 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheia: Distilling Diverse Vision Foundation Models for Robot Learning
Jul 29, 2024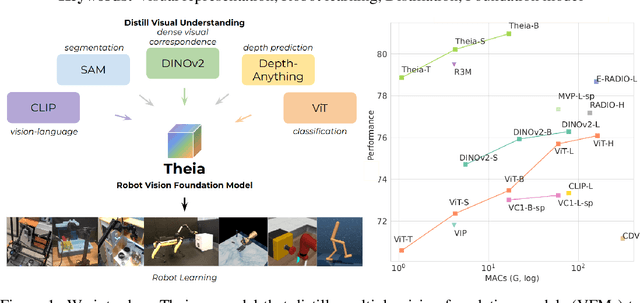



Vision-based robot policy learning, which maps visual inputs to actions, necessitates a holistic understanding of diverse visual tasks beyond single-task needs like classification or segmentation. Inspired by this, we introduce Theia, a vision foundation model for robot learning that distills multiple off-the-shelf vision foundation models trained on varied vision tasks. Theia's rich visual representations encode diverse visual knowledge, enhancing downstream robot learning. Extensive experiments demonstrate that Theia outperforms its teacher models and prior robot learning models using less training data and smaller model sizes. Additionally, we quantify the quality of pre-trained visual representations and hypothesize that higher entropy in feature norm distributions leads to improved robot learning performance. Code and models are available at https://github.com/bdaiinstitute/theia.
A Survey of Robotic Language Grounding: Tradeoffs Between Symbols and Embeddings
May 21, 2024

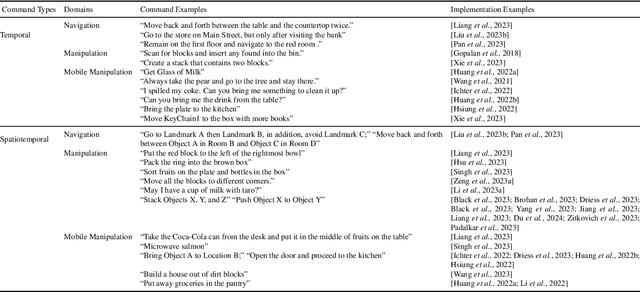
With large language models, robots can understand language more flexibly and more capable than ever before. This survey reviews recent literature and situates it into a spectrum with two poles: 1) mapping between language and some manually defined formal representation of meaning, and 2) mapping between language and high-dimensional vector spaces that translate directly to low-level robot policy. Using a formal representation allows the meaning of the language to be precisely represented, limits the size of the learning problem, and leads to a framework for interpretability and formal safety guarantees. Methods that embed language and perceptual data into high-dimensional spaces avoid this manually specified symbolic structure and thus have the potential to be more general when fed enough data but require more data and computing to train. We discuss the benefits and tradeoffs of each approach and finish by providing directions for future work that achieves the best of both worlds.
DIP-RL: Demonstration-Inferred Preference Learning in Minecraft
Jul 22, 2023

In machine learning for sequential decision-making, an algorithmic agent learns to interact with an environment while receiving feedback in the form of a reward signal. However, in many unstructured real-world settings, such a reward signal is unknown and humans cannot reliably craft a reward signal that correctly captures desired behavior. To solve tasks in such unstructured and open-ended environments, we present Demonstration-Inferred Preference Reinforcement Learning (DIP-RL), an algorithm that leverages human demonstrations in three distinct ways, including training an autoencoder, seeding reinforcement learning (RL) training batches with demonstration data, and inferring preferences over behaviors to learn a reward function to guide RL. We evaluate DIP-RL in a tree-chopping task in Minecraft. Results suggest that the method can guide an RL agent to learn a reward function that reflects human preferences and that DIP-RL performs competitively relative to baselines. DIP-RL is inspired by our previous work on combining demonstrations and pairwise preferences in Minecraft, which was awarded a research prize at the 2022 NeurIPS MineRL BASALT competition, Learning from Human Feedback in Minecraft. Example trajectory rollouts of DIP-RL and baselines are located at https://sites.google.com/view/dip-rl.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023

