 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automation of Sense-type Identification of Verbs in OntoSenseNet(Telugu)
Paper and Code
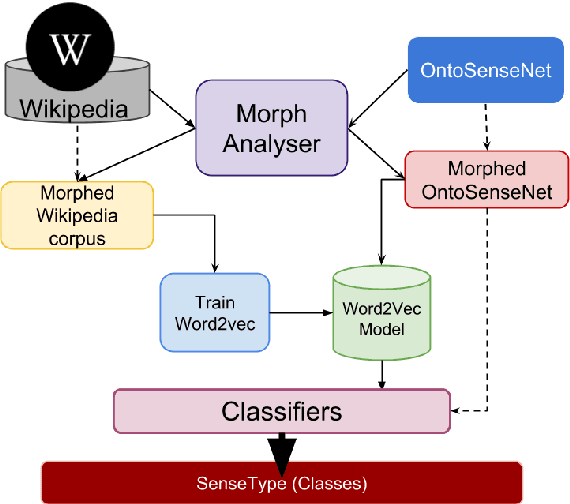
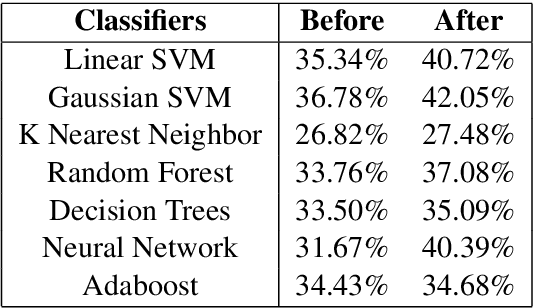
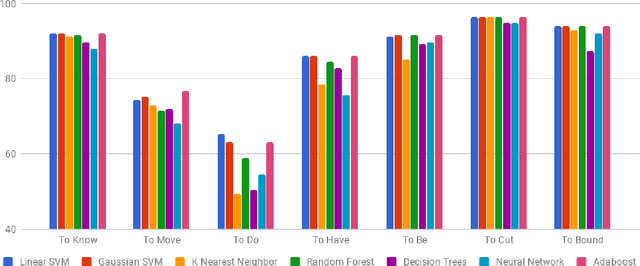
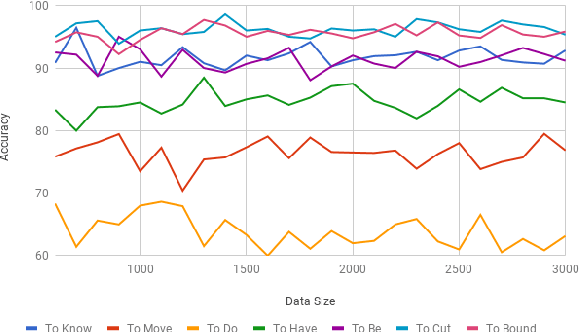
In this paper, we discuss the enrichment of a manually developed resource of Telugu lexicon, OntoSenseNet. OntoSenseNet is a ontological sense annotated lexicon that marks each verb of Telugu with a primary and a secondary sense. The area of research is relatively recent but has a large scope of development. We provide an introductory work to enrich the OntoSenseNet to promote further research in Telugu. Classifiers are adopted to learn the sense relevant features of the words in the resource and also to automate the tagging of sense-types for verbs. We perform a comparative analysis of different classifiers applied on OntoSenseNet. The results of the experiment prove that automated enrichment of the resource is effective using SVM classifiers and Adaboost ensemble.