 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Domain Adaptation through Elastic Weight Consolidation for Sentiment Analysis
Jul 04, 2020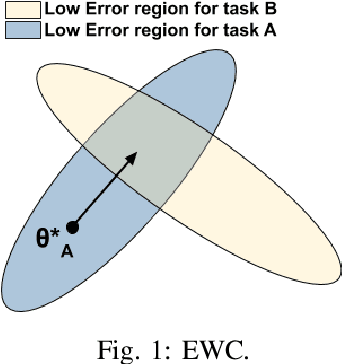
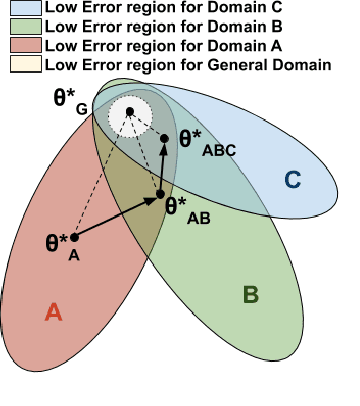
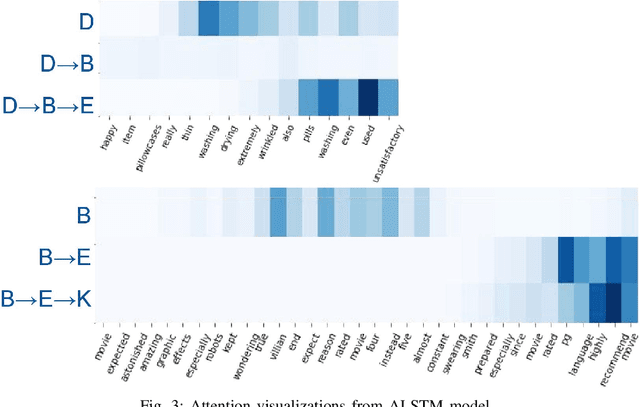
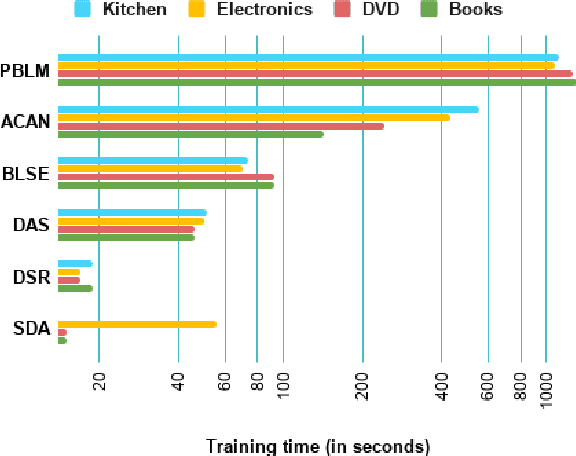
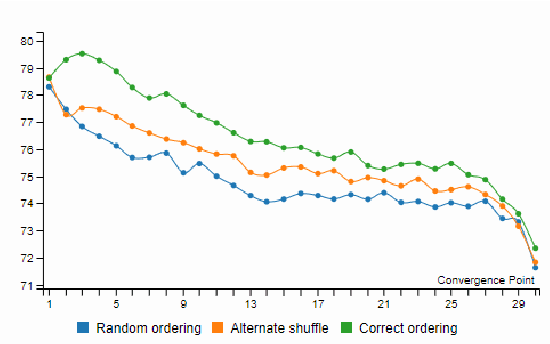
Elastic Weight Consolidation (EWC) is a technique used in overcoming catastrophic forgetting between successive tasks trained on a neural network. We use this phenomenon of information sharing between tasks for domain adaptation. Training data for tasks such as sentiment analysis (SA) may not be fairly represented across multiple domains. Domain Adaptation (DA) aims to build algorithms that leverage information from source domains to facilitate performance on an unseen target domain. We propose a model-independent framework - Sequential Domain Adaptation (SDA). SDA draws on EWC for training on successive source domains to move towards a general domain solution, thereby solving the problem of domain adaptation. We test SDA on convolutional, recurrent, and attention-based architectures. Our experiments show that the proposed framework enables simple architectures such as CNNs to outperform complex state-of-the-art models in domain adaptation of SA. In addition, we observe that the effectiveness of a harder first Anti-Curriculum ordering of source domains leads to maximum performance.
