 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialGaze: Improving the Integration of Human Social Norms in Large Language Models
Oct 11, 2024
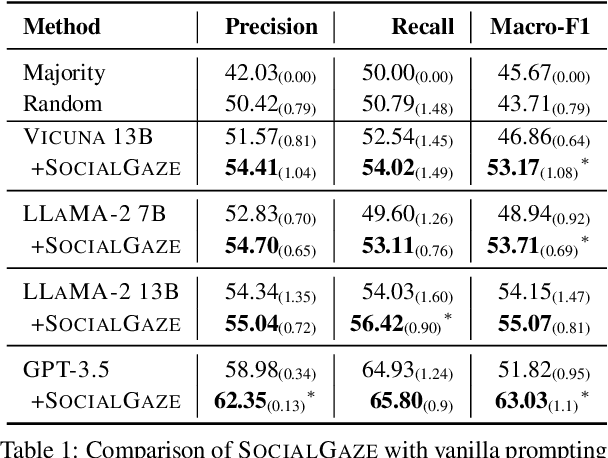
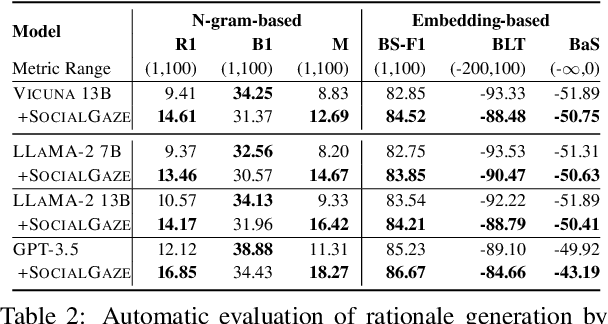
While much research has explored enhancing the reasoning capabilities of large language models (LLMs) in the last few years, there is a gap in understanding the alignment of these models with social values and norms. We introduce the task of judging social acceptance. Social acceptance requires models to judge and rationalize the acceptability of people's actions in social situations. For example, is it socially acceptable for a neighbor to ask others in the community to keep their pets indoors at night? We find that LLMs' understanding of social acceptance is often misaligned with human consensus. To alleviate this, we introduce SocialGaze, a multi-step prompting framework, in which a language model verbalizes a social situation from multiple perspectives before forming a judgment. Our experiments demonstrate that the SocialGaze approach improves the alignment with human judgments by up to 11 F1 points with the GPT-3.5 model. We also identify biases and correlations in LLMs in assigning blame that is related to features such as the gender (males are significantly more likely to be judged unfairly) and age (LLMs are more aligned with humans for older narrators).
Exploring Safety-Utility Trade-Offs in Personalized Language Models
Jun 17, 2024



As large language models (LLMs) become increasingly integrated into daily applications, it is essential to ensure they operate fairly across diverse user demographics. In this work, we show that LLMs suffer from personalization bias, where their performance is impacted when they are personalized to a user's identity. We quantify personalization bias by evaluating the performance of LLMs along two axes - safety and utility. We measure safety by examining how benign LLM responses are to unsafe prompts with and without personalization. We measure utility by evaluating the LLM's performance on various tasks, including general knowledge, mathematical abilities, programming, and reasoning skills. We find that various LLMs, ranging from open-source models like Llama (Touvron et al., 2023) and Mistral (Jiang et al., 2023) to API-based ones like GPT-3.5 and GPT-4o (Ouyang et al., 2022), exhibit significant variance in performance in terms of safety-utility trade-offs depending on the user's identity. Finally, we discuss several strategies to mitigate personalization bias using preference tuning and prompt-based defenses.
Towards Inter-character Relationship-driven Story Generation
Nov 01, 2022In this paper, we introduce the task of modeling interpersonal relationships for story generation. For addressing this task, we propose Relationships as Latent Variables for Story Generation, (ReLiSt). ReLiSt generates stories sentence by sentence and has two major components - a relationship selector and a story continuer. The relationship selector specifies a latent variable to pick the relationship to exhibit in the next sentence and the story continuer generates the next sentence while expressing the selected relationship in a coherent way. Our automatic and human evaluations demonstrate that ReLiSt is able to generate stories with relationships that are more faithful to desired relationships while maintaining the content quality. The relationship assignments to sentences during inference bring interpretability to ReLiSt.
