 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-Playground: Massively Parallelized Multi-Objective Reinforcement Learning for Robotics
Mar 10, 2026Multi-objective reinforcement learning (MORL) is a powerful tool to learn Pareto-optimal policy families across conflicting objectives. However, unlike traditional RL algorithms, existing MORL algorithms do not effectively leverage large-scale parallelization to concurrently simulate thousands of environments, resulting in vastly increased computation time. Ultimately, this has limited MORL's application towards complex multi-objective robotics problems. To address these challenges, we present 1) MORLAX, a new GPU-native, fast MORL algorithm, and 2) MO-Playground, a pip-installable playground of GPU-accelerated multi-objective environments. Together, MORLAX and MO-Playground approximate Pareto sets within minutes, offering 25-270x speed-ups compared to legacy CPU-based approaches whilst achieving superior Pareto front hypervolumes. We demonstrate the versatility of our approach by implementing a custom BRUCE humanoid robot environment using MO-Playground and learning Pareto-optimal locomotion policies across 6 realistic objectives for BRUCE, such as smoothness, efficiency and arm swinging.
GraphAllocBench: A Flexible Benchmark for Preference-Conditioned Multi-Objective Policy Learning
Jan 28, 2026Preference-Conditioned Policy Learning (PCPL) in Multi-Objective Reinforcement Learning (MORL) aims to approximate diverse Pareto-optimal solutions by conditioning policies on user-specified preferences over objectives. This enables a single model to flexibly adapt to arbitrary trade-offs at run-time by producing a policy on or near the Pareto front. However, existing benchmarks for PCPL are largely restricted to toy tasks and fixed environments, limiting their realism and scalability. To address this gap, we introduce GraphAllocBench, a flexible benchmark built on a novel graph-based resource allocation sandbox environment inspired by city management, which we call CityPlannerEnv. GraphAllocBench provides a rich suite of problems with diverse objective functions, varying preference conditions, and high-dimensional scalability. We also propose two new evaluation metrics -- Proportion of Non-Dominated Solutions (PNDS) and Ordering Score (OS) -- that directly capture preference consistency while complementing the widely used hypervolume metric. Through experiments with Multi-Layer Perceptrons (MLPs) and graph-aware models, we show that GraphAllocBench exposes the limitations of existing MORL approaches and paves the way for using graph-based methods such as Graph Neural Networks in complex, high-dimensional combinatorial allocation tasks. Beyond its predefined problem set, GraphAllocBench enables users to flexibly vary objectives, preferences, and allocation rules, establishing it as a versatile and extensible benchmark for advancing PCPL. Code: https://anonymous.4open.science/r/GraphAllocBench
Learning Multi-Robot Coordination through Locality-Based Factorized Multi-Agent Actor-Critic Algorithm
Mar 24, 2025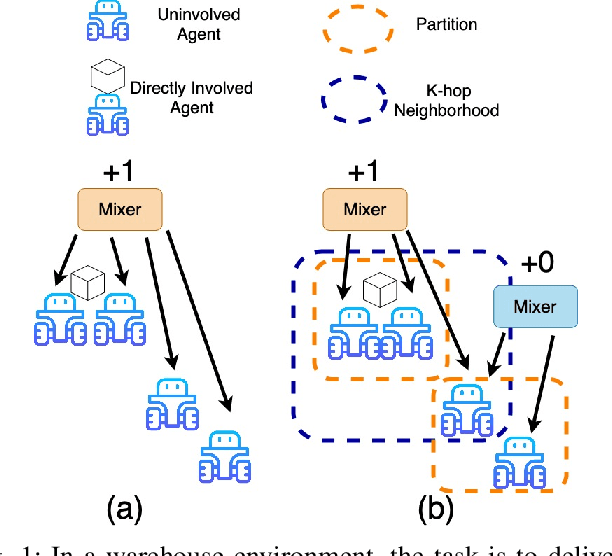
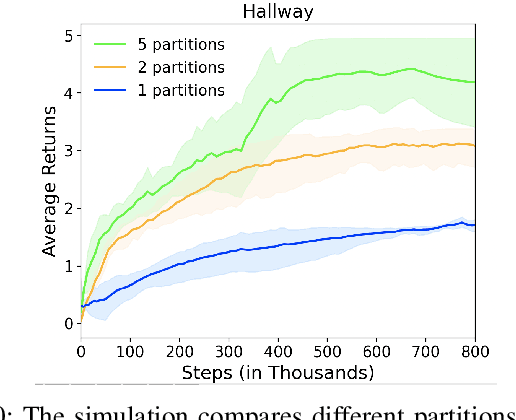
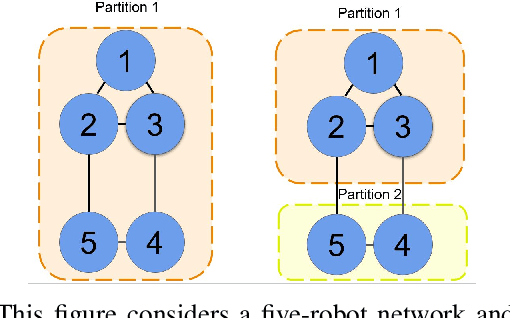
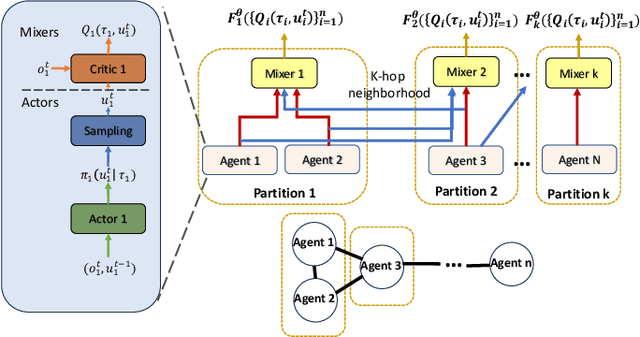