A SentiWordNet Strategy for Curriculum Learning in Sentiment Analysis
May 10, 2020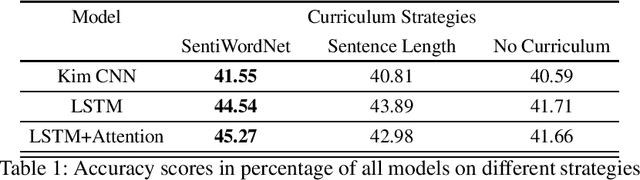
Curriculum Learning (CL) is the idea that learning on a training set sequenced or ordered in a manner where samples range from easy to difficult, results in an increment in performance over otherwise random ordering. The idea parallels cognitive science's theory of how human brains learn, and that learning a difficult task can be made easier by phrasing it as a sequence of easy to difficult tasks. This idea has gained a lot of traction in machine learning and image processing for a while and recently in Natural Language Processing (NLP). In this paper, we apply the ideas of curriculum learning, driven by SentiWordNet in a sentiment analysis setting. In this setting, given a text segment, our aim is to extract its sentiment or polarity. SentiWordNet is a lexical resource with sentiment polarity annotations. By comparing performance with other curriculum strategies and with no curriculum, the effectiveness of the proposed strategy is presented. Convolutional, Recurrence, and Attention-based architectures are employed to assess this improvement. The models are evaluated on a standard sentiment dataset, Stanford Sentiment Treebank.
A Position Aware Decay Weighted Network for Aspect based Sentiment Analysis
May 03, 2020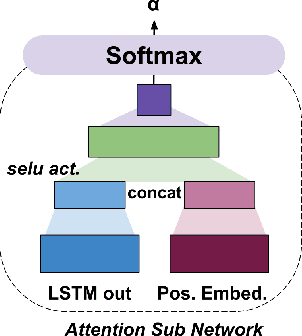
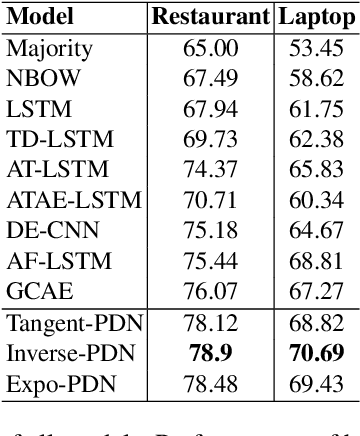
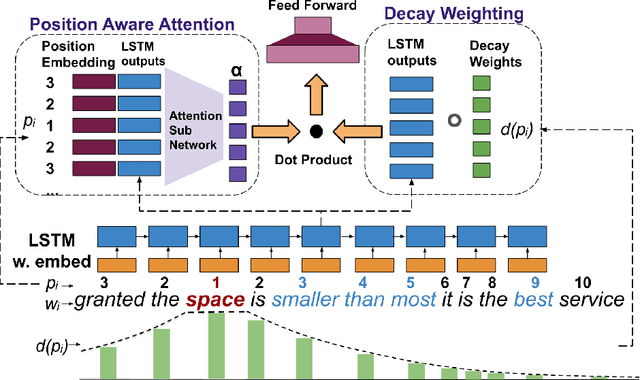
Aspect Based Sentiment Analysis (ABSA) is the task of identifying sentiment polarity of a text given another text segment or aspect. In ABSA, a text can have multiple sentiments depending upon each aspect. Aspect Term Sentiment Analysis (ATSA) is a subtask of ABSA, in which aspect terms are contained within the given sentence. Most of the existing approaches proposed for ATSA, incorporate aspect information through a different subnetwork thereby overlooking the advantage of aspect terms' presence within the sentence. In this paper, we propose a model that leverages the positional information of the aspect. The proposed model introduces a decay mechanism based on position. This decay function mandates the contribution of input words for ABSA. The contribution of a word declines as farther it is positioned from the aspect terms in the sentence. The performance is measured on two standard datasets from SemEval 2014 Task 4. In comparison with recent architectures, the effectiveness of the proposed model is demonstrated.