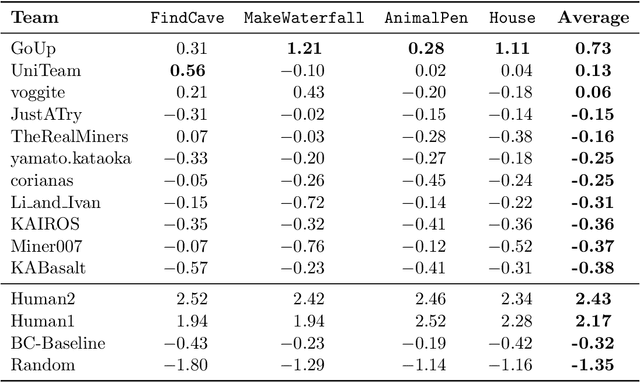
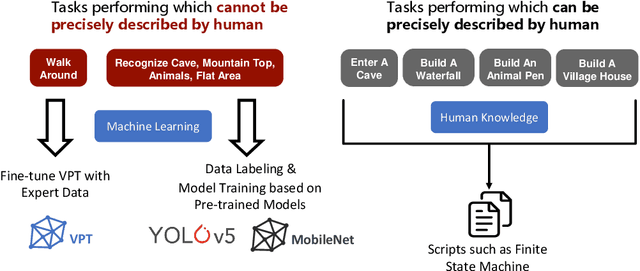
To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Efficient Graph Field Integrators Meet Point Clouds
Feb 05, 2023



We present two new classes of algorithms for efficient field integration on graphs encoding point clouds. The first class, SeparatorFactorization(SF), leverages the bounded genus of point cloud mesh graphs, while the second class, RFDiffusion(RFD), uses popular epsilon-nearest-neighbor graph representations for point clouds. Both can be viewed as providing the functionality of Fast Multipole Methods (FMMs), which have had a tremendous impact on efficient integration, but for non-Euclidean spaces. We focus on geometries induced by distributions of walk lengths between points (e.g., shortest-path distance). We provide an extensive theoretical analysis of our algorithms, obtaining new results in structural graph theory as a byproduct. We also perform exhaustive empirical evaluation, including on-surface interpolation for rigid and deformable objects (particularly for mesh-dynamics modeling), Wasserstein distance computations for point clouds, and the Gromov-Wasserstein variant.
Teleoperated Robot Grasping in Virtual Reality Spaces
Jan 30, 2023

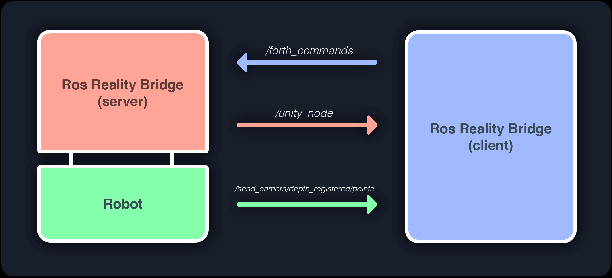
Despite recent advancement in virtual reality technology, teleoperating a high DoF robot to complete dexterous tasks in cluttered scenes remains difficult. In this work, we propose a system that allows the user to teleoperate a Fetch robot to perform grasping in an easy and intuitive way, through exploiting the rich environment information provided by the virtual reality space. Our system has the benefit of easy transferability to different robots and different tasks, and can be used without any expert knowledge. We tested the system on a real fetch robot, and a video demonstrating the effectiveness of our system can be seen at https://youtu.be/1-xW2Bx_Cms.
Learning Mobile Manipulation
Jun 07, 2022



