 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngagement-Zone-Aware Input-Constrained Guidance for Safe Target Interception in Contested Environments
Mar 24, 2026We address target interception in contested environments in the presence of multiple defenders whose interception capability is limited by finite ranges. Conventional methods typically impose conservative stand-off constraints based on maximum engagement distance and neglect the interceptors' actuator limitations. Instead, we formulate safety constraints using defender-induced engagement zones. To account for actuator limits, the vehicle model is augmented with input saturation dynamics. A time-varying safe-set tightening parameter is introduced to compensate for transient constraint violations induced by actuator dynamics. To ensure scalable safety enforcement in multi-defender scenarios, a smooth aggregate safety function is constructed using a log-sum-exp operator combining individual threat measures associated with each defender's capability. A smooth switching guidance strategy is then developed to coordinate interception and safety objectives. The attacker pursues the target when sufficiently distant from threat boundaries and progressively activates evasive motion as the EZ boundaries are approached. The resulting controller relies only on relative measurements and does not require knowledge of defender control inputs, thus facilitating a fully distributed and scalable implementation. Rigorous analysis provides sufficient conditions guaranteeing target interception, practical safety with respect to all defender engagement zones, and satisfaction of actuator bounds. An input-constrained guidance law based on conservative stand-off distance is also developed to quantify the conservatism of maximum-range-based safety formulations. Simulations with stationary and maneuvering defenders demonstrate that the proposed formulation yields shorter interception paths and reduced interception time compared with conventional methods while maintaining safety throughout the engagement.
Multi-Task Reward Learning from Human Ratings
Jun 10, 2025Reinforcement learning from human feeback (RLHF) has become a key factor in aligning model behavior with users' goals. However, while humans integrate multiple strategies when making decisions, current RLHF approaches often simplify this process by modeling human reasoning through isolated tasks such as classification or regression. In this paper, we propose a novel reinforcement learning (RL) method that mimics human decision-making by jointly considering multiple tasks. Specifically, we leverage human ratings in reward-free environments to infer a reward function, introducing learnable weights that balance the contributions of both classification and regression models. This design captures the inherent uncertainty in human decision-making and allows the model to adaptively emphasize different strategies. We conduct several experiments using synthetic human ratings to validate the effectiveness of the proposed approach. Results show that our method consistently outperforms existing rating-based RL methods, and in some cases, even surpasses traditional RL approaches.
RbRL2.0: Integrated Reward and Policy Learning for Rating-based Reinforcement Learning
Jan 13, 2025Reinforcement learning (RL), a common tool in decision making, learns policies from various experiences based on the associated cumulative return/rewards without treating them differently. On the contrary, humans often learn to distinguish from different levels of performance and extract the underlying trends towards improving their decision making for best performance. Motivated by this, this paper proposes a novel RL method that mimics humans' decision making process by differentiating among collected experiences for effective policy learning. The main idea is to extract important directional information from experiences with different performance levels, named ratings, so that policies can be updated towards desired deviation from these experiences with different ratings. Specifically, we propose a new policy loss function that penalizes distribution similarities between the current policy and failed experiences with different ratings, and assign different weights to the penalty terms based on the rating classes. Meanwhile, reward learning from these rated samples can be integrated with the new policy loss towards an integrated reward and policy learning from rated samples. Optimizing the integrated reward and policy loss function will lead to the discovery of directions for policy improvement towards maximizing cumulative rewards and penalizing most from the lowest performance level while least from the highest performance level. To evaluate the effectiveness of the proposed method, we present results for experiments on a few typical environments that show improved convergence and overall performance over the existing rating-based reinforcement learning method with only reward learning.
Performance Optimization of Ratings-Based Reinforcement Learning
Jan 13, 2025



This paper explores multiple optimization methods to improve the performance of rating-based reinforcement learning (RbRL). RbRL, a method based on the idea of human ratings, has been developed to infer reward functions in reward-free environments for the subsequent policy learning via standard reinforcement learning, which requires the availability of reward functions. Specifically, RbRL minimizes the cross entropy loss that quantifies the differences between human ratings and estimated ratings derived from the inferred reward. Hence, a low loss means a high degree of consistency between human ratings and estimated ratings. Despite its simple form, RbRL has various hyperparameters and can be sensitive to various factors. Therefore, it is critical to provide comprehensive experiments to understand the impact of various hyperparameters on the performance of RbRL. This paper is a work in progress, providing users some general guidelines on how to select hyperparameters in RbRL.