Sequential Learning of Convolutional Features for Effective Text Classification
Sep 12, 2019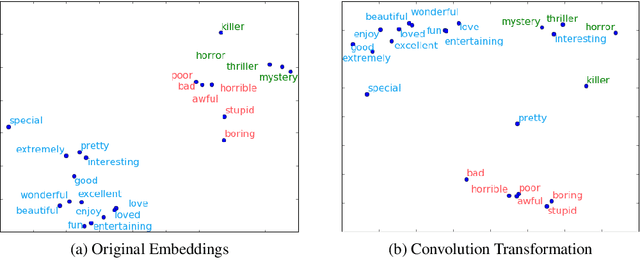
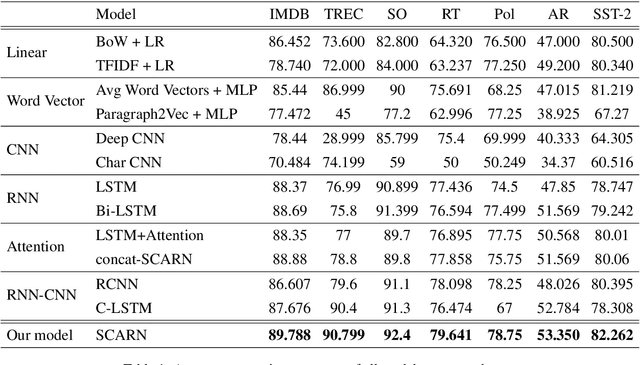
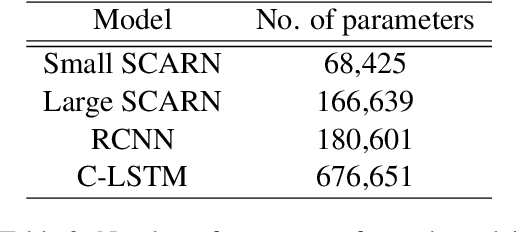
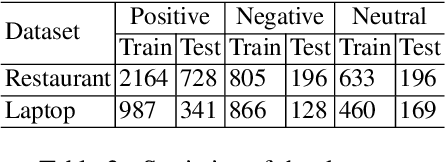
Text classification has been one of the major problems in natural language processing. With the advent of deep learning, convolutional neural network (CNN) has been a popular solution to this task. However, CNNs which were first proposed for images, face many crucial challenges in the context of text processing, namely in their elementary blocks: convolution filters and max pooling. These challenges have largely been overlooked by the most existing CNN models proposed for text classification. In this paper, we present an experimental study on the fundamental blocks of CNNs in text categorization. Based on this critique, we propose Sequential Convolutional Attentive Recurrent Network (SCARN). The proposed SCARN model utilizes both the advantages of recurrent and convolutional structures efficiently in comparison to previously proposed recurrent convolutional models. We test our model on different text classification datasets across tasks like sentiment analysis and question classification. Extensive experiments establish that SCARN outperforms other recurrent convolutional architectures with significantly less parameters. Furthermore, SCARN achieves better performance compared to equally large various deep CNN and LSTM architectures.
