 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Reward Learning from Human Ratings
Jun 10, 2025Reinforcement learning from human feeback (RLHF) has become a key factor in aligning model behavior with users' goals. However, while humans integrate multiple strategies when making decisions, current RLHF approaches often simplify this process by modeling human reasoning through isolated tasks such as classification or regression. In this paper, we propose a novel reinforcement learning (RL) method that mimics human decision-making by jointly considering multiple tasks. Specifically, we leverage human ratings in reward-free environments to infer a reward function, introducing learnable weights that balance the contributions of both classification and regression models. This design captures the inherent uncertainty in human decision-making and allows the model to adaptively emphasize different strategies. We conduct several experiments using synthetic human ratings to validate the effectiveness of the proposed approach. Results show that our method consistently outperforms existing rating-based RL methods, and in some cases, even surpasses traditional RL approaches.
Too Big to Think: Capacity, Memorization, and Generalization in Pre-Trained Transformers
Jun 10, 2025The relationship between memorization and generalization in large language models (LLMs) remains an open area of research, with growing evidence that the two are deeply intertwined. In this work, we investigate this relationship by pre-training a series of capacity-limited Transformer models from scratch on two synthetic character-level tasks designed to separately probe generalization (via arithmetic extrapolation) and memorization (via factual recall). We observe a consistent trade-off: small models extrapolate to unseen arithmetic cases but fail to memorize facts, while larger models memorize but fail to extrapolate. An intermediate-capacity model exhibits a similar shift toward memorization. When trained on both tasks jointly, no model (regardless of size) succeeds at extrapolation. These findings suggest that pre-training may intrinsically favor one learning mode over the other. By isolating these dynamics in a controlled setting, our study offers insight into how model capacity shapes learning behavior and offers broader implications for the design and deployment of small language models.
Performance Optimization of Ratings-Based Reinforcement Learning
Jan 13, 2025



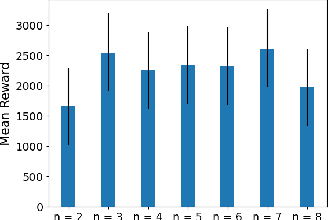
This paper explores multiple optimization methods to improve the performance of rating-based reinforcement learning (RbRL). RbRL, a method based on the idea of human ratings, has been developed to infer reward functions in reward-free environments for the subsequent policy learning via standard reinforcement learning, which requires the availability of reward functions. Specifically, RbRL minimizes the cross entropy loss that quantifies the differences between human ratings and estimated ratings derived from the inferred reward. Hence, a low loss means a high degree of consistency between human ratings and estimated ratings. Despite its simple form, RbRL has various hyperparameters and can be sensitive to various factors. Therefore, it is critical to provide comprehensive experiments to understand the impact of various hyperparameters on the performance of RbRL. This paper is a work in progress, providing users some general guidelines on how to select hyperparameters in RbRL.
RbRL2.0: Integrated Reward and Policy Learning for Rating-based Reinforcement Learning
Jan 13, 2025Reinforcement learning (RL), a common tool in decision making, learns policies from various experiences based on the associated cumulative return/rewards without treating them differently. On the contrary, humans often learn to distinguish from different levels of performance and extract the underlying trends towards improving their decision making for best performance. Motivated by this, this paper proposes a novel RL method that mimics humans' decision making process by differentiating among collected experiences for effective policy learning. The main idea is to extract important directional information from experiences with different performance levels, named ratings, so that policies can be updated towards desired deviation from these experiences with different ratings. Specifically, we propose a new policy loss function that penalizes distribution similarities between the current policy and failed experiences with different ratings, and assign different weights to the penalty terms based on the rating classes. Meanwhile, reward learning from these rated samples can be integrated with the new policy loss towards an integrated reward and policy learning from rated samples. Optimizing the integrated reward and policy loss function will lead to the discovery of directions for policy improvement towards maximizing cumulative rewards and penalizing most from the lowest performance level while least from the highest performance level. To evaluate the effectiveness of the proposed method, we present results for experiments on a few typical environments that show improved convergence and overall performance over the existing rating-based reinforcement learning method with only reward learning.
Atari-GPT: Investigating the Capabilities of Multimodal Large Language Models as Low-Level Policies for Atari Games
Aug 28, 2024Recent advancements in large language models (LLMs) have expanded their capabilities beyond traditional text-based tasks to multimodal domains, integrating visual, auditory, and textual data. While multimodal LLMs have been extensively explored for high-level planning in domains like robotics and games, their potential as low-level controllers remains largely untapped. This paper explores the application of multimodal LLMs as low-level controllers in the domain of Atari video games, introducing Atari game performance as a new benchmark for evaluating the ability of multimodal LLMs to perform low-level control tasks. Unlike traditional reinforcement learning (RL) and imitation learning (IL) methods that require extensive computational resources as well as reward function specification, these LLMs utilize pre-existing multimodal knowledge to directly engage with game environments. Our study assesses multiple multimodal LLMs performance against traditional RL agents, human players, and random agents, focusing on their ability to understand and interact with complex visual scenes and formulate strategic responses. Additionally, we examine the impact of In-Context Learning (ICL) by incorporating human-demonstrated game-play trajectories to enhance the models contextual understanding. Through this investigation, we aim to determine the extent to which multimodal LLMs can leverage their extensive training to effectively function as low-level controllers, thereby redefining potential applications in dynamic and visually complex environments. Additional results and videos are available at our project webpage: https://sites.google.com/view/atari-gpt/.
Rating-based Reinforcement Learning
Jul 30, 2023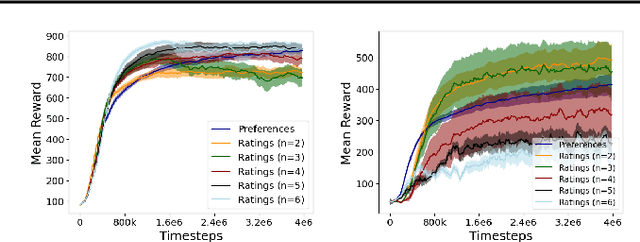

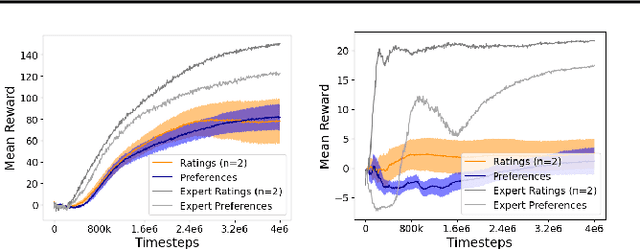
This paper develops a novel rating-based reinforcement learning approach that uses human ratings to obtain human guidance in reinforcement learning. Different from the existing preference-based and ranking-based reinforcement learning paradigms, based on human relative preferences over sample pairs, the proposed rating-based reinforcement learning approach is based on human evaluation of individual trajectories without relative comparisons between sample pairs. The rating-based reinforcement learning approach builds on a new prediction model for human ratings and a novel multi-class loss function. We conduct several experimental studies based on synthetic ratings and real human ratings to evaluate the effectiveness and benefits of the new rating-based reinforcement learning approach.