 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINTERACT: Enabling Interactive, Question-Driven Learning in Large Language Models
Dec 16, 2024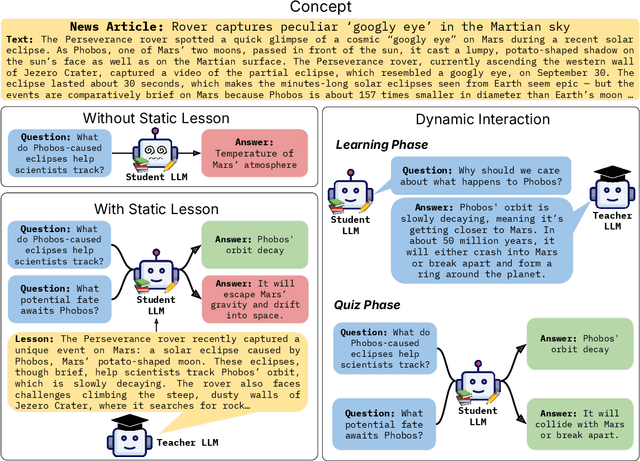

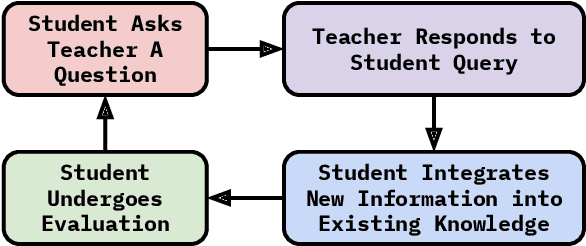
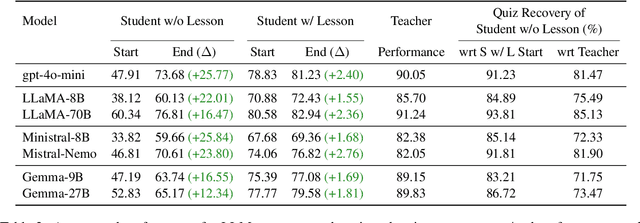
Large language models (LLMs) excel at answering questions but remain passive learners--absorbing static data without the ability to question and refine knowledge. This paper explores how LLMs can transition to interactive, question-driven learning through student-teacher dialogues. We introduce INTERACT (INTEReractive Learning for Adaptive Concept Transfer), a framework in which a "student" LLM engages a "teacher" LLM through iterative inquiries to acquire knowledge across 1,347 contexts, including song lyrics, news articles, movie plots, academic papers, and images. Our experiments show that across a wide range of scenarios and LLM architectures, interactive learning consistently enhances performance, achieving up to a 25% improvement, with 'cold-start' student models matching static learning baselines in as few as five dialogue turns. Interactive setups can also mitigate the disadvantages of weaker teachers, showcasing the robustness of question-driven learning.
DISCERN: Decoding Systematic Errors in Natural Language for Text Classifiers
Oct 29, 2024



Despite their high predictive accuracies, current machine learning systems often exhibit systematic biases stemming from annotation artifacts or insufficient support for certain classes in the dataset. Recent work proposes automatic methods for identifying and explaining systematic biases using keywords. We introduce DISCERN, a framework for interpreting systematic biases in text classifiers using language explanations. DISCERN iteratively generates precise natural language descriptions of systematic errors by employing an interactive loop between two large language models. Finally, we use the descriptions to improve classifiers by augmenting classifier training sets with synthetically generated instances or annotated examples via active learning. On three text-classification datasets, we demonstrate that language explanations from our framework induce consistent performance improvements that go beyond what is achievable with exemplars of systematic bias. Finally, in human evaluations, we show that users can interpret systematic biases more effectively (by over 25% relative) and efficiently when described through language explanations as opposed to cluster exemplars.
