstacle in this direction is temporal reasoning: while deep learning models have made remarkable progress in recognizing patterns within individual frames or short clips, they struggle to understand the sequencing and dependencies of events over time, which is critical for action-driven decision-making. Addressing this limitation demands moving beyond conventional deep learning approaches. We posit that tackling this challenge requires a neuro-symbolic perspective, where video queries are decomposed into atomic events, structured into coherent sequences, and validated against temporal constraints. Such an approach can enhance interpretability, enable structured reasoning, and provide stronger guarantees on system behavior, all key properties for advancing trustworthy video agents. To this end, we present a grand challenge to the research community: developing the next generation of intelligent video agents that integrate three core capabilities: (1) autonomous video search and analysis, (2) seamless real-world interaction, and (3) advanced content generation. By addressing these pillars, we can transition from passive perception to intelligent video agents that reason, predict, and act, pushing the boundaries of video understanding.
Optimization-Free Image Immunization Against Diffusion-Based Editing
Nov 27, 2024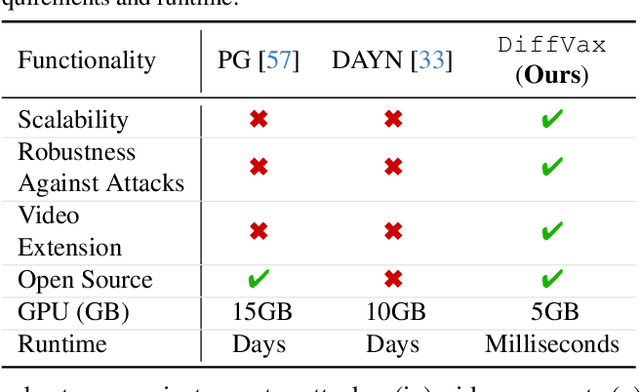
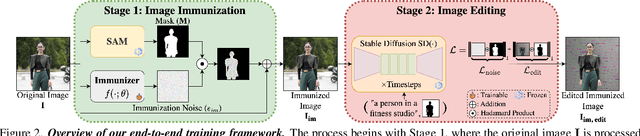


Current image immunization defense techniques against diffusion-based editing embed imperceptible noise in target images to disrupt editing models. However, these methods face scalability challenges, as they require time-consuming re-optimization for each image-taking hours for small batches. To address these challenges, we introduce DiffVax, a scalable, lightweight, and optimization-free framework for image immunization, specifically designed to prevent diffusion-based editing. Our approach enables effective generalization to unseen content, reducing computational costs and cutting immunization time from days to milliseconds-achieving a 250,000x speedup. This is achieved through a loss term that ensures the failure of editing attempts and the imperceptibility of the perturbations. Extensive qualitative and quantitative results demonstrate that our model is scalable, optimization-free, adaptable to various diffusion-based editing tools, robust against counter-attacks, and, for the first time, effectively protects video content from editing. Our code is provided in our project webpage.
SynDiff-AD: Improving Semantic Segmentation and End-to-End Autonomous Driving with Synthetic Data from Latent Diffusion Models
Nov 25, 2024In recent years, significant progress has been made in collecting large-scale datasets to improve segmentation and autonomous driving models. These large-scale datasets are often dominated by common environmental conditions such as "Clear and Day" weather, leading to decreased performance in under-represented conditions like "Rainy and Night". To address this issue, we introduce SynDiff-AD, a novel data augmentation pipeline that leverages diffusion models (DMs) to generate realistic images for such subgroups. SynDiff-AD uses ControlNet-a DM that guides data generation conditioned on semantic maps-along with a novel prompting scheme that generates subgroup-specific, semantically dense prompts. By augmenting datasets with SynDiff-AD, we improve the performance of segmentation models like Mask2Former and SegFormer by up to 1.2% and 2.3% on the Waymo dataset, and up to 1.4% and 0.7% on the DeepDrive dataset, respectively. Additionally, we demonstrate that our SynDiff-AD pipeline enhances the driving performance of end-to-end autonomous driving models, like AIM-2D and AIM-BEV, by up to 20% across diverse environmental conditions in the CARLA autonomous driving simulator, providing a more robust model.
Time Weaver: A Conditional Time Series Generation Model
Mar 05, 2024Imagine generating a city's electricity demand pattern based on weather, the presence of an electric vehicle, and location, which could be used for capacity planning during a winter freeze. Such real-world time series are often enriched with paired heterogeneous contextual metadata (weather, location, etc.). Current approaches to time series generation often ignore this paired metadata, and its heterogeneity poses several practical challenges in adapting existing conditional generation approaches from the image, audio, and video domains to the time series domain. To address this gap, we introduce Time Weaver, a novel diffusion-based model that leverages the heterogeneous metadata in the form of categorical, continuous, and even time-variant variables to significantly improve time series generation. Additionally, we show that naive extensions of standard evaluation metrics from the image to the time series domain are insufficient. These metrics do not penalize conditional generation approaches for their poor specificity in reproducing the metadata-specific features in the generated time series. Thus, we innovate a novel evaluation metric that accurately captures the specificity of conditional generation and the realism of the generated time series. We show that Time Weaver outperforms state-of-the-art benchmarks, such as Generative Adversarial Networks (GANs), by up to 27% in downstream classification tasks on real-world energy, medical, air quality, and traffic data sets.
Data Games: A Game-Theoretic Approach to Swarm Robotic Data Collection
Mar 07, 2023Fleets of networked autonomous vehicles (AVs) collect terabytes of sensory data, which is often transmitted to central servers (the ''cloud'') for training machine learning (ML) models. Ideally, these fleets should upload all their data, especially from rare operating contexts, in order to train robust ML models. However, this is infeasible due to prohibitive network bandwidth and data labeling costs. Instead, we propose a cooperative data sampling strategy where geo-distributed AVs collaborate to collect a diverse ML training dataset in the cloud. Since the AVs have a shared objective but minimal information about each other's local data distribution and perception model, we can naturally cast cooperative data collection as an $N$-player mathematical game. We show that our cooperative sampling strategy uses minimal information to converge to a centralized oracle policy with complete information about all AVs. Moreover, we theoretically characterize the performance benefits of our game-theoretic strategy compared to greedy sampling. Finally, we experimentally demonstrate that our method outperforms standard benchmarks by up to $21.9\%$ on 4 perception datasets, including for autonomous driving in adverse weather conditions. Crucially, our experimental results on real-world datasets closely align with our theoretical guarantees.