 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-time Unlearning Using Conformal Prediction
Feb 03, 2026Machine unlearning is the process of efficiently removing specific information from a trained machine learning model without retraining from scratch. Existing unlearning methods, which often provide provable guarantees, typically involve retraining a subset of model parameters based on a forget set. While these approaches show promise in certain scenarios, their underlying assumptions are often challenged in real-world applications -- particularly when applied to generative models. Furthermore, updating parameters using these unlearning procedures often degrades the general-purpose capabilities the model acquired during pre-training. Motivated by these shortcomings, this paper considers the paradigm of inference time unlearning -- wherein, the generative model is equipped with an (approximately correct) verifier that judges whether the model's response satisfies appropriate unlearning guarantees. This paper introduces a framework that iteratively refines the quality of the generated responses using feedback from the verifier without updating the model parameters. The proposed framework leverages conformal prediction to reduce computational overhead and provide distribution-free unlearning guarantees. This paper's approach significantly outperforms existing state-of-the-art methods, reducing unlearning error by up to 93% across challenging unlearning benchmarks.
EUGens: Efficient, Unified, and General Dense Layers
Jan 30, 2026Efficient neural networks are essential for scaling machine learning models to real-time applications and resource-constrained environments. Fully-connected feedforward layers (FFLs) introduce computation and parameter count bottlenecks within neural network architectures. To address this challenge, in this work, we propose a new class of dense layers that generalize standard fully-connected feedforward layers, \textbf{E}fficient, \textbf{U}nified and \textbf{Gen}eral dense layers (EUGens). EUGens leverage random features to approximate standard FFLs and go beyond them by incorporating a direct dependence on the input norms in their computations. The proposed layers unify existing efficient FFL extensions and improve efficiency by reducing inference complexity from quadratic to linear time. They also lead to \textbf{the first} unbiased algorithms approximating FFLs with arbitrary polynomial activation functions. Furthermore, EuGens reduce the parameter count and computational overhead while preserving the expressive power and adaptability of FFLs. We also present a layer-wise knowledge transfer technique that bypasses backpropagation, enabling efficient adaptation of EUGens to pre-trained models. Empirically, we observe that integrating EUGens into Transformers and MLPs yields substantial improvements in inference speed (up to \textbf{27}\%) and memory efficiency (up to \textbf{30}\%) across a range of tasks, including image classification, language model pre-training, and 3D scene reconstruction. Overall, our results highlight the potential of EUGens for the scalable deployment of large-scale neural networks in real-world scenarios.
Fundamental Limits of Perfect Concept Erasure
Mar 25, 2025Concept erasure is the task of erasing information about a concept (e.g., gender or race) from a representation set while retaining the maximum possible utility -- information from original representations. Concept erasure is useful in several applications, such as removing sensitive concepts to achieve fairness and interpreting the impact of specific concepts on a model's performance. Previous concept erasure techniques have prioritized robustly erasing concepts over retaining the utility of the resultant representations. However, there seems to be an inherent tradeoff between erasure and retaining utility, making it unclear how to achieve perfect concept erasure while maintaining high utility. In this paper, we offer a fresh perspective toward solving this problem by quantifying the fundamental limits of concept erasure through an information-theoretic lens. Using these results, we investigate constraints on the data distribution and the erasure functions required to achieve the limits of perfect concept erasure. Empirically, we show that the derived erasure functions achieve the optimal theoretical bounds. Additionally, we show that our approach outperforms existing methods on a range of synthetic and real-world datasets using GPT-4 representations.
Structured Unrestricted-Rank Matrices for Parameter Efficient Fine-tuning
Jun 25, 2024



Recent efforts to scale Transformer models have demonstrated rapid progress across a wide range of tasks (Wei et al., 2022). However, fine-tuning these models for downstream tasks is expensive due to their large parameter counts. Parameter-efficient fine-tuning (PEFT) approaches have emerged as a viable alternative by allowing us to fine-tune models by updating only a small number of parameters. In this work, we propose a general framework for parameter efficient fine-tuning (PEFT), based on structured unrestricted-rank matrices (SURM) which can serve as a drop-in replacement for popular approaches such as Adapters and LoRA. Unlike other methods like LoRA, SURMs provides more flexibility in finding the right balance between compactness and expressiveness. This is achieved by using low displacement rank matrices (LDRMs), which hasn't been used in this context before. SURMs remain competitive with baselines, often providing significant quality improvements while using a smaller parameter budget. SURMs achieve 5-7% accuracy gains on various image classification tasks while replacing low-rank matrices in LoRA. It also results in up to 12x reduction of the number of parameters in adapters (with virtually no loss in quality) on the GLUE benchmark.