Adaptive Event-triggered Reinforcement Learning Control for Complex Nonlinear Systems
Sep 29, 2024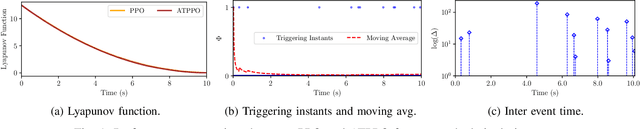
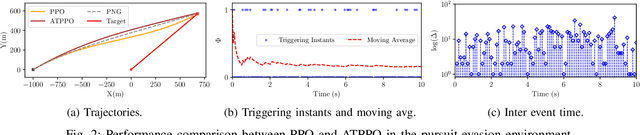
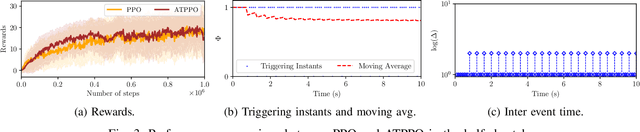
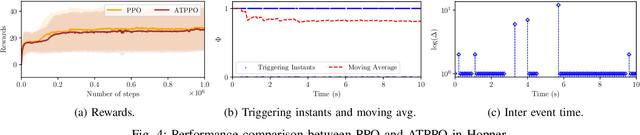
In this paper, we propose an adaptive event-triggered reinforcement learning control for continuous-time nonlinear systems, subject to bounded uncertainties, characterized by complex interactions. Specifically, the proposed method is capable of jointly learning both the control policy and the communication policy, thereby reducing the number of parameters and computational overhead when learning them separately or only one of them. By augmenting the state space with accrued rewards that represent the performance over the entire trajectory, we show that accurate and efficient determination of triggering conditions is possible without the need for explicit learning triggering conditions, thereby leading to an adaptive non-stationary policy. Finally, we provide several numerical examples to demonstrate the effectiveness of the proposed approach.
3D Guidance Law for Maximal Coverage and Target Enclosing with Inherent Safety
Apr 25, 2024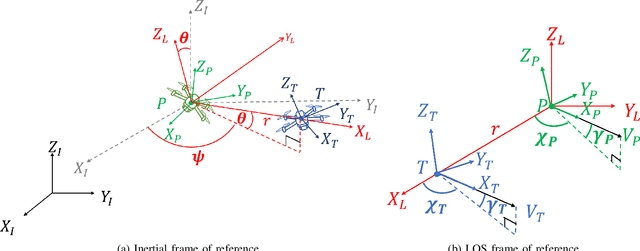
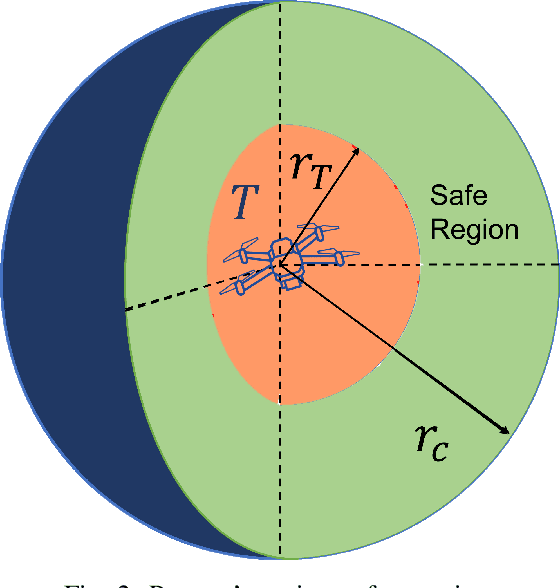
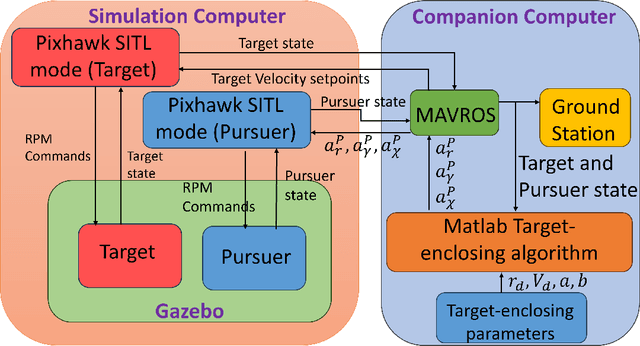
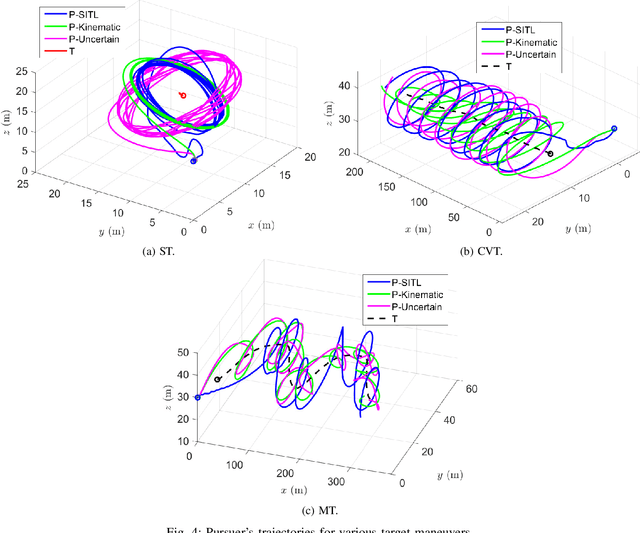
In this paper, we address the problem of enclosing an arbitrarily moving target in three dimensions by a single pursuer, which is an unmanned aerial vehicle (UAV), for maximum coverage while also ensuring the pursuer's safety by preventing collisions with the target. The proposed guidance strategy steers the pursuer to a safe region of space surrounding the target, allowing it to maintain a certain distance from the latter while offering greater flexibility in positioning and converging to any orbit within this safe zone. Our approach is distinguished by the use of nonholonomic constraints to model vehicles with accelerations serving as control inputs and coupled engagement kinematics to craft the pursuer's guidance law meticulously. Furthermore, we leverage the concept of