In this work, we present a novel cooperative multi-agent reinforcement learning method called \textbf{Loc}ality based \textbf{Fac}torized \textbf{M}ulti-Agent \textbf{A}ctor-\textbf{C}ritic (Loc-FACMAC). Existing state-of-the-art algorithms, such as FACMAC, rely on global reward information, which may not accurately reflect the quality of individual robots' actions in decentralized systems. We integrate the concept of locality into critic learning, where strongly related robots form partitions during training. Robots within the same partition have a greater impact on each other, leading to more precise policy evaluation. Additionally, we construct a dependency graph to capture the relationships between robots, facilitating the partitioning process. This approach mitigates the curse of dimensionality and prevents robots from using irrelevant information. Our method improves existing algorithms by focusing on local rewards and leveraging partition-based learning to enhance training efficiency and performance. We evaluate the performance of Loc-FACMAC in three environments: Hallway, Multi-cartpole, and Bounded-Cooperative-Navigation. We explore the impact of partition sizes on the performance and compare the result with baseline MARL algorithms such as LOMAQ, FACMAC, and QMIX. The experiments reveal that, if the locality structure is defined properly, Loc-FACMAC outperforms these baseline algorithms up to 108\%, indicating that exploiting the locality structure in the actor-critic framework improves the MARL performance.
Re-Envisioning Command and Control
Feb 09, 2024Future warfare will require Command and Control (C2) decision-making to occur in more complex, fast-paced, ill-structured, and demanding conditions. C2 will be further complicated by operational challenges such as Denied, Degraded, Intermittent, and Limited (DDIL) communications and the need to account for many data streams, potentially across multiple domains of operation. Yet, current C2 practices -- which stem from the industrial era rather than the emerging intelligence era -- are linear and time-consuming. Critically, these approaches may fail to maintain overmatch against adversaries on the future battlefield. To address these challenges, we propose a vision for future C2 based on robust partnerships between humans and artificial intelligence (AI) systems. This future vision is encapsulated in three operational impacts: streamlining the C2 operations process, maintaining unity of effort, and developing adaptive collective knowledge systems. This paper illustrates the envisaged future C2 capabilities, discusses the assumptions that shaped them, and describes how the proposed developments could transform C2 in future warfare.
Scalable Interactive Machine Learning for Future Command and Control
Feb 09, 2024
Future warfare will require Command and Control (C2) personnel to make decisions at shrinking timescales in complex and potentially ill-defined situations. Given the need for robust decision-making processes and decision-support tools, integration of artificial and human intelligence holds the potential to revolutionize the C2 operations process to ensure adaptability and efficiency in rapidly changing operational environments. We propose to leverage recent promising breakthroughs in interactive machine learning, in which humans can cooperate with machine learning algorithms to guide machine learning algorithm behavior. This paper identifies several gaps in state-of-the-art science and technology that future work should address to extend these approaches to function in complex C2 contexts. In particular, we describe three research focus areas that together, aim to enable scalable interactive machine learning (SIML): 1) developing human-AI interaction algorithms to enable planning in complex, dynamic situations; 2) fostering resilient human-AI teams through optimizing roles, configurations, and trust; and 3) scaling algorithms and human-AI teams for flexibility across a range of potential contexts and situations.
