 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntoSenseNet: A Verb-Centric Ontological Resource for Indian Languages
Aug 02, 2018
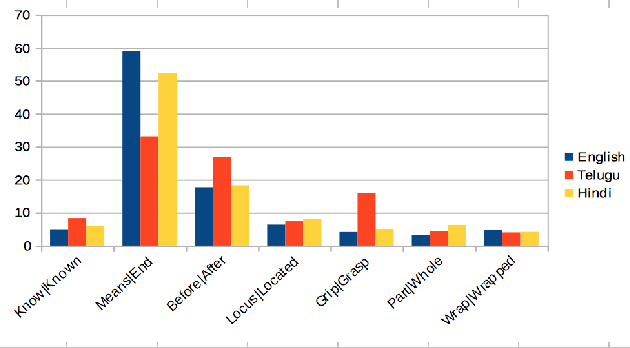
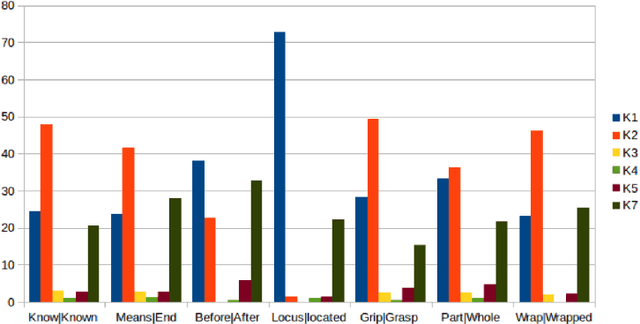
Following approaches for understanding lexical meaning developed by Yaska, Patanjali and Bhartrihari from Indian linguistic traditions and extending approaches developed by Leibniz and Brentano in the modern times, a framework of formal ontology of language was developed. This framework proposes that meaning of words are in-formed by intrinsic and extrinsic ontological structures. The paper aims to capture such intrinsic and extrinsic meanings of words for two major Indian languages, namely, Hindi and Telugu. Parts-of-speech have been rendered into sense-types and sense-classes. Using them we have developed a gold- standard annotated lexical resource to support semantic understanding of a language. The resource has collection of Hindi and Telugu lexicons, which has been manually annotated by native speakers of the languages following our annotation guidelines. Further, the resource was utilised to derive adverbial sense-class distribution of verbs and karaka-verb sense- type distribution. Different corpora (news, novels) were compared using verb sense-types distribution. Word Embedding was used as an aid for the enrichment of the resource. This is a work in progress that aims at lexical coverage of language extensively.
Towards Enhancing Lexical Resource and Using Sense-annotations of OntoSenseNet for Sentiment Analysis
Jul 25, 2018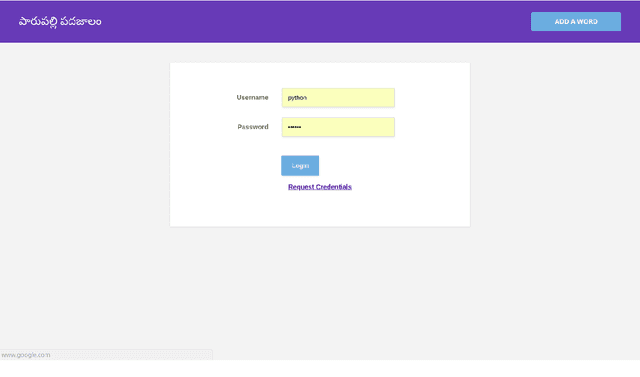

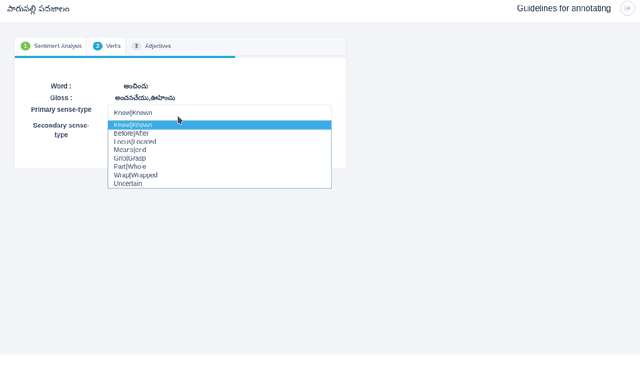

This paper illustrates the interface of the tool we developed for crowd sourcing and we explain the annotation procedure in detail. Our tool is named as 'Parupalli Padajaalam' which means web of words by Parupalli. The aim of this tool is to populate the OntoSenseNet, sentiment polarity annotated Telugu resource. Recent works have shown the importance of word-level annotations on sentiment analysis. With this as basis, we aim to analyze the importance of sense-annotations obtained from OntoSenseNet in performing the task of sentiment analysis. We explain the fea- tures extracted from OntoSenseNet (Telugu). Furthermore we compute and explain the adverbial class distribution of verbs in OntoSenseNet. This task is known to aid in disambiguating word-senses which helps in enhancing the performance of word-sense disambiguation (WSD) task(s).
