 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Chain-of-Thought Really Not Explainability? Chain-of-Thought Can Be Faithful without Hint Verbalization
Dec 28, 2025Recent work, using the Biasing Features metric, labels a CoT as unfaithful if it omits a prompt-injected hint that affected the prediction. We argue this metric confuses unfaithfulness with incompleteness, the lossy compression needed to turn distributed transformer computation into a linear natural language narrative. On multi-hop reasoning tasks with Llama-3 and Gemma-3, many CoTs flagged as unfaithful by Biasing Features are judged faithful by other metrics, exceeding 50% in some models. With a new faithful@k metric, we show that larger inference-time token budgets greatly increase hint verbalization (up to 90% in some settings), suggesting much apparent unfaithfulness is due to tight token limits. Using Causal Mediation Analysis, we further show that even non-verbalized hints can causally mediate prediction changes through the CoT. We therefore caution against relying solely on hint-based evaluations and advocate a broader interpretability toolkit, including causal mediation and corruption-based metrics.
A Causal Lens for Evaluating Faithfulness Metrics
Feb 26, 2025



Large Language Models (LLMs) offer natural language explanations as an alternative to feature attribution methods for model interpretability. However, despite their plausibility, they may not reflect the model's internal reasoning faithfully, which is crucial for understanding the model's true decision-making processes. Although several faithfulness metrics have been proposed, a unified evaluation framework remains absent. To address this gap, we present Causal Diagnosticity, a framework to evaluate faithfulness metrics for natural language explanations. Our framework employs the concept of causal diagnosticity, and uses model-editing methods to generate faithful-unfaithful explanation pairs. Our benchmark includes four tasks: fact-checking, analogy, object counting, and multi-hop reasoning. We evaluate a variety of faithfulness metrics, including post-hoc explanation and chain-of-thought-based methods. We find that all tested faithfulness metrics often fail to surpass a random baseline. Our work underscores the need for improved metrics and more reliable interpretability methods in LLMs.
INTERACT: Enabling Interactive, Question-Driven Learning in Large Language Models
Dec 16, 2024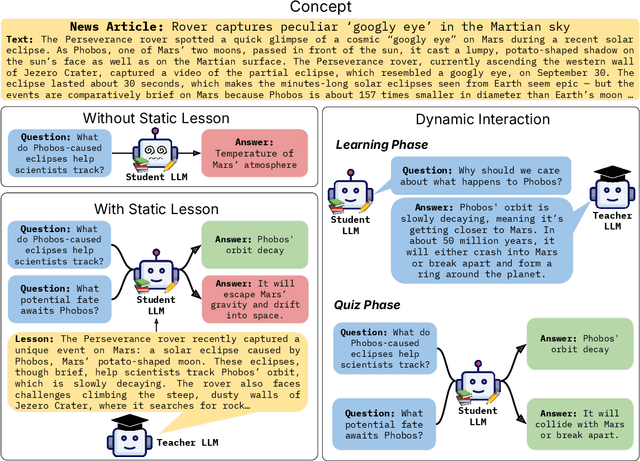