Towards Scalable Exact Machine Unlearning Using Parameter-Efficient Fine-Tuning
Jun 24, 2024Machine unlearning is the process of efficiently removing the influence of a training data instance from a trained machine learning model without retraining it from scratch. A popular subclass of unlearning approaches is exact machine unlearning, which focuses on techniques that explicitly guarantee the removal of the influence of a data instance from a model. Exact unlearning approaches use a machine learning model in which individual components are trained on disjoint subsets of the data. During deletion, exact unlearning approaches only retrain the affected components rather than the entire model. While existing approaches reduce retraining costs, it can still be expensive for an organization to retrain a model component as it requires halting a system in production, which leads to service failure and adversely impacts customers. To address these challenges, we introduce an exact unlearning framework -- Sequence-aware Sharded Sliced Training (S3T), designed to enhance the deletion capabilities of an exact unlearning system while minimizing the impact on model's performance. At the core of S3T, we utilize a lightweight parameter-efficient fine-tuning approach that enables parameter isolation by sequentially training layers with disjoint data slices. This enables efficient unlearning by simply deactivating the layers affected by data deletion. Furthermore, to reduce the retraining cost and improve model performance, we train the model on multiple data sequences, which allows S3T to handle an increased number of deletion requests. Both theoretically and empirically, we demonstrate that S3T attains superior deletion capabilities and enhanced performance compared to baselines across a wide range of settings.
Fast Tree-Field Integrators: From Low Displacement Rank to Topological Transformers
Jun 22, 2024We present a new class of fast polylog-linear algorithms based on the theory of structured matrices (in particular low displacement rank) for integrating tensor fields defined on weighted trees. Several applications of the resulting fast tree-field integrators (FTFIs) are presented, including (a) approximation of graph metrics with tree metrics, (b) graph classification, (c) modeling on meshes, and finally (d) Topological Transformers (TTs) (Choromanski et al., 2022) for images. For Topological Transformers, we propose new relative position encoding (RPE) masking mechanisms with as few as three extra learnable parameters per Transformer layer, leading to 1.0-1.5%+ accuracy gains. Importantly, most of FTFIs are exact methods, thus numerically equivalent to their brute-force counterparts. When applied to graphs with thousands of nodes, those exact algorithms provide 5.7-13x speedups. We also provide an extensive theoretical analysis of our methods.
Exploring Safety-Utility Trade-Offs in Personalized Language Models
Jun 17, 2024



As large language models (LLMs) become increasingly integrated into daily applications, it is essential to ensure they operate fairly across diverse user demographics. In this work, we show that LLMs suffer from personalization bias, where their performance is impacted when they are personalized to a user's identity. We quantify personalization bias by evaluating the performance of LLMs along two axes - safety and utility. We measure safety by examining how benign LLM responses are to unsafe prompts with and without personalization. We measure utility by evaluating the LLM's performance on various tasks, including general knowledge, mathematical abilities, programming, and reasoning skills. We find that various LLMs, ranging from open-source models like Llama (Touvron et al., 2023) and Mistral (Jiang et al., 2023) to API-based ones like GPT-3.5 and GPT-4o (Ouyang et al., 2022), exhibit significant variance in performance in terms of safety-utility trade-offs depending on the user's identity. Finally, we discuss several strategies to mitigate personalization bias using preference tuning and prompt-based defenses.
Embodied AI with Two Arms: Zero-shot Learning, Safety and Modularity
Apr 04, 2024We present an embodied AI system which receives open-ended natural language instructions from a human, and controls two arms to collaboratively accomplish potentially long-horizon tasks over a large workspace. Our system is modular: it deploys state of the art Large Language Models for task planning,Vision-Language models for semantic perception, and Point Cloud transformers for grasping. With semantic and physical safety in mind, these modules are interfaced with a real-time trajectory optimizer and a compliant tracking controller to enable human-robot proximity. We demonstrate performance for the following tasks: bi-arm sorting, bottle opening, and trash disposal tasks. These are done zero-shot where the models used have not been trained with any real world data from this bi-arm robot, scenes or workspace.Composing both learning- and non-learning-based components in a modular fashion with interpretable inputs and outputs allows the user to easily debug points of failures and fragilities. One may also in-place swap modules to improve the robustness of the overall platform, for instance with imitation-learned policies.