the Lyapunov Barrier Function as a powerful tool to constrain the distance between the pursuer and the target within asymmetric bounds, thereby ensuring the pursuer's safety within the predefined region. To validate the efficacy and robustness of our algorithm, we conduct experimental tests by implementing a high-fidelity quadrotor model within Software-in-the-loop (SITL) simulations, encompassing various challenging target maneuver scenarios. The results obtained showcase the resilience of the proposed guidance law, effectively handling arbitrarily maneuvering targets, vehicle/autopilot dynamics, and external disturbances. Our method consistently delivers stable global enclosing behaviors, even in response to aggressive target maneuvers, and requires only relative information for successful execution.
Self-organizing Multiagent Target Enclosing under Limited Information and Safety Guarantees
Apr 06, 2024This paper introduces an approach to address the target enclosing problem using non-holonomic multiagent systems, where agents autonomously self-organize themselves in the desired formation around a fixed target. Our approach combines global enclosing behavior and local collision avoidance mechanisms by devising a novel potential function and sliding manifold. In our approach, agents independently move toward the desired enclosing geometry when apart and activate the collision avoidance mechanism when a collision is imminent, thereby guaranteeing inter-agent safety. We rigorously show that an agent does not need to ensure safety with every other agent and put forth a concept of the nearest colliding agent (for any arbitrary agent) with whom ensuring safety is sufficient to avoid collisions in the entire swarm. The proposed control eliminates the need for a fixed or pre-established agent arrangement around the target and requires only relative information between an agent and the target. This makes our design particularly appealing for scenarios with limited global information, hence significantly reducing communication requirements. We finally present simulation results to vindicate the efficacy of the proposed method.