Hindi Question Generation Using Dependency Structures
Jun 20, 2019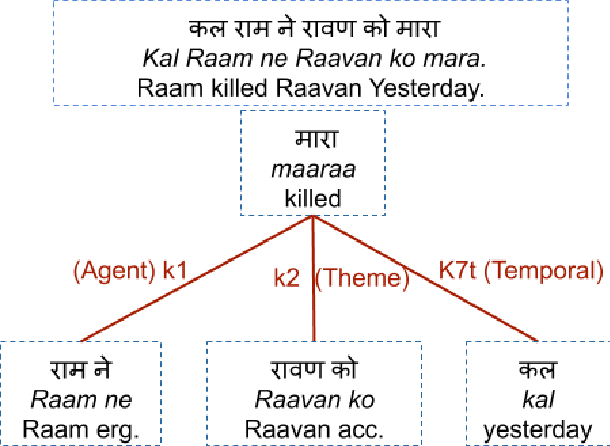

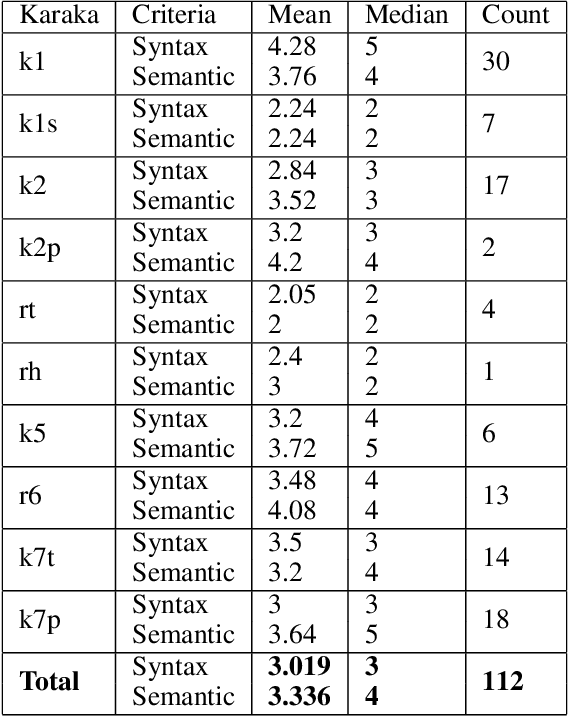
Hindi question answering systems suffer from a lack of data. To address the same, this paper presents an approach towards automatic question generation. We present a rule-based system for question generation in Hindi by formalizing question transformation methods based on karaka-dependency theory. We use a Hindi dependency parser to mark the karaka roles and use IndoWordNet a Hindi ontology to detect the semantic category of the karaka role heads to generate the interrogatives. We analyze how one sentence can have multiple generations from the same karaka role's rule. The generations are manually annotated by multiple annotators on a semantic and syntactic scale for evaluation. Further, we constrain our generation with the help of various semantic and syntactic filters so as to improve the generation quality. Using these methods, we are able to generate diverse questions, significantly more than number of sentences fed to the system.
Gated Convolutional Neural Networks for Domain Adaptation
May 16, 2019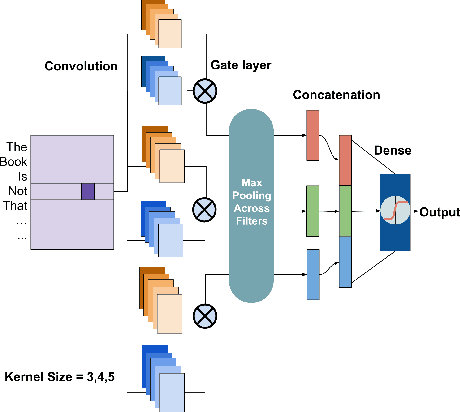
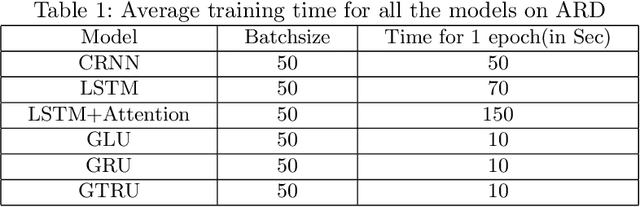
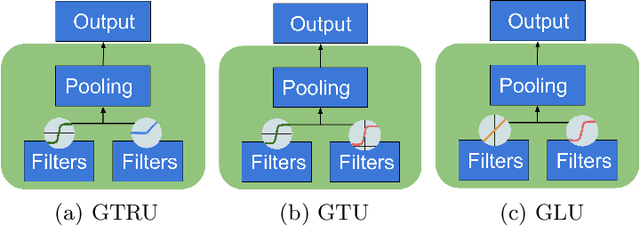
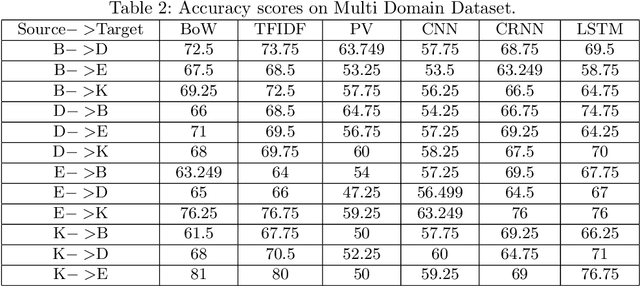
Domain Adaptation explores the idea of how to maximize performance on a target domain, distinct from source domain, upon which the classifier was trained. This idea has been explored for the task of sentiment analysis extensively. The training of reviews pertaining to one domain and evaluation on another domain is widely studied for modeling a domain independent algorithm. This further helps in understanding correlation between domains. In this paper, we show that Gated Convolutional Neural Networks (GCN) perform effectively at learning sentiment analysis in a manner where domain dependant knowledge is filtered out using its gates. We perform our experiments on multiple gate architectures: Gated Tanh ReLU Unit (GTRU), Gated Tanh Unit (GTU) and Gated Linear Unit (GLU). Extensive experimentation on two standard datasets relevant to the task, reveal that training with Gated Convolutional Neural Networks give significantly better performance on target domains than regular convolution and recurrent based architectures. While complex architectures like attention, filter domain specific knowledge as well, their complexity order is remarkably high as compared to gated architectures. GCNs rely on convolution hence gaining an upper hand through parallelization.
Effectiveness of Self Normalizing Neural Networks for Text Classification
May 03, 2019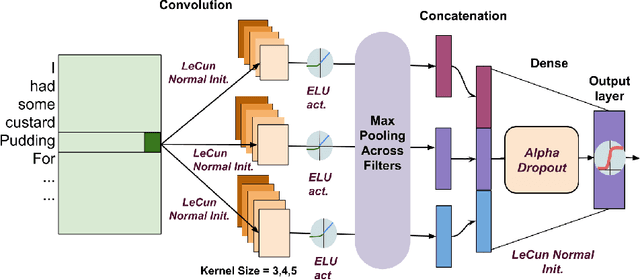
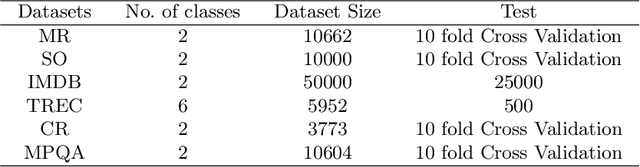
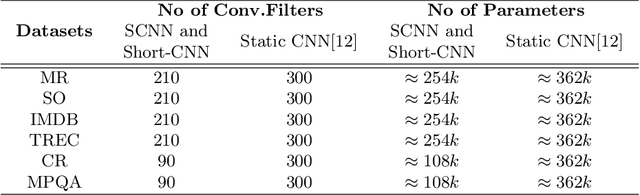
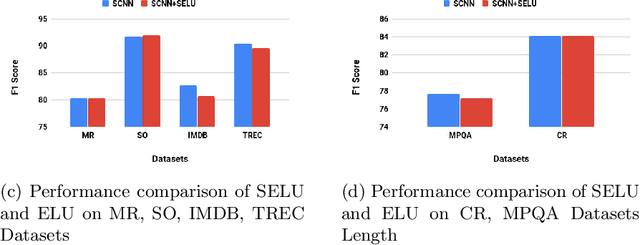
Self Normalizing Neural Networks(SNN) proposed on Feed Forward Neural Networks(FNN) outperform regular FNN architectures in various machine learning tasks. Particularly in the domain of Computer Vision, the activation function Scaled Exponential Linear Units (SELU) proposed for SNNs, perform better than other non linear activations such as ReLU. The goal of SNN is to produce a normalized output for a normalized input. Established neural network architectures like feed forward networks and Convolutional Neural Networks(CNN) lack the intrinsic nature of normalizing outputs. Hence, requiring additional layers such as Batch Normalization. Despite the success of SNNs, their characteristic features on other network architectures like CNN haven't been explored, especially in the domain of Natural Language Processing. In this paper we aim to show the effectiveness of proposed, Self Normalizing Convolutional Neural Networks(SCNN) on text classification. We analyze their performance with the standard CNN architecture used on several text classification datasets. Our experiments demonstrate that SCNN achieves comparable results to standard CNN model with significantly fewer parameters. Furthermore it also outperforms CNN with equal number of parameters.