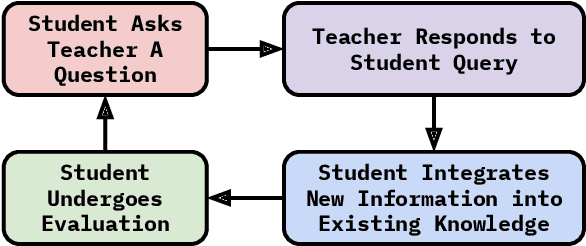
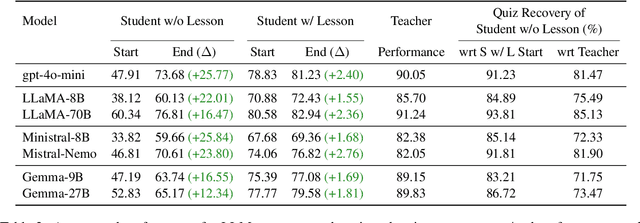
Large language models (LLMs) excel at answering questions but remain passive learners--absorbing static data without the ability to question and refine knowledge. This paper explores how LLMs can transition to interactive, question-driven learning through student-teacher dialogues. We introduce INTERACT (INTEReractive Learning for Adaptive Concept Transfer), a framework in which a "student" LLM engages a "teacher" LLM through iterative inquiries to acquire knowledge across 1,347 contexts, including song lyrics, news articles, movie plots, academic papers, and images. Our experiments show that across a wide range of scenarios and LLM architectures, interactive learning consistently enhances performance, achieving up to a 25% improvement, with 'cold-start' student models matching static learning baselines in as few as five dialogue turns. Interactive setups can also mitigate the disadvantages of weaker teachers, showcasing the robustness of question-driven learning.
Optimization-Free Image Immunization Against Diffusion-Based Editing
Nov 27, 2024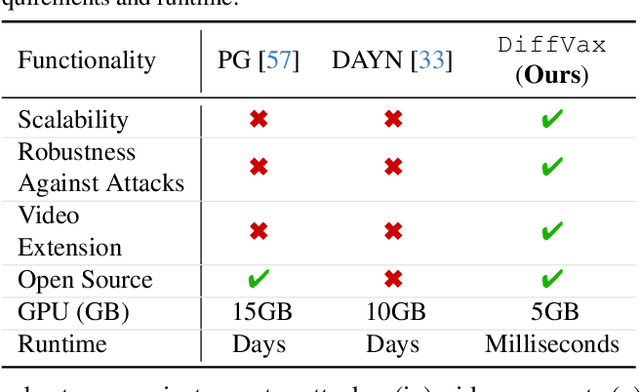
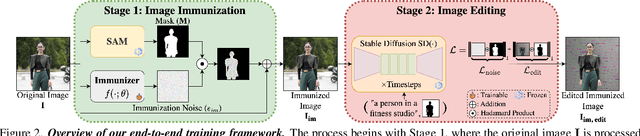


Current image immunization defense techniques against diffusion-based editing embed imperceptible noise in target images to disrupt editing models. However, these methods face scalability challenges, as they require time-consuming re-optimization for each image-taking hours for small batches. To address these challenges, we introduce DiffVax, a scalable, lightweight, and optimization-free framework for image immunization, specifically designed to prevent diffusion-based editing. Our approach enables effective generalization to unseen content, reducing computational costs and cutting immunization time from days to milliseconds-achieving a 250,000x speedup. This is achieved through a loss term that ensures the failure of editing attempts and the imperceptibility of the perturbations. Extensive qualitative and quantitative results demonstrate that our model is scalable, optimization-free, adaptable to various diffusion-based editing tools, robust against counter-attacks, and, for the first time, effectively protects video content from editing. Our code is provided in our project webpage.
Fuse to Forget: Bias Reduction and Selective Memorization through Model Fusion
Nov 13, 2023



Model fusion research aims to aggregate the knowledge of multiple models to enhance performance by combining their weights. In this work, we study the inverse, investigating whether and how can model fusion interfere and reduce unwanted knowledge. We delve into the effects of model fusion on the evolution of learned shortcuts, social biases, and memorization capabilities in fine-tuned language models. Through several experiments covering text classification and generation tasks, our analysis highlights that shared knowledge among models is usually enhanced during model fusion, while unshared knowledge is usually lost or forgotten. Based on this observation, we demonstrate the potential of model fusion as a debiasing tool and showcase its efficacy in addressing privacy concerns associated with language models.
MaNtLE: Model-agnostic Natural Language Explainer
May 22, 2023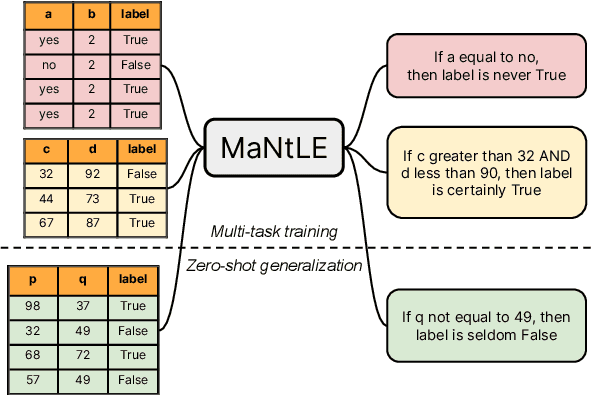


