 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal Time and Angle-Constrained Nonlinear Intercept Guidance
Jun 01, 2026This paper considers the problem of simultaneously controlling an interceptor's impact time and impact angle using its lateral acceleration as the sole control input. With a single control input, the nonlinear engagement kinematics is inherently underactuated, which complicates guidance law synthesis. To overcome this challenge, a hierarchical sliding mode-based guidance law is developed to concurrently regulate the two terminal constraints. The proposed architecture consists of a two-layer sliding manifold. The first layer comprises two sub-sliding surfaces corresponding to the impact time and impact angle error dynamics, respectively, while the second layer introduces a composite sliding manifold that combines the two individual sub-surfaces. Then, a variable-gain adaptive guidance law is designed to ensure time and angle-constrained interception against a stationary target, which is further extended to intercept a constant velocity target. Simulations are conducted for various engagement scenarios to attest to the efficacy of the proposed approach.
Bounded-Input True Proportional Navigation for Impact-Time Control
May 13, 2026This paper proposes a nonlinear guidance strategy capable of intercepting a constant-velocity, non-maneuvering target while strictly satisfying the prescribed bounds on the control input (commanded acceleration). Unlike conventional strategies that estimate time-to-go using linearization or small-angle approximations, the proposed strategy employs true proportional-navigation guidance (TPNG) as a baseline, which utilizes an exact time-to-go formulation and is applicable over a wide range of target motions. In contrast to most existing strategies, which do not incorporate control input bounds into the guidance design, the proposed approach explicitly accounts for these limits by modeling the interceptor acceleration as a dynamic variable. Based on the sliding mode control technique, an effective guidance law that achieves time-constrained interception while accounting for bounded input is then derived. The performance of the proposed strategy is evaluated for various engagement scenarios.
Engagement-Zone-Aware Input-Constrained Guidance for Safe Target Interception in Contested Environments
Mar 24, 2026We address target interception in contested environments in the presence of multiple defenders whose interception capability is limited by finite ranges. Conventional methods typically impose conservative stand-off constraints based on maximum engagement distance and neglect the interceptors' actuator limitations. Instead, we formulate safety constraints using defender-induced engagement zones. To account for actuator limits, the vehicle model is augmented with input saturation dynamics. A time-varying safe-set tightening parameter is introduced to compensate for transient constraint violations induced by actuator dynamics. To ensure scalable safety enforcement in multi-defender scenarios, a smooth aggregate safety function is constructed using a log-sum-exp operator combining individual threat measures associated with each defender's capability. A smooth switching guidance strategy is then developed to coordinate interception and safety objectives. The attacker pursues the target when sufficiently distant from threat boundaries and progressively activates evasive motion as the EZ boundaries are approached. The resulting controller relies only on relative measurements and does not require knowledge of defender control inputs, thus facilitating a fully distributed and scalable implementation. Rigorous analysis provides sufficient conditions guaranteeing target interception, practical safety with respect to all defender engagement zones, and satisfaction of actuator bounds. An input-constrained guidance law based on conservative stand-off distance is also developed to quantify the conservatism of maximum-range-based safety formulations. Simulations with stationary and maneuvering defenders demonstrate that the proposed formulation yields shorter interception paths and reduced interception time compared with conventional methods while maintaining safety throughout the engagement.
