 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Speeches in Indian Parliamentary Debates
Aug 21, 2018


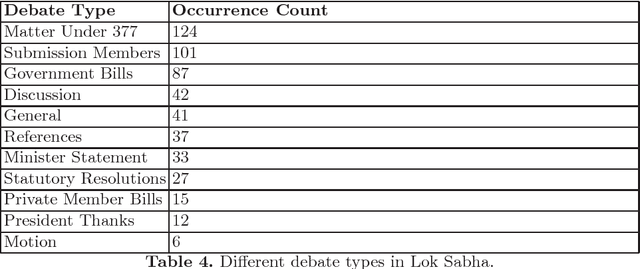
With the increasing usage of the internet, more and more data is being digitized including parliamentary debates but they are in an unstructured format. There is a need to convert them into a structured format for linguistic analysis. Much work has been done on parliamentary data such as Hansard, American congressional floor-debate data on various aspects but less on pragmatics. In this paper, we provide a dataset for the synopsis of Indian parliamentary debates and perform stance classification of speeches i.e identifying if the speaker is supporting the bill/issue or against it. We also analyze the intention of the speeches beyond mere sentences i.e pragmatics in the parliament. Based on thorough manual analysis of the debates, we developed an annotation scheme of 4 mutually exclusive categories to analyze the purpose of the speeches: to find out ISSUES, to BLAME, to APPRECIATE and for CALL FOR ACTION. We have annotated the dataset provided, with these 4 categories and conducted preliminary experiments for automatic detection of the categories. Our automated classification approach gave us promising results.
OntoSenseNet: A Verb-Centric Ontological Resource for Indian Languages
Aug 02, 2018
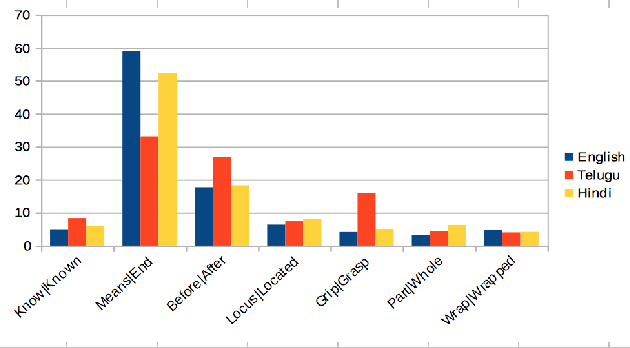
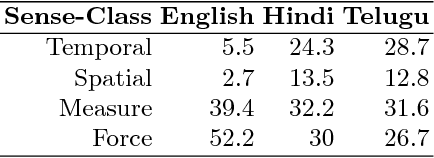
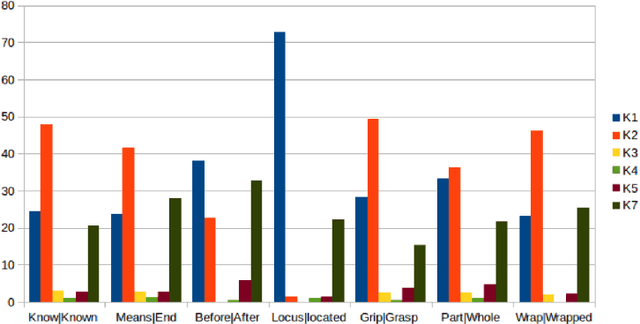
Following approaches for understanding lexical meaning developed by Yaska, Patanjali and Bhartrihari from Indian linguistic traditions and extending approaches developed by Leibniz and Brentano in the modern times, a framework of formal ontology of language was developed. This framework proposes that meaning of words are in-formed by intrinsic and extrinsic ontological structures. The paper aims to capture such intrinsic and extrinsic meanings of words for two major Indian languages, namely, Hindi and Telugu. Parts-of-speech have been rendered into sense-types and sense-classes. Using them we have developed a gold- standard annotated lexical resource to support semantic understanding of a language. The resource has collection of Hindi and Telugu lexicons, which has been manually annotated by native speakers of the languages following our annotation guidelines. Further, the resource was utilised to derive adverbial sense-class distribution of verbs and karaka-verb sense- type distribution. Different corpora (news, novels) were compared using verb sense-types distribution. Word Embedding was used as an aid for the enrichment of the resource. This is a work in progress that aims at lexical coverage of language extensively.
Enrichment of OntoSenseNet: Adding a Sense-annotated Telugu lexicon
Jul 09, 2018
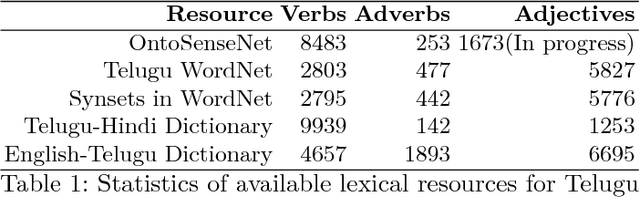


The paper describes the enrichment of OntoSenseNet - a verb-centric lexical resource for Indian Languages. This resource contains a newly developed Telugu-Telugu dictionary. It is important because native speakers can better annotate the senses when both the word and its meaning are in Telugu. Hence efforts are made to develop a soft copy of Telugu dictionary. Our resource also has manually annotated gold standard corpus consisting 8483 verbs, 253 adverbs and 1673 adjectives. Annotations are done by native speakers according to defined annotation guidelines. In this paper, we provide an overview of the annotation procedure and present the validation of our resource through inter-annotator agreement. Concepts of sense-class and sense-type are discussed. Additionally, we discuss the potential of lexical sense-annotated corpora in improving word sense disambiguation (WSD) tasks. Telugu WordNet is crowd-sourced for annotation of individual words in synsets and is compared with the developed sense-annotated lexicon (OntoSenseNet) to examine the improvement. Also, we present a special categorization (spatio-temporal classification) of adjectives.
A Formal Ontology-Based Classification of Lexemes and its Applications
Jul 04, 2018
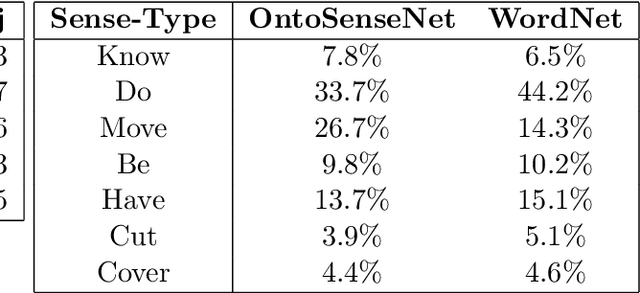
The paper describes the enrichment of OntoSenseNet - a verb-centric lexical resource for Indian Languages. A major contribution of this work is preservation of an authentic Telugu dictionary by developing a computational version of the same. It is important because native speakers can better annotate the sense-types when both the word and its meaning are in Telugu. Hence efforts are made to develop the aforementioned Telugu dictionary and annotations are done manually. The manually annotated gold standard corpus consists 8483 verbs, 253 adverbs and 1673 adjectives. Annotations are done by native speakers according to defined annotation guidelines. In this paper, we provide an overview of the annotation procedure and present the validation of the developed resource through inter-annotator agreement. Additional words from Telugu WordNet are added to our resource and are crowd-sourced for annotation. The statistics are compared with the sense-annotated lexicon, our resource for more insights.