Enrichment of OntoSenseNet: Adding a Sense-annotated Telugu lexicon
Jul 09, 2018
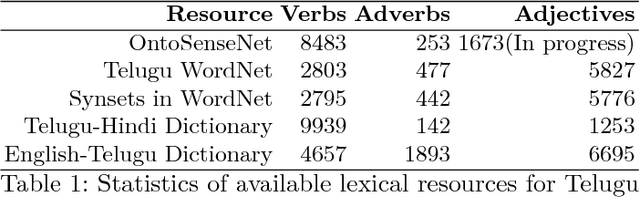


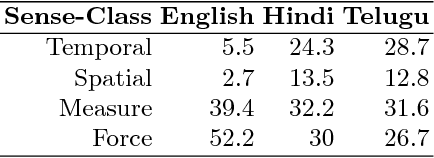
The paper describes the enrichment of OntoSenseNet - a verb-centric lexical resource for Indian Languages. This resource contains a newly developed Telugu-Telugu dictionary. It is important because native speakers can better annotate the senses when both the word and its meaning are in Telugu. Hence efforts are made to develop a soft copy of Telugu dictionary. Our resource also has manually annotated gold standard corpus consisting 8483 verbs, 253 adverbs and 1673 adjectives. Annotations are done by native speakers according to defined annotation guidelines. In this paper, we provide an overview of the annotation procedure and present the validation of our resource through inter-annotator agreement. Concepts of sense-class and sense-type are discussed. Additionally, we discuss the potential of lexical sense-annotated corpora in improving word sense disambiguation (WSD) tasks. Telugu WordNet is crowd-sourced for annotation of individual words in synsets and is compared with the developed sense-annotated lexicon (OntoSenseNet) to examine the improvement. Also, we present a special categorization (spatio-temporal classification) of adjectives.
A Formal Ontology-Based Classification of Lexemes and its Applications
Jul 04, 2018
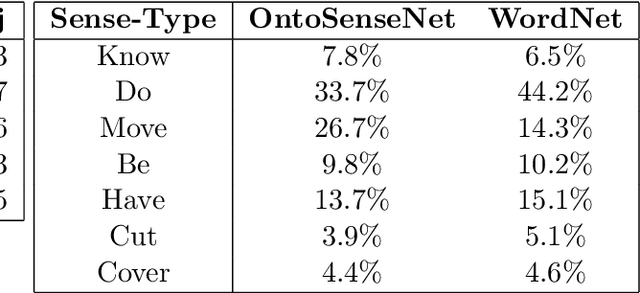
The paper describes the enrichment of OntoSenseNet - a verb-centric lexical resource for Indian Languages. A major contribution of this work is preservation of an authentic Telugu dictionary by developing a computational version of the same. It is important because native speakers can better annotate the sense-types when both the word and its meaning are in Telugu. Hence efforts are made to develop the aforementioned Telugu dictionary and annotations are done manually. The manually annotated gold standard corpus consists 8483 verbs, 253 adverbs and 1673 adjectives. Annotations are done by native speakers according to defined annotation guidelines. In this paper, we provide an overview of the annotation procedure and present the validation of the developed resource through inter-annotator agreement. Additional words from Telugu WordNet are added to our resource and are crowd-sourced for annotation. The statistics are compared with the sense-annotated lexicon, our resource for more insights.