A Syntax Aware BERT for Identifying Well-Formed Queries in a Curriculum Framework
Aug 21, 2022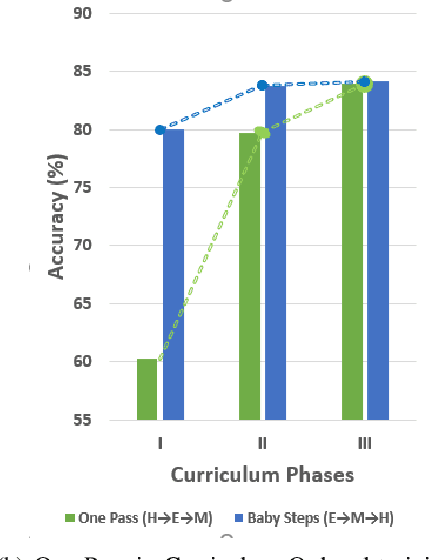
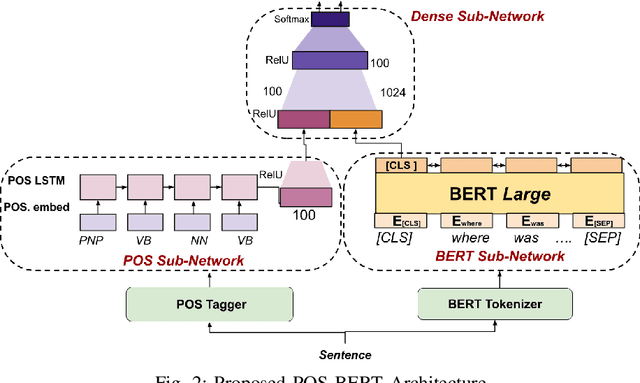

A well formed query is defined as a query which is formulated in the manner of an inquiry, and with correct interrogatives, spelling and grammar. While identifying well formed queries is an important task, few works have attempted to address it. In this paper we propose transformer based language model - Bidirectional Encoder Representations from Transformers (BERT) to this task. We further imbibe BERT with parts-of-speech information inspired from earlier works. Furthermore, we also train the model in multiple curriculum settings for improvement in performance. Curriculum Learning over the task is experimented with Baby Steps and One Pass techniques. Proposed architecture performs exceedingly well on the task. The best approach achieves accuracy of 83.93%, outperforming previous state-of-the-art at 75.0% and reaching close to the approximate human upper bound of 88.4%.
Analyzing Curriculum Learning for Sentiment Analysis along Task Difficulty, Pacing and Visualization Axes
Mar 03, 2021



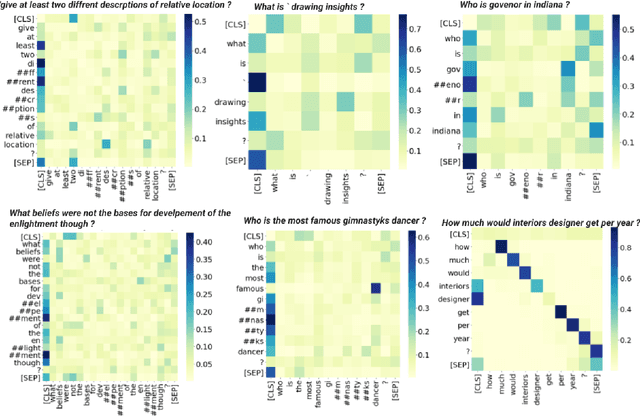
While Curriculum Learning (CL) has recently gained traction in Natural language Processing Tasks, it is still not adequately analyzed. Previous works only show their effectiveness but fail short to explain and interpret the internal workings fully. In this paper, we analyze curriculum learning in sentiment analysis along multiple axes. Some of these axes have been proposed by earlier works that need more in-depth study. Such analysis requires understanding where curriculum learning works and where it does not. Our axes of analysis include Task difficulty on CL, comparing CL pacing techniques, and qualitative analysis by visualizing the movement of attention scores in the model as curriculum phases progress. We find that curriculum learning works best for difficult tasks and may even lead to a decrement in performance for tasks with higher performance without curriculum learning. We see that One-Pass curriculum strategies suffer from catastrophic forgetting and attention movement visualization within curriculum pacing. This shows that curriculum learning breaks down the challenging main task into easier sub-tasks solved sequentially.