Crowd-PrefRL: Preference-Based Reward Learning from Crowds
Jan 17, 2024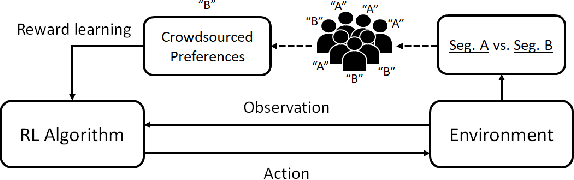
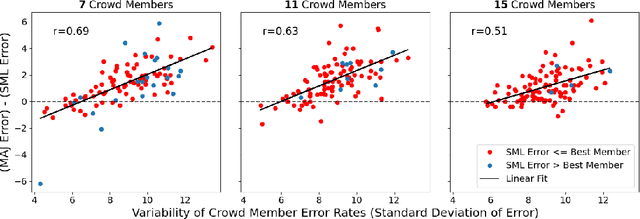
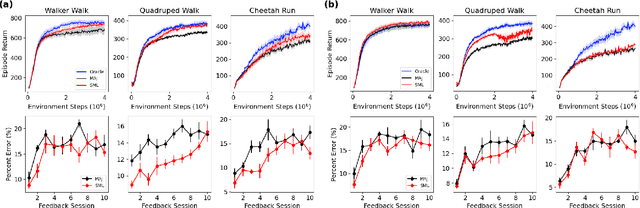
Preference-based reinforcement learning (RL) provides a framework to train agents using human feedback through pairwise preferences over pairs of behaviors, enabling agents to learn desired behaviors when it is difficult to specify a numerical reward function. While this paradigm leverages human feedback, it currently treats the feedback as given by a single human user. Meanwhile, incorporating preference feedback from crowds (i.e. ensembles of users) in a robust manner remains a challenge, and the problem of training RL agents using feedback from multiple human users remains understudied. In this work, we introduce Crowd-PrefRL, a framework for performing preference-based RL leveraging feedback from crowds. This work demonstrates the viability of learning reward functions from preference feedback provided by crowds of unknown expertise and reliability. Crowd-PrefRL not only robustly aggregates the crowd preference feedback, but also estimates the reliability of each user within the crowd using only the (noisy) crowdsourced preference comparisons. Most importantly, we show that agents trained with Crowd-PrefRL outperform agents trained with majority-vote preferences or preferences from any individual user in most cases, especially when the spread of user error rates among the crowd is large. Results further suggest that our method can identify minority viewpoints within the crowd.
Rating-based Reinforcement Learning
Jul 30, 2023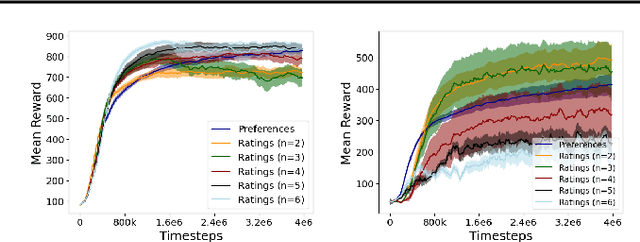

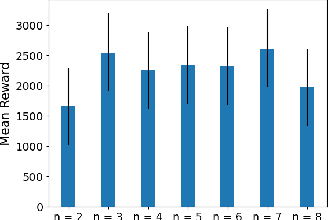
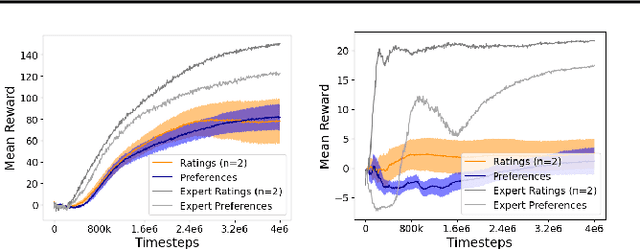
This paper develops a novel rating-based reinforcement learning approach that uses human ratings to obtain human guidance in reinforcement learning. Different from the existing preference-based and ranking-based reinforcement learning paradigms, based on human relative preferences over sample pairs, the proposed rating-based reinforcement learning approach is based on human evaluation of individual trajectories without relative comparisons between sample pairs. The rating-based reinforcement learning approach builds on a new prediction model for human ratings and a novel multi-class loss function. We conduct several experimental studies based on synthetic ratings and real human ratings to evaluate the effectiveness and benefits of the new rating-based reinforcement learning approach.