Incremental Extractive Opinion Summarization Using Cover Trees
Jan 16, 2024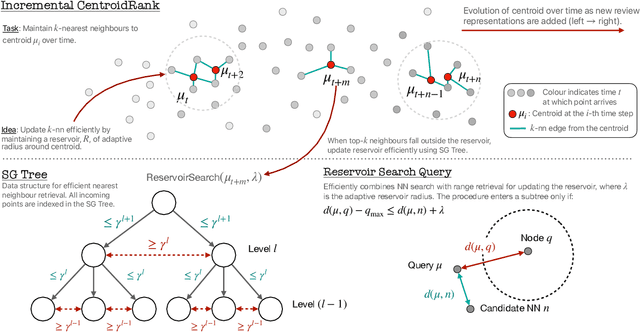
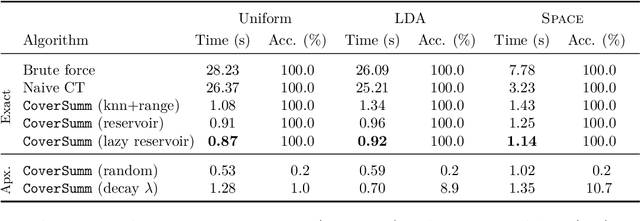
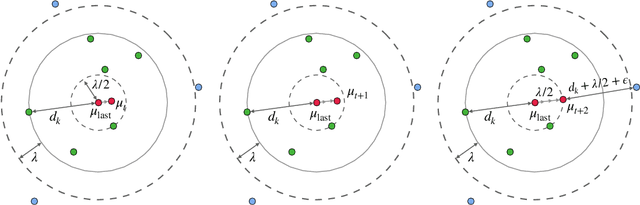
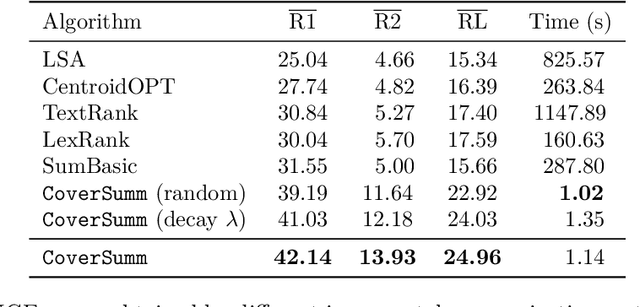
Extractive opinion summarization involves automatically producing a summary of text about an entity (e.g., a product's reviews) by extracting representative sentences that capture prevalent opinions in the review set. Typically, in online marketplaces user reviews accrue over time, and opinion summaries need to be updated periodically to provide customers with up-to-date information. In this work, we study the task of extractive opinion summarization in an incremental setting, where the underlying review set evolves over time. Many of the state-of-the-art extractive opinion summarization approaches are centrality-based, such as CentroidRank. CentroidRank performs extractive summarization by selecting a subset of review sentences closest to the centroid in the representation space as the summary. However, these methods are not capable of operating efficiently in an incremental setting, where reviews arrive one at a time. In this paper, we present an efficient algorithm for accurately computing the CentroidRank summaries in an incremental setting. Our approach, CoverSumm, relies on indexing review representations in a cover tree and maintaining a reservoir of candidate summary review sentences. CoverSumm's efficacy is supported by a theoretical and empirical analysis of running time. Empirically, on a diverse collection of data (both real and synthetically created to illustrate scaling considerations), we demonstrate that CoverSumm is up to 25x faster than baseline methods, and capable of adapting to nuanced changes in data distribution. We also conduct human evaluations of the generated summaries and find that CoverSumm is capable of producing informative summaries consistent with the underlying review set.
Robust Concept Erasure via Kernelized Rate-Distortion Maximization
Nov 30, 2023Distributed representations provide a vector space that captures meaningful relationships between data instances. The distributed nature of these representations, however, entangles together multiple attributes or concepts of data instances (e.g., the topic or sentiment of a text, characteristics of the author (age, gender, etc), etc). Recent work has proposed the task of concept erasure, in which rather than making a concept predictable, the goal is to remove an attribute from distributed representations while retaining other information from the original representation space as much as possible. In this paper, we propose a new distance metric learning-based objective, the Kernelized Rate-Distortion Maximizer (KRaM), for performing concept erasure. KRaM fits a transformation of representations to match a specified distance measure (defined by a labeled concept to erase) using a modified rate-distortion function. Specifically, KRaM's objective function aims to make instances with similar concept labels dissimilar in the learned representation space while retaining other information. We find that optimizing KRaM effectively erases various types of concepts: categorical, continuous, and vector-valued variables from data representations across diverse domains. We also provide a theoretical analysis of several properties of KRaM's objective. To assess the quality of the learned representations, we propose an alignment score to evaluate their similarity with the original representation space. Additionally, we conduct experiments to showcase KRaM's efficacy in various settings, from erasing binary gender variables in word embeddings to vector-valued variables in GPT-3 representations.