 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Formal Ontology-Based Classification of Lexemes and its Applications
Paper and Code
Jul 04, 2018
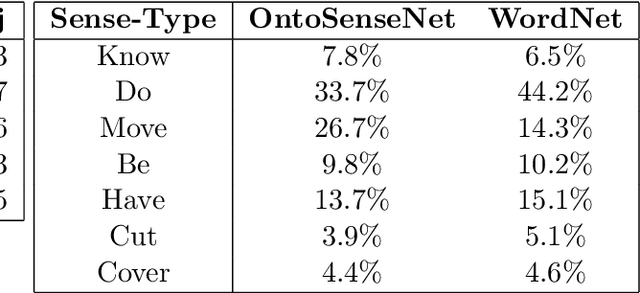
The paper describes the enrichment of OntoSenseNet - a verb-centric lexical resource for Indian Languages. A major contribution of this work is preservation of an authentic Telugu dictionary by developing a computational version of the same. It is important because native speakers can better annotate the sense-types when both the word and its meaning are in Telugu. Hence efforts are made to develop the aforementioned Telugu dictionary and annotations are done manually. The manually annotated gold standard corpus consists 8483 verbs, 253 adverbs and 1673 adjectives. Annotations are done by native speakers according to defined annotation guidelines. In this paper, we provide an overview of the annotation procedure and present the validation of the developed resource through inter-annotator agreement. Additional words from Telugu WordNet are added to our resource and are crowd-sourced for annotation. The statistics are compared with the sense-annotated lexicon, our resource for more insights.