 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Preference-based Reinforcement Learning
Paper and Code
Jun 16, 2023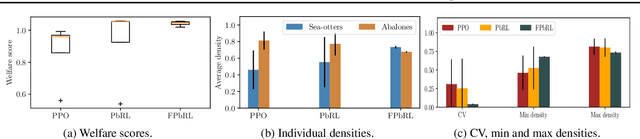
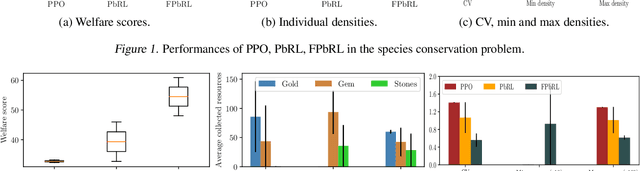
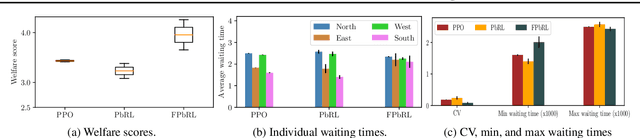
In this paper, we address the issue of fairness in preference-based reinforcement learning (PbRL) in the presence of multiple objectives. The main objective is to design control policies that can optimize multiple objectives while treating each objective fairly. Toward this objective, we design a new fairness-induced preference-based reinforcement learning or FPbRL. The main idea of FPbRL is to learn vector reward functions associated with multiple objectives via new welfare-based preferences rather than reward-based preference in PbRL, coupled with policy learning via maximizing a generalized Gini welfare function. Finally, we provide experiment studies on three different environments to show that the proposed FPbRL approach can achieve both efficiency and equity for learning effective and fair policies.