Rating-based Reinforcement Learning
Jul 30, 2023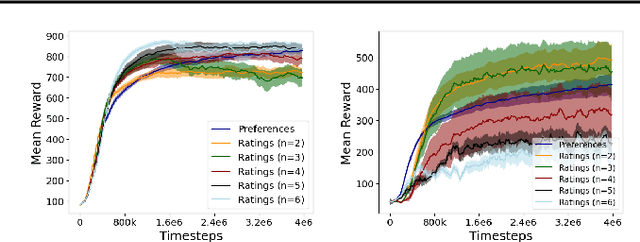

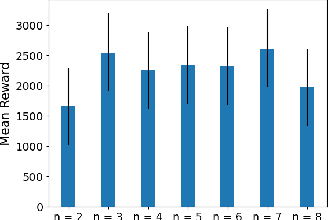
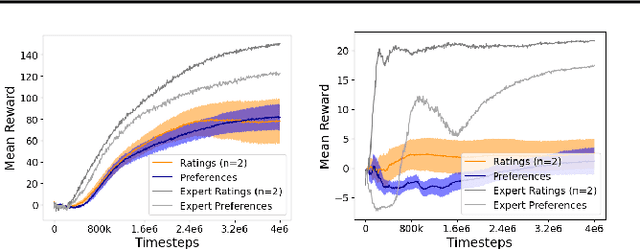
This paper develops a novel rating-based reinforcement learning approach that uses human ratings to obtain human guidance in reinforcement learning. Different from the existing preference-based and ranking-based reinforcement learning paradigms, based on human relative preferences over sample pairs, the proposed rating-based reinforcement learning approach is based on human evaluation of individual trajectories without relative comparisons between sample pairs. The rating-based reinforcement learning approach builds on a new prediction model for human ratings and a novel multi-class loss function. We conduct several experimental studies based on synthetic ratings and real human ratings to evaluate the effectiveness and benefits of the new rating-based reinforcement learning approach.
Fairness in Preference-based Reinforcement Learning
Jun 16, 2023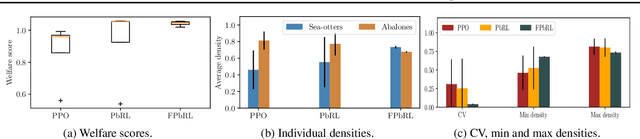
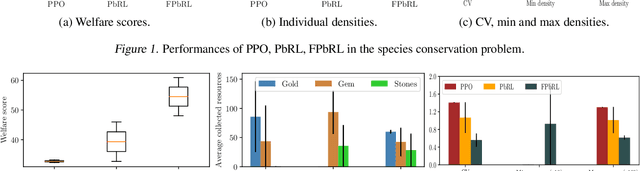
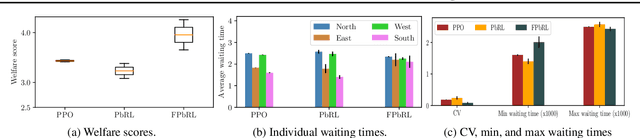
In this paper, we address the issue of fairness in preference-based reinforcement learning (PbRL) in the presence of multiple objectives. The main objective is to design control policies that can optimize multiple objectives while treating each objective fairly. Toward this objective, we design a new fairness-induced preference-based reinforcement learning or FPbRL. The main idea of FPbRL is to learn vector reward functions associated with multiple objectives via new welfare-based preferences rather than reward-based preference in PbRL, coupled with policy learning via maximizing a generalized Gini welfare function. Finally, we provide experiment studies on three different environments to show that the proposed FPbRL approach can achieve both efficiency and equity for learning effective and fair policies.