Providing mobile robots with the ability to manipulate objects has, despite decades of research, remained a challenging problem. The problem is approachable in constrained environments where there is ample prior knowledge of the environment layout and manipulatable objects. The challenge is in building systems that scale beyond specific situational instances and gracefully operate in novel conditions. In the past, researchers used heuristic and simple rule-based strategies to accomplish tasks such as scene segmentation or reasoning about occlusion. These heuristic strategies work in constrained environments where a roboticist can make simplifying assumptions about everything from the geometries of the objects to be interacted with, level of clutter, camera position, lighting, and a myriad of other relevant variables. The work in this thesis will demonstrate how to build a system for robotic mobile manipulation that is robust to changes in these variables. This robustness will be enabled by recent simultaneous advances in the fields of big data, deep learning, and simulation. The ability of simulators to create realistic sensory data enables the generation of massive corpora of labeled training data for various grasping and navigation-based tasks. It is now possible to build systems that work in the real world trained using deep learning entirely on synthetic data. The ability to train and test on synthetic data allows for quick iterative development of new perception, planning and grasp execution algorithms that work in many environments.
Combining Learning from Human Feedback and Knowledge Engineering to Solve Hierarchical Tasks in Minecraft
Dec 07, 2021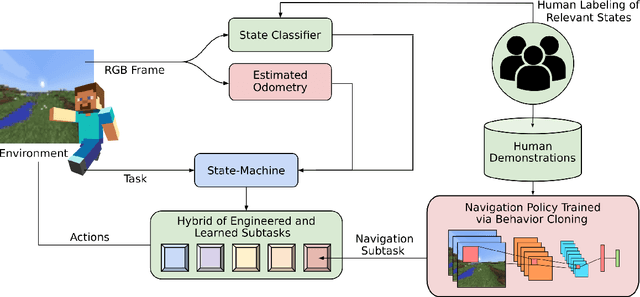
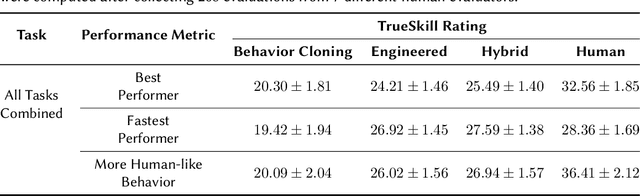

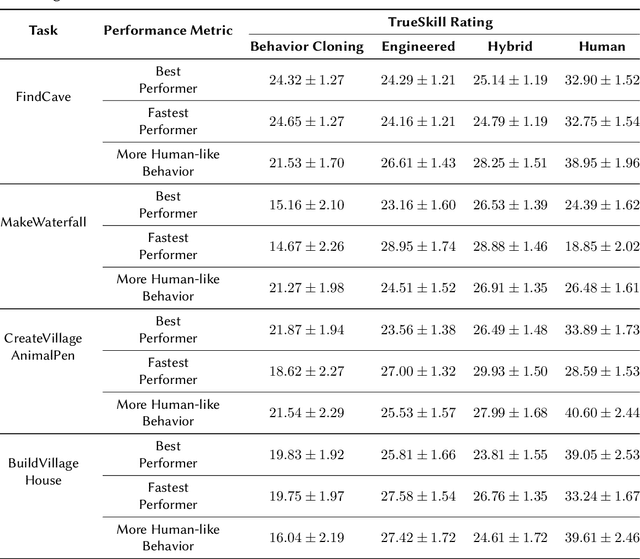
Real-world tasks of interest are generally poorly defined by human-readable descriptions and have no pre-defined reward signals unless it is defined by a human designer. Conversely, data-driven algorithms are often designed to solve a specific, narrowly defined, task with performance metrics that drives the agent's learning. In this work, we present the solution that won first place and was awarded the most human-like agent in the 2021 NeurIPS Competition MineRL BASALT Challenge: Learning from Human Feedback in Minecraft, which challenged participants to use human data to solve four tasks defined only by a natural language description and no reward function. Our approach uses the available human demonstration data to train an imitation learning policy for navigation and additional human feedback to train an image classifier. These modules, together with an estimated odometry map, are then combined into a state-machine designed based on human knowledge of the tasks that breaks them down in a natural hierarchy and controls which macro behavior the learning agent should follow at any instant. We compare this hybrid intelligence approach to both end-to-end machine learning and pure engineered solutions, which are then judged by human evaluators. Codebase is available at https://github.com/viniciusguigo/kairos_minerl_basalt.