Towards Enhancing Lexical Resource and Using Sense-annotations of OntoSenseNet for Sentiment Analysis
Jul 25, 2018

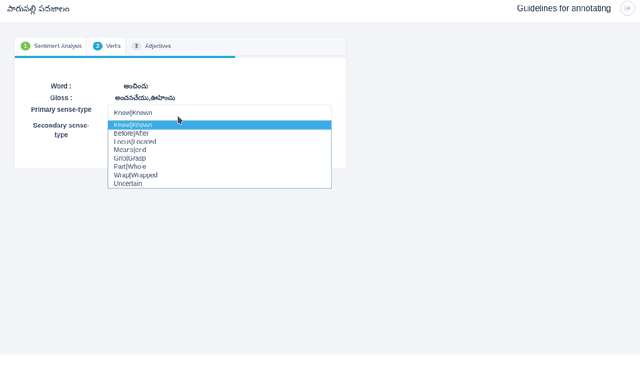

This paper illustrates the interface of the tool we developed for crowd sourcing and we explain the annotation procedure in detail. Our tool is named as 'Parupalli Padajaalam' which means web of words by Parupalli. The aim of this tool is to populate the OntoSenseNet, sentiment polarity annotated Telugu resource. Recent works have shown the importance of word-level annotations on sentiment analysis. With this as basis, we aim to analyze the importance of sense-annotations obtained from OntoSenseNet in performing the task of sentiment analysis. We explain the fea- tures extracted from OntoSenseNet (Telugu). Furthermore we compute and explain the adverbial class distribution of verbs in OntoSenseNet. This task is known to aid in disambiguating word-senses which helps in enhancing the performance of word-sense disambiguation (WSD) task(s).
BCSAT : A Benchmark Corpus for Sentiment Analysis in Telugu Using Word-level Annotations
Jul 04, 2018
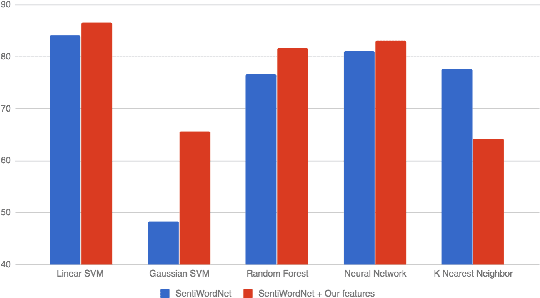

The presented work aims at generating a systematically annotated corpus that can support the enhancement of sentiment analysis tasks in Telugu using word-level sentiment annotations. From OntoSenseNet, we extracted 11,000 adjectives, 253 adverbs, 8483 verbs and sentiment annotation is being done by language experts. We discuss the methodology followed for the polarity annotations and validate the developed resource. This work aims at developing a benchmark corpus, as an extension to SentiWordNet, and baseline accuracy for a model where lexeme annotations are applied for sentiment predictions. The fundamental aim of this paper is to validate and study the possibility of utilizing machine learning algorithms, word-level sentiment annotations in the task of automated sentiment identification. Furthermore, accuracy is improved by annotating the bi-grams extracted from the target corpus.