WER-BERT: Automatic WER Estimation with BERT in a Balanced Ordinal Classification Paradigm
Feb 13, 2021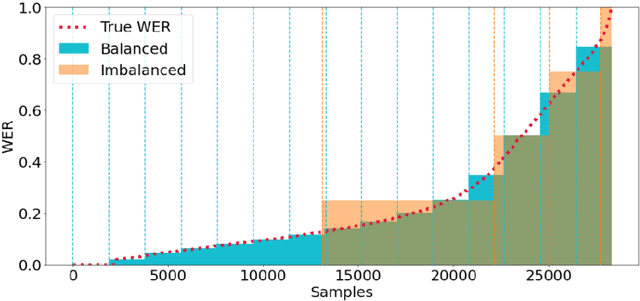
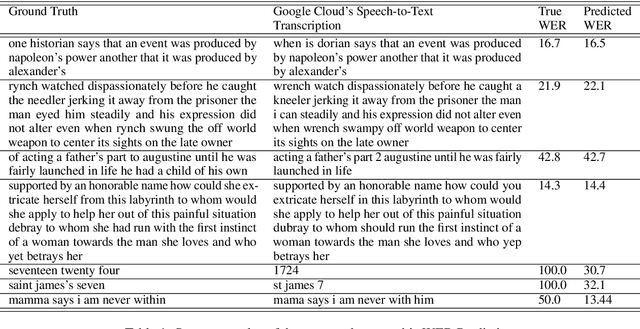
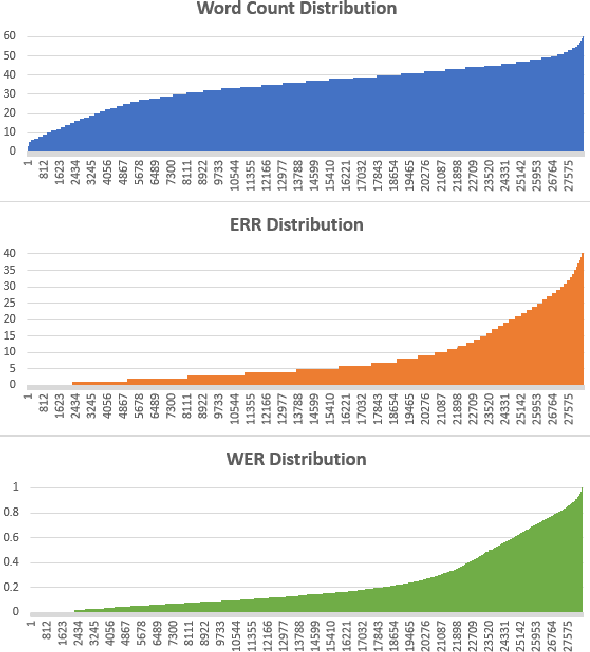
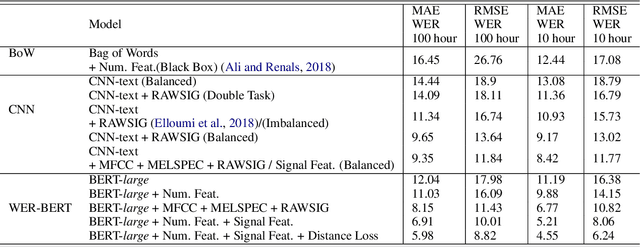
Automatic Speech Recognition (ASR) systems are evaluated using Word Error Rate (WER), which is calculated by comparing the number of errors between the ground truth and the transcription of the ASR system. This calculation, however, requires manual transcription of the speech signal to obtain the ground truth. Since transcribing audio signals is a costly process, Automatic WER Evaluation (e-WER) methods have been developed to automatically predict the WER of a speech system by only relying on the transcription and the speech signal features. While WER is a continuous variable, previous works have shown that positing e-WER as a classification problem is more effective than regression. However, while converting to a classification setting, these approaches suffer from heavy class imbalance. In this paper, we propose a new balanced paradigm for e-WER in a classification setting. Within this paradigm, we also propose WER-BERT, a BERT based architecture with speech features for e-WER. Furthermore, we introduce a distance loss function to tackle the ordinal nature of e-WER classification. The proposed approach and paradigm are evaluated on the Librispeech dataset and a commercial (black box) ASR system, Google Cloud's Speech-to-Text API. The results and experiments demonstrate that WER-BERT establishes a new state-of-the-art in automatic WER estimation.