Human-guided Robot Behavior Learning: A GAN-assisted Preference-based Reinforcement Learning Approach
Oct 15, 2020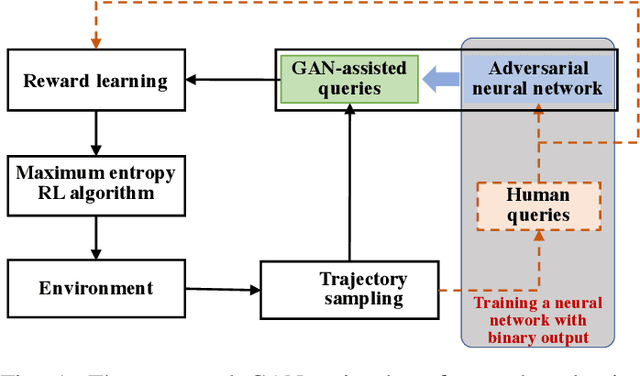
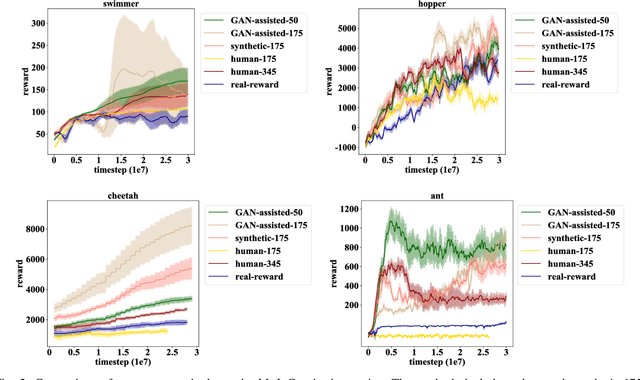
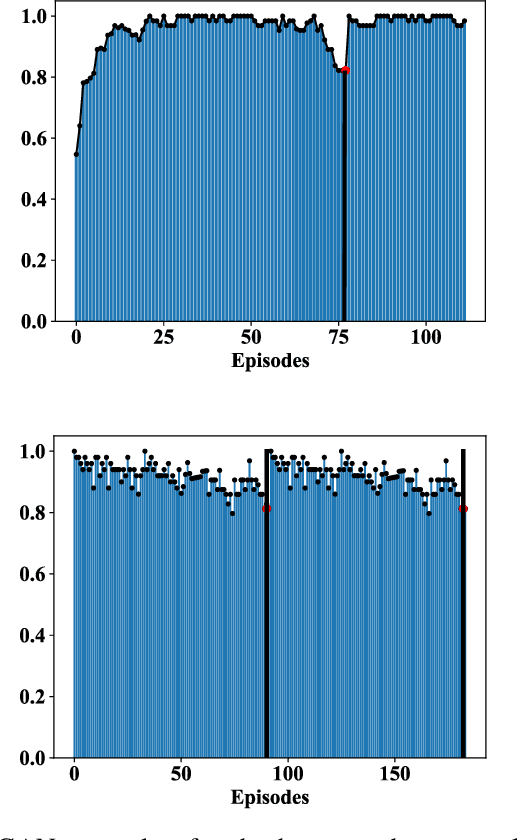
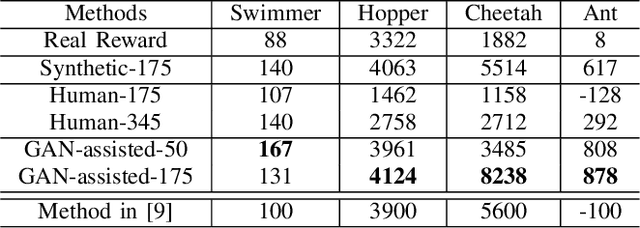
Human demonstrations can provide trustful samples to train reinforcement learning algorithms for robots to learn complex behaviors in real-world environments. However, obtaining sufficient demonstrations may be impractical because many behaviors are difficult for humans to demonstrate. A more practical approach is to replace human demonstrations by human queries, i.e., preference-based reinforcement learning. One key limitation of the existing algorithms is the need for a significant amount of human queries because a large number of labeled data is needed to train neural networks for the approximation of a continuous, high-dimensional reward function. To reduce and minimize the need for human queries, we propose a new GAN-assisted human preference-based reinforcement learning approach that uses a generative adversarial network (GAN) to actively learn human preferences and then replace the role of human in assigning preferences. The adversarial neural network is simple and only has a binary output, hence requiring much less human queries to train. Moreover, a maximum entropy based reinforcement learning algorithm is designed to shape the loss towards the desired regions or away from the undesired regions. To show the effectiveness of the proposed approach, we present some studies on complex robotic tasks without access to the environment reward in a typical MuJoCo robot locomotion environment. The obtained results show our method can achieve a reduction of about 99.8% human time without performance sacrifice.