Predefined-time One-Shot Cooperative Estimation, Guidance, and Control for Simultaneous Target Interception
Jan 12, 2026This work develops a unified nonlinear estimation-guidance-control framework for cooperative simultaneous interception of a stationary target under a heterogeneous sensing topology, where sensing capabilities are non-uniform across interceptors. Specifically, only a subset of agents is instrumented with onboard seekers (informed/seeker-equipped agents), whereas the rest of them (seeker-less agents) acquire the information about the target indirectly via the informed agents and execute a distributed cooperative guidance for simultaneous target interception. To address the resulting partial observability, a predefined-time distributed observer is leveraged, guaranteeing convergence of the target state estimates for seeker-less agents through information exchange with seeker-equipped neighbors over a directed communication graph. Thereafter, an improved time-to-go estimate accounting for wide launch envelopes is utilized to design the distributed cooperative guidance commands. This estimate is coupled with a predefined-time consensus protocol, ensuring consensus in the agents' time-to-go values. The temporal upper bounds within which both observer error and time-to-go consensus error converge to zero can be prescribed as design parameters. Furthermore, the cooperative guidance commands are realized by means of an autopilot, wherein the interceptor is steered by canard actuation. The corresponding fin deflection commands are generated using a predefined-time convergent sliding mode control law. This enables the autopilot to precisely track the commanded lateral acceleration within a design-specified time, while maintaining non-singularity of the overall design. Theoretical guarantees are supported by numerical simulations across diverse engagement geometries, verifying the estimation accuracy, the cooperative interception performance, and the autopilot response using the proposed scheme.
Cooperative Integrated Estimation-Guidance for Simultaneous Interception of Moving Targets
Oct 30, 2025This paper proposes a cooperative integrated estimation-guidance framework for simultaneous interception of a non-maneuvering target using a team of unmanned autonomous vehicles, assuming only a subset of vehicles are equipped with dedicated sensors to measure the target's states. Unlike earlier approaches that focus solely on either estimation or guidance design, the proposed framework unifies both within a cooperative architecture. To circumvent the limitation posed by heterogeneity in target observability, sensorless vehicles estimate the target's state by leveraging information exchanged with neighboring agents over a directed communication topology through a prescribed-time observer. The proposed approach employs true proportional navigation guidance (TPNG), which uses an exact time-to-go formulation and is applicable across a wide spectrum of target motions. Furthermore, prescribed-time observer and controller are employed to achieve convergence to true target's state and consensus in time-to-go within set predefined times, respectively. Simulations demonstrate the effectiveness of the proposed framework under various engagement scenarios.
Cooperative Guidance for Aerial Defense in Multiagent Systems
Oct 02, 2025This paper addresses a critical aerial defense challenge in contested airspace, involving three autonomous aerial vehicles -- a hostile drone (the pursuer), a high-value drone (the evader), and a protective drone (the defender). We present a cooperative guidance framework for the evader-defender team that guarantees interception of the pursuer before it can capture the evader, even under highly dynamic and uncertain engagement conditions. Unlike traditional heuristic, optimal control, or differential game-based methods, we approach the problem within a time-constrained guidance framework, leveraging true proportional navigation based approach that ensures robust and guaranteed solutions to the aerial defense problem. The proposed strategy is computationally lightweight, scalable to a large number of agent configurations, and does not require knowledge of the pursuer's strategy or control laws. From arbitrary initial geometries, our method guarantees that key engagement errors are driven to zero within a fixed time, leading to a successful mission. Extensive simulations across diverse and adversarial scenarios confirm the effectiveness of the proposed strategy and its relevance for real-time autonomous defense in contested airspace environments.