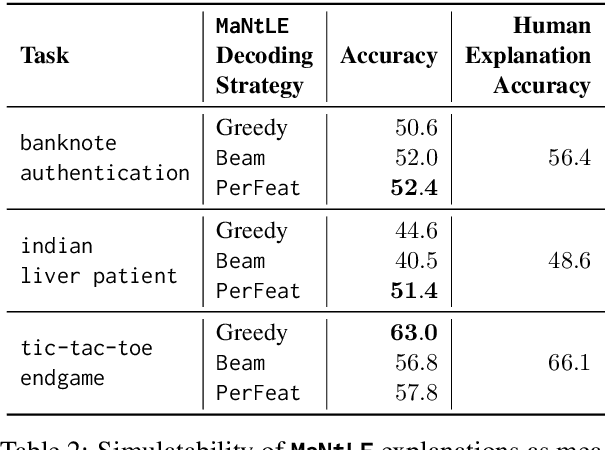
Understanding the internal reasoning behind the predictions of machine learning systems is increasingly vital, given their rising adoption and acceptance. While previous approaches, such as LIME, generate algorithmic explanations by attributing importance to input features for individual examples, recent research indicates that practitioners prefer examining language explanations that explain sub-groups of examples. In this paper, we introduce MaNtLE, a model-agnostic natural language explainer that analyzes multiple classifier predictions and generates faithful natural language explanations of classifier rationale for structured classification tasks. MaNtLE uses multi-task training on thousands of synthetic classification tasks to generate faithful explanations. Simulated user studies indicate that, on average, MaNtLE-generated explanations are at least 11% more faithful compared to LIME and Anchors explanations across three tasks. Human evaluations demonstrate that users can better predict model behavior using explanations from MaNtLE compared to other techniques
A Multilingual Perspective Towards the Evaluation of Attribution Methods in Natural Language Inference
Apr 11, 2022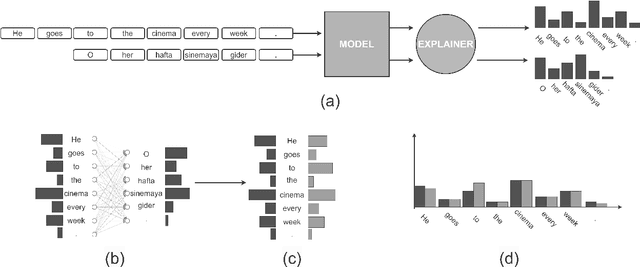
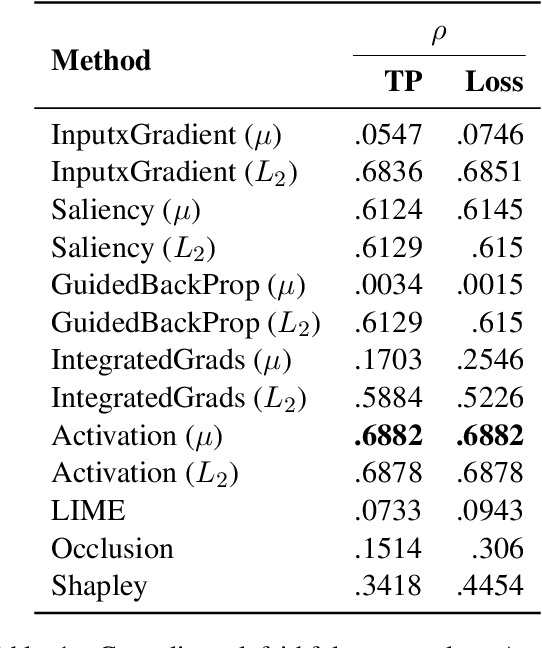
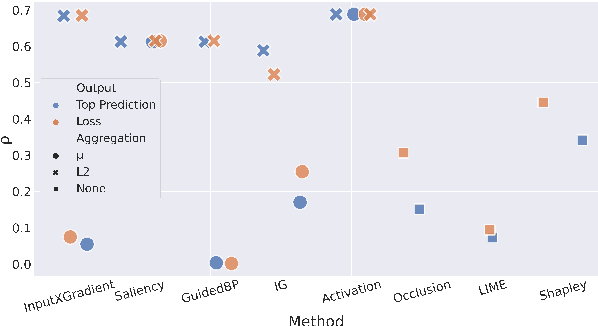

Most evaluations of attribution methods focus on the English language. In this work, we present a multilingual approach for evaluating attribution methods for the Natural Language Inference (NLI) task in terms of plausibility and faithfulness properties. First, we introduce a novel cross-lingual strategy to measure faithfulness based on word alignments, which eliminates the potential downsides of erasure-based evaluations. We then perform a comprehensive evaluation of attribution methods, considering different output mechanisms and aggregation methods. Finally, we augment the XNLI dataset with highlight-based explanations, providing a multilingual NLI dataset with highlights, which may support future exNLP studies. Our results show that attribution methods performing best for plausibility and faithfulness are different.