 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Event-triggered Reinforcement Learning Control for Complex Nonlinear Systems
Sep 29, 2024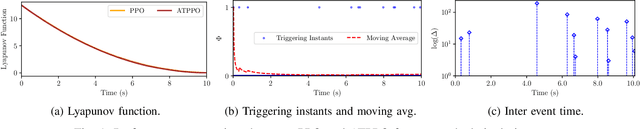
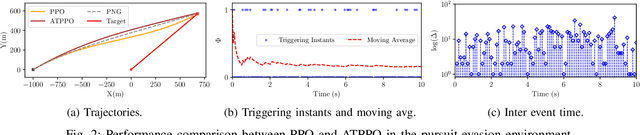
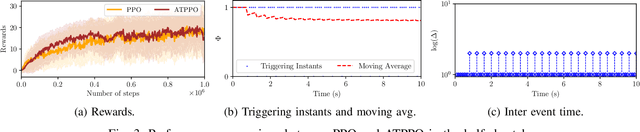
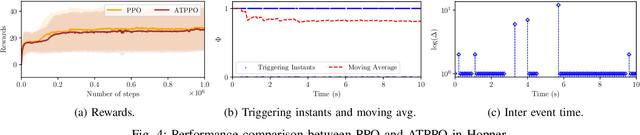
In this paper, we propose an adaptive event-triggered reinforcement learning control for continuous-time nonlinear systems, subject to bounded uncertainties, characterized by complex interactions. Specifically, the proposed method is capable of jointly learning both the control policy and the communication policy, thereby reducing the number of parameters and computational overhead when learning them separately or only one of them. By augmenting the state space with accrued rewards that represent the performance over the entire trajectory, we show that accurate and efficient determination of triggering conditions is possible without the need for explicit learning triggering conditions, thereby leading to an adaptive non-stationary policy. Finally, we provide several numerical examples to demonstrate the effectiveness of the proposed approach.
Fairness in Preference-based Reinforcement Learning
Jun 16, 2023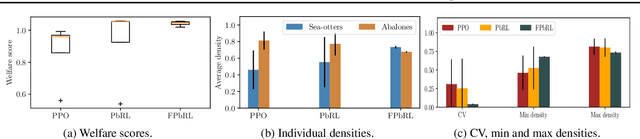
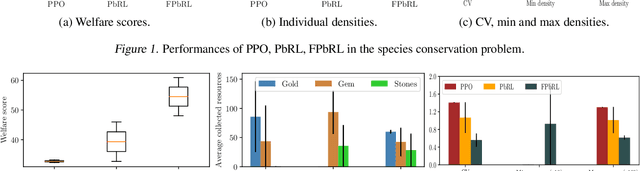
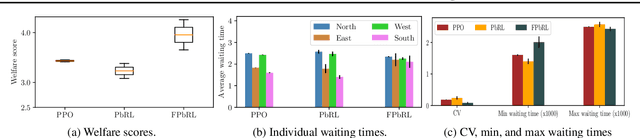
In this paper, we address the issue of fairness in preference-based reinforcement learning (PbRL) in the presence of multiple objectives. The main objective is to design control policies that can optimize multiple objectives while treating each objective fairly. Toward this objective, we design a new fairness-induced preference-based reinforcement learning or FPbRL. The main idea of FPbRL is to learn vector reward functions associated with multiple objectives via new welfare-based preferences rather than reward-based preference in PbRL, coupled with policy learning via maximizing a generalized Gini welfare function. Finally, we provide experiment studies on three different environments to show that the proposed FPbRL approach can achieve both efficiency and equity for learning effective and fair policies.
Learning Fair Policies in Decentralized Cooperative Multi-Agent Reinforcement Learning
Dec 17, 2020