 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Curriculum Learning for Sentiment Analysis along Task Difficulty, Pacing and Visualization Axes
Mar 03, 2021



While Curriculum Learning (CL) has recently gained traction in Natural language Processing Tasks, it is still not adequately analyzed. Previous works only show their effectiveness but fail short to explain and interpret the internal workings fully. In this paper, we analyze curriculum learning in sentiment analysis along multiple axes. Some of these axes have been proposed by earlier works that need more in-depth study. Such analysis requires understanding where curriculum learning works and where it does not. Our axes of analysis include Task difficulty on CL, comparing CL pacing techniques, and qualitative analysis by visualizing the movement of attention scores in the model as curriculum phases progress. We find that curriculum learning works best for difficult tasks and may even lead to a decrement in performance for tasks with higher performance without curriculum learning. We see that One-Pass curriculum strategies suffer from catastrophic forgetting and attention movement visualization within curriculum pacing. This shows that curriculum learning breaks down the challenging main task into easier sub-tasks solved sequentially.
A SentiWordNet Strategy for Curriculum Learning in Sentiment Analysis
May 10, 2020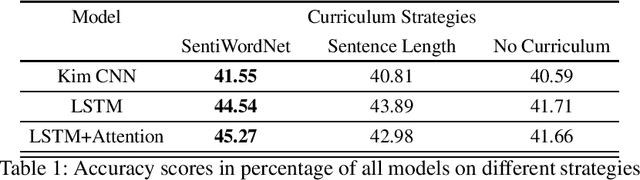
Curriculum Learning (CL) is the idea that learning on a training set sequenced or ordered in a manner where samples range from easy to difficult, results in an increment in performance over otherwise random ordering. The idea parallels cognitive science's theory of how human brains learn, and that learning a difficult task can be made easier by phrasing it as a sequence of easy to difficult tasks. This idea has gained a lot of traction in machine learning and image processing for a while and recently in Natural Language Processing (NLP). In this paper, we apply the ideas of curriculum learning, driven by SentiWordNet in a sentiment analysis setting. In this setting, given a text segment, our aim is to extract its sentiment or polarity. SentiWordNet is a lexical resource with sentiment polarity annotations. By comparing performance with other curriculum strategies and with no curriculum, the effectiveness of the proposed strategy is presented. Convolutional, Recurrence, and Attention-based architectures are employed to assess this improvement. The models are evaluated on a standard sentiment dataset, Stanford Sentiment Treebank.
Hindi Question Generation Using Dependency Structures
Jun 20, 2019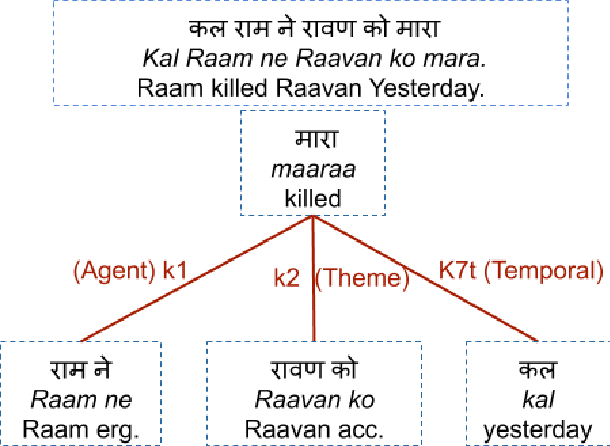

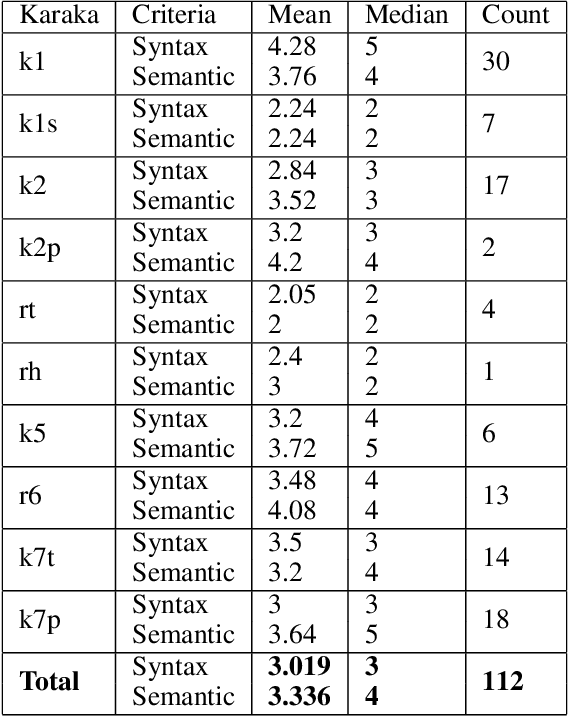
Hindi question answering systems suffer from a lack of data. To address the same, this paper presents an approach towards automatic question generation. We present a rule-based system for question generation in Hindi by formalizing question transformation methods based on karaka-dependency theory. We use a Hindi dependency parser to mark the karaka roles and use IndoWordNet a Hindi ontology to detect the semantic category of the karaka role heads to generate the interrogatives. We analyze how one sentence can have multiple generations from the same karaka role's rule. The generations are manually annotated by multiple annotators on a semantic and syntactic scale for evaluation. Further, we constrain our generation with the help of various semantic and syntactic filters so as to improve the generation quality. Using these methods, we are able to generate diverse questions, significantly more than number of sentences fed to the system.