DIP-RL: Demonstration-Inferred Preference Learning in Minecraft
Jul 22, 2023

In machine learning for sequential decision-making, an algorithmic agent learns to interact with an environment while receiving feedback in the form of a reward signal. However, in many unstructured real-world settings, such a reward signal is unknown and humans cannot reliably craft a reward signal that correctly captures desired behavior. To solve tasks in such unstructured and open-ended environments, we present Demonstration-Inferred Preference Reinforcement Learning (DIP-RL), an algorithm that leverages human demonstrations in three distinct ways, including training an autoencoder, seeding reinforcement learning (RL) training batches with demonstration data, and inferring preferences over behaviors to learn a reward function to guide RL. We evaluate DIP-RL in a tree-chopping task in Minecraft. Results suggest that the method can guide an RL agent to learn a reward function that reflects human preferences and that DIP-RL performs competitively relative to baselines. DIP-RL is inspired by our previous work on combining demonstrations and pairwise preferences in Minecraft, which was awarded a research prize at the 2022 NeurIPS MineRL BASALT competition, Learning from Human Feedback in Minecraft. Example trajectory rollouts of DIP-RL and baselines are located at https://sites.google.com/view/dip-rl.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023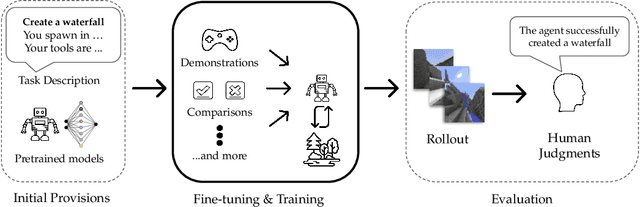

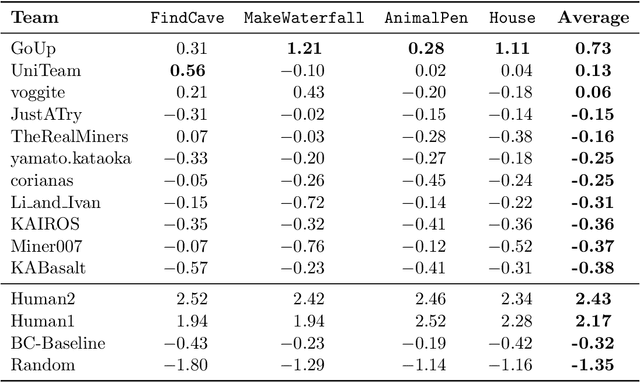
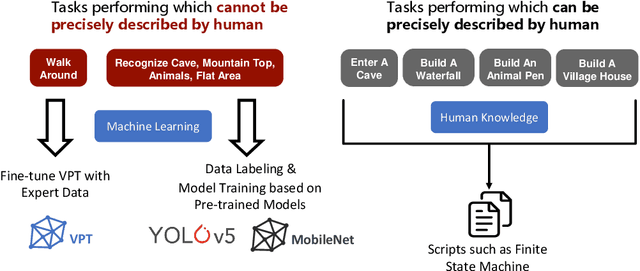
To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Efficient Preference-Based Reinforcement Learning Using Learned Dynamics Models
Jan 11, 2023



Preference-based reinforcement learning (PbRL) can enable robots to learn to perform tasks based on an individual's preferences without requiring a hand-crafted reward function. However, existing approaches either assume access to a high-fidelity simulator or analytic model or take a model-free approach that requires extensive, possibly unsafe online environment interactions. In this paper, we study the benefits and challenges of using a learned dynamics model when performing PbRL. In particular, we provide evidence that a learned dynamics model offers the following benefits when performing PbRL: (1) preference elicitation and policy optimization require significantly fewer environment interactions than model-free PbRL, (2) diverse preference queries can be synthesized safely and efficiently as a byproduct of standard model-based RL, and (3) reward pre-training based on suboptimal demonstrations can be performed without any environmental interaction. Our paper provides empirical evidence that learned dynamics models enable robots to learn customized policies based on user preferences in ways that are safer and more sample efficient than prior preference learning approaches.