Nonlinear Cooperative Salvo Guidance with Seeker-Limited Interceptors
Sep 18, 2025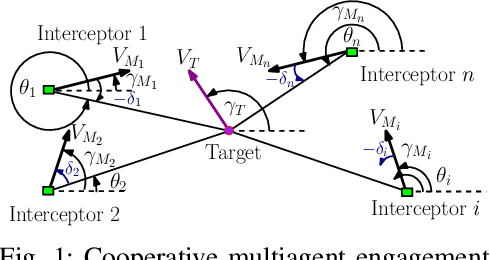
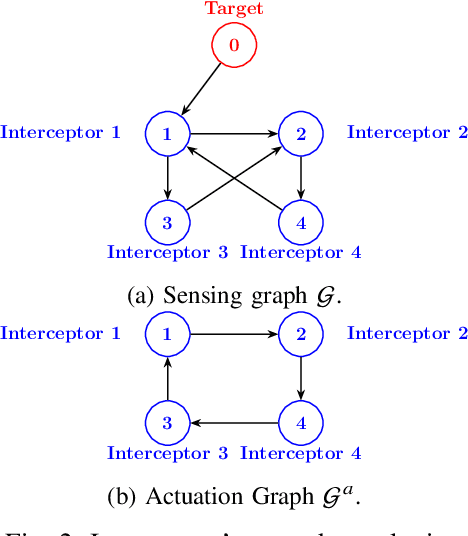
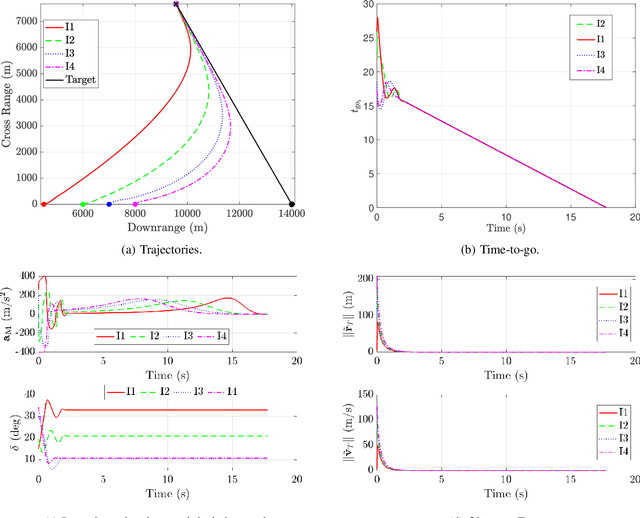
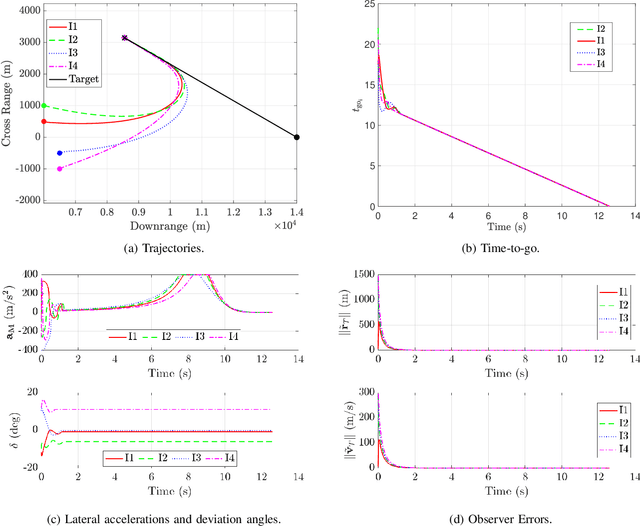
This paper presents a cooperative guidance strategy for the simultaneous interception of a constant-velocity, non-maneuvering target, addressing the realistic scenario where only a subset of interceptors are equipped with onboard seekers. To overcome the resulting heterogeneity in target observability, a fixed-time distributed observer is employed, enabling seeker-less interceptors to estimate the target state using information from seeker-equipped agents and local neighbors over a directed communication topology. Departing from conventional strategies that approximate time-to-go via linearization or small-angle assumptions, the proposed approach leverages deviated pursuit guidance where the time-to-go expression is exact for such a target. Moreover, a higher-order sliding mode consensus protocol is utilized to establish time-to-go consensus within a finite time. The effectiveness of the proposed guidance and estimation architecture is demonstrated through simulations.