BCSAT : A Benchmark Corpus for Sentiment Analysis in Telugu Using Word-level Annotations
Jul 04, 2018
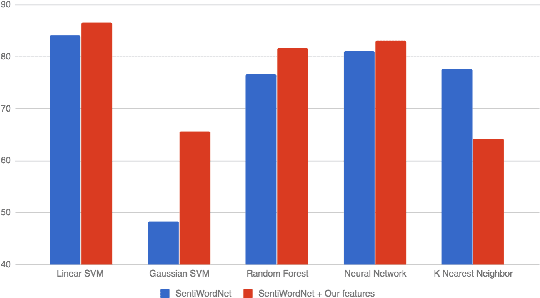

The presented work aims at generating a systematically annotated corpus that can support the enhancement of sentiment analysis tasks in Telugu using word-level sentiment annotations. From OntoSenseNet, we extracted 11,000 adjectives, 253 adverbs, 8483 verbs and sentiment annotation is being done by language experts. We discuss the methodology followed for the polarity annotations and validate the developed resource. This work aims at developing a benchmark corpus, as an extension to SentiWordNet, and baseline accuracy for a model where lexeme annotations are applied for sentiment predictions. The fundamental aim of this paper is to validate and study the possibility of utilizing machine learning algorithms, word-level sentiment annotations in the task of automated sentiment identification. Furthermore, accuracy is improved by annotating the bi-grams extracted from the target corpus.
Towards Automation of Sense-type Identification of Verbs in OntoSenseNet(Telugu)
Jul 04, 2018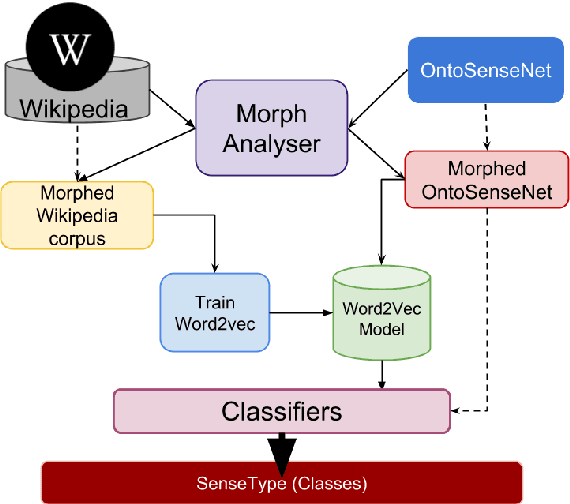
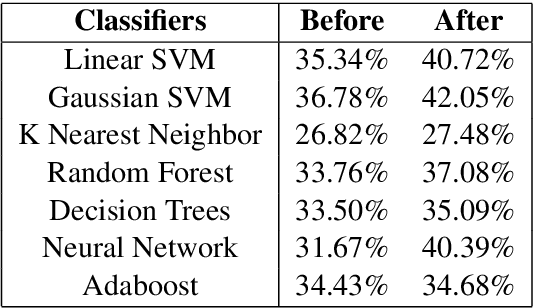
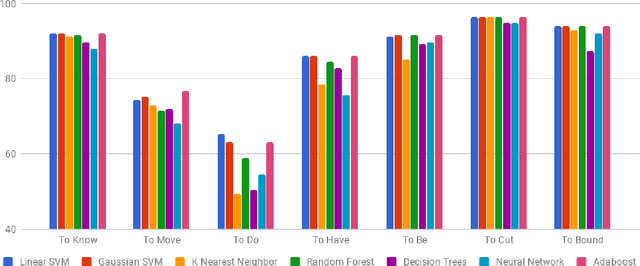
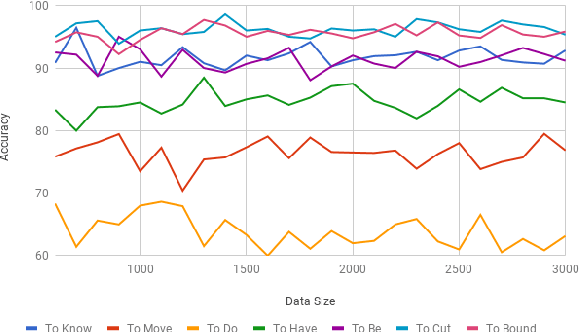
In this paper, we discuss the enrichment of a manually developed resource of Telugu lexicon, OntoSenseNet. OntoSenseNet is a ontological sense annotated lexicon that marks each verb of Telugu with a primary and a secondary sense. The area of research is relatively recent but has a large scope of development. We provide an introductory work to enrich the OntoSenseNet to promote further research in Telugu. Classifiers are adopted to learn the sense relevant features of the words in the resource and also to automate the tagging of sense-types for verbs. We perform a comparative analysis of different classifiers applied on OntoSenseNet. The results of the experiment prove that automated enrichment of the resource is effective using SVM classifiers and Adaboost ensemble.