SocialGaze: Improving the Integration of Human Social Norms in Large Language Models
Oct 11, 2024
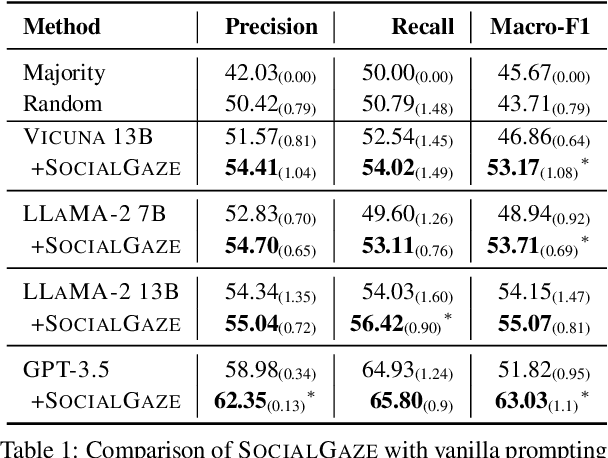
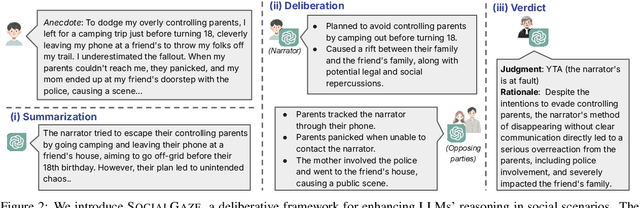
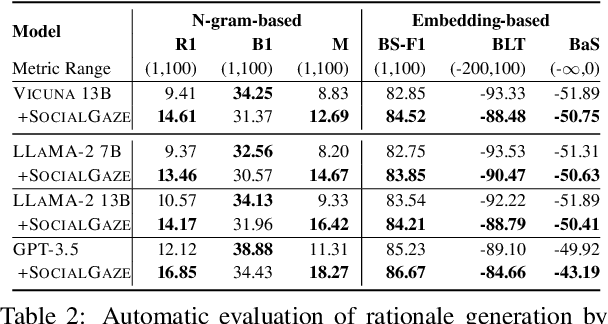
While much research has explored enhancing the reasoning capabilities of large language models (LLMs) in the last few years, there is a gap in understanding the alignment of these models with social values and norms. We introduce the task of judging social acceptance. Social acceptance requires models to judge and rationalize the acceptability of people's actions in social situations. For example, is it socially acceptable for a neighbor to ask others in the community to keep their pets indoors at night? We find that LLMs' understanding of social acceptance is often misaligned with human consensus. To alleviate this, we introduce SocialGaze, a multi-step prompting framework, in which a language model verbalizes a social situation from multiple perspectives before forming a judgment. Our experiments demonstrate that the SocialGaze approach improves the alignment with human judgments by up to 11 F1 points with the GPT-3.5 model. We also identify biases and correlations in LLMs in assigning blame that is related to features such as the gender (males are significantly more likely to be judged unfairly) and age (LLMs are more aligned with humans for older narrators).
Leveraging Multiple Teachers for Test-Time Adaptation of Language-Guided Classifiers
Nov 13, 2023Recent approaches have explored language-guided classifiers capable of classifying examples from novel tasks when provided with task-specific natural language explanations, instructions or prompts (Sanh et al., 2022; R. Menon et al., 2022). While these classifiers can generalize in zero-shot settings, their task performance often varies substantially between different language explanations in unpredictable ways (Lu et al., 2022; Gonen et al., 2022). Also, current approaches fail to leverage unlabeled examples that may be available in many scenarios. Here, we introduce TALC, a framework that uses data programming to adapt a language-guided classifier for a new task during inference when provided with explanations from multiple teachers and unlabeled test examples. Our results show that TALC consistently outperforms a competitive baseline from prior work by an impressive 9.3% (relative improvement). Further, we demonstrate the robustness of TALC to variations in the quality and quantity of provided explanations, highlighting its potential in scenarios where learning from multiple teachers or a crowd is involved. Our code is available at: https://github.com/WeiKangda/TALC.git.
Pragmatic Reasoning Unlocks Quantifier Semantics for Foundation Models
Nov 08, 2023



Generalized quantifiers (e.g., few, most) are used to indicate the proportions predicates are satisfied (for example, some apples are red). One way to interpret quantifier semantics is to explicitly bind these satisfactions with percentage scopes (e.g., 30%-40% of apples are red). This approach can be helpful for tasks like logic formalization and surface-form quantitative reasoning (Gordon and Schubert, 2010; Roy et al., 2015). However, it remains unclear if recent foundation models possess this ability, as they lack direct training signals. To explore this, we introduce QuRe, a crowd-sourced dataset of human-annotated generalized quantifiers in Wikipedia sentences featuring percentage-equipped predicates. We explore quantifier comprehension in language models using PRESQUE, a framework that combines natural language inference and the Rational Speech Acts framework. Experimental results on the HVD dataset and QuRe illustrate that PRESQUE, employing pragmatic reasoning, performs 20% better than a literal reasoning baseline when predicting quantifier percentage scopes, with no additional training required.
MaNtLE: Model-agnostic Natural Language Explainer
May 22, 2023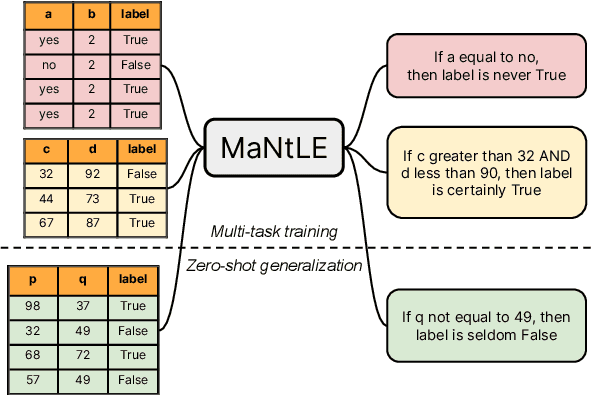


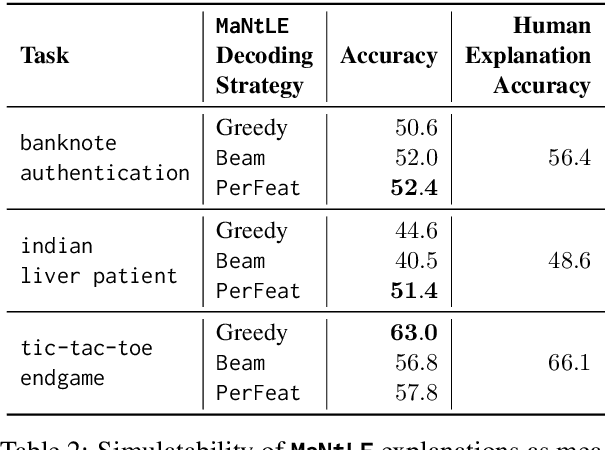
Understanding the internal reasoning behind the predictions of machine learning systems is increasingly vital, given their rising adoption and acceptance. While previous approaches, such as LIME, generate algorithmic explanations by attributing importance to input features for individual examples, recent research indicates that practitioners prefer examining language explanations that explain sub-groups of examples. In this paper, we introduce MaNtLE, a model-agnostic natural language explainer that analyzes multiple classifier predictions and generates faithful natural language explanations of classifier rationale for structured classification tasks. MaNtLE uses multi-task training on thousands of synthetic classification tasks to generate faithful explanations. Simulated user studies indicate that, on average, MaNtLE-generated explanations are at least 11% more faithful compared to LIME and Anchors explanations across three tasks. Human evaluations demonstrate that users can better predict model behavior using explanations from MaNtLE compared to other techniques