Cooperative Target Capture in 3D Engagements over Switched Dynamic Graphs
Jul 02, 2025This paper presents a leaderless cooperative guidance strategy for simultaneous time-constrained interception of a stationary target when the interceptors exchange information over switched dynamic graphs. We specifically focus on scenarios when the interceptors lack radial acceleration capabilities, relying solely on their lateral acceleration components. This consideration aligns with their inherent kinematic turn constraints. The proposed strategy explicitly addresses the complexities of coupled 3D engagements, thereby mitigating performance degradation that typically arises when the pitch and yaw channels are decoupled into two separate, mutually orthogonal planar engagements. Moreover, our formulation incorporates modeling uncertainties associated with the time-to-go estimation into the derivation of cooperative guidance commands to ensure robustness against inaccuracies in dynamic engagement scenarios. To optimize control efficiency, we analytically derive the lateral acceleration components in the orthogonal pitch and yaw channels by solving an instantaneous optimization problem, subject to an affine constraint. We show that the proposed cooperative guidance commands guarantee consensus in time-to-go values within a predefined time, which can be prescribed as a design parameter, regardless of the interceptors' initial configurations. We provide simulations to attest to the efficacy of the proposed method.
Adaptive Event-triggered Reinforcement Learning Control for Complex Nonlinear Systems
Sep 29, 2024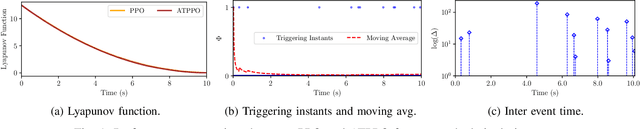
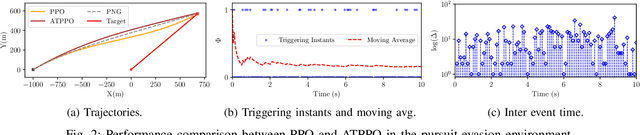
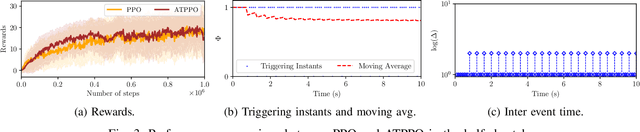
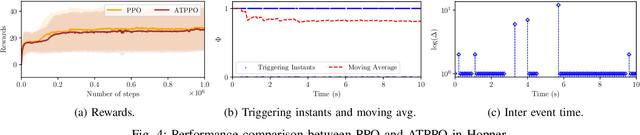
In this paper, we propose an adaptive event-triggered reinforcement learning control for continuous-time nonlinear systems, subject to bounded uncertainties, characterized by complex interactions. Specifically, the proposed method is capable of jointly learning both the control policy and the communication policy, thereby reducing the number of parameters and computational overhead when learning them separately or only one of them. By augmenting the state space with accrued rewards that represent the performance over the entire trajectory, we show that accurate and efficient determination of triggering conditions is possible without the need for explicit learning triggering conditions, thereby leading to an adaptive non-stationary policy. Finally, we provide several numerical examples to demonstrate the effectiveness of the proposed approach.
Three-dimensional Nonlinear Path-following Guidance with Bounded Input Constraints
Sep 13, 2024In this paper, we consider the tracking of arbitrary curvilinear geometric paths in three-dimensional output spaces of unmanned aerial vehicles (UAVs) without pre-specified timing requirements, commonly referred to as path-following problems, subjected to bounded inputs. Specifically, we propose a novel nonlinear path-following guidance law for a UAV that enables it to follow any smooth curvilinear path in three dimensions while accounting for the bounded control authority in the design. The proposed solution offers a general treatment of the path-following problem by removing the dependency on the path's geometry, which makes it applicable to paths with varying levels of complexity and smooth curvatures. Additionally, the proposed strategy draws inspiration from the pursuit guidance approach, which is known for its simplicity and ease of implementation. Theoretical analysis guarantees that the UAV converges to its desired path within a fixed time and remains on it irrespective of its initial configuration with respect to the path. Finally, the simulations demonstrate the merits and effectiveness of the proposed guidance strategy through a wide range of engagement scenarios, showcasing the UAV's ability to follow diverse curvilinear paths accurately.