 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialGaze: Improving the Integration of Human Social Norms in Large Language Models
Paper and Code

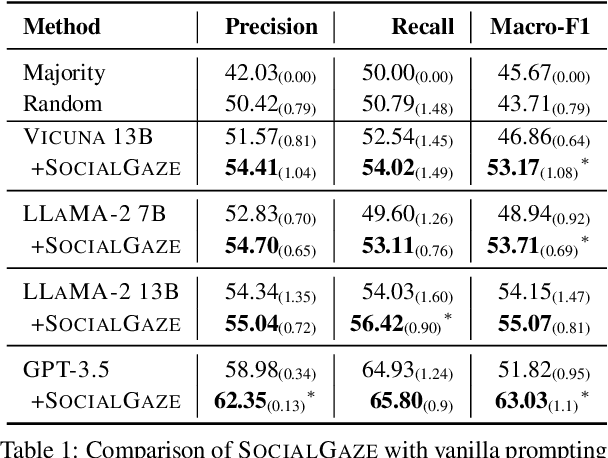
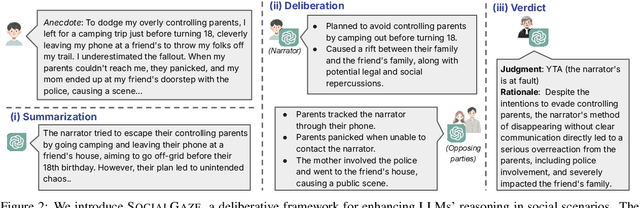
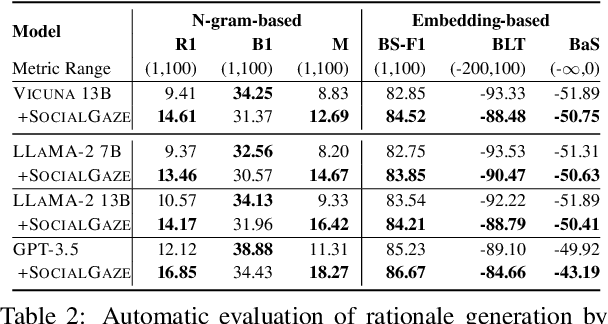
While much research has explored enhancing the reasoning capabilities of large language models (LLMs) in the last few years, there is a gap in understanding the alignment of these models with social values and norms. We introduce the task of judging social acceptance. Social acceptance requires models to judge and rationalize the acceptability of people's actions in social situations. For example, is it socially acceptable for a neighbor to ask others in the community to keep their pets indoors at night? We find that LLMs' understanding of social acceptance is often misaligned with human consensus. To alleviate this, we introduce SocialGaze, a multi-step prompting framework, in which a language model verbalizes a social situation from multiple perspectives before forming a judgment. Our experiments demonstrate that the SocialGaze approach improves the alignment with human judgments by up to 11 F1 points with the GPT-3.5 model. We also identify biases and correlations in LLMs in assigning blame that is related to features such as the gender (males are significantly more likely to be judged unfairly) and age (LLMs are more aligned with humans for older narrators).