Towards Automation of Sense-type Identification of Verbs in OntoSenseNet(Telugu)
Jul 04, 2018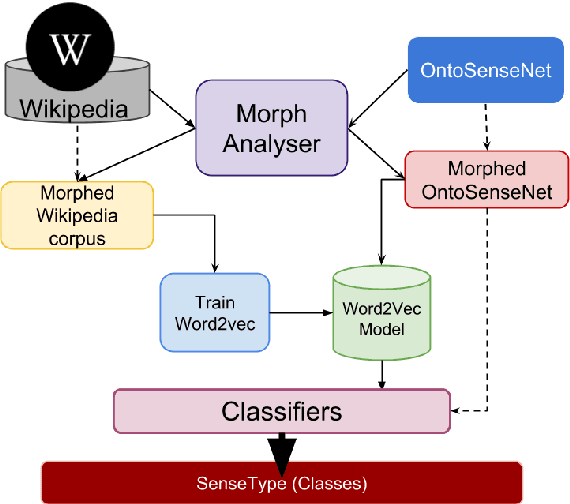
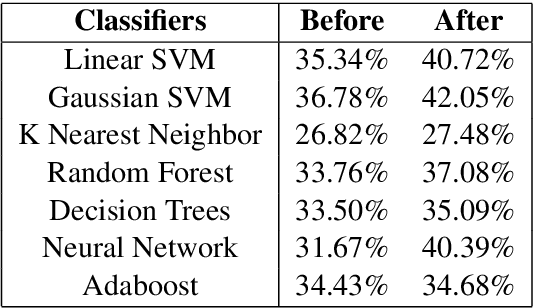
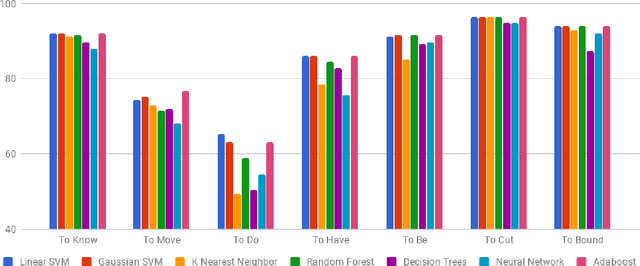
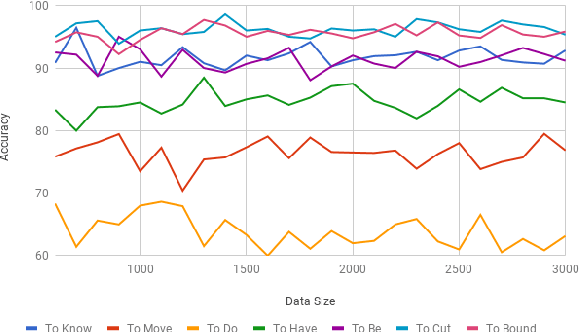
In this paper, we discuss the enrichment of a manually developed resource of Telugu lexicon, OntoSenseNet. OntoSenseNet is a ontological sense annotated lexicon that marks each verb of Telugu with a primary and a secondary sense. The area of research is relatively recent but has a large scope of development. We provide an introductory work to enrich the OntoSenseNet to promote further research in Telugu. Classifiers are adopted to learn the sense relevant features of the words in the resource and also to automate the tagging of sense-types for verbs. We perform a comparative analysis of different classifiers applied on OntoSenseNet. The results of the experiment prove that automated enrichment of the resource is effective using SVM classifiers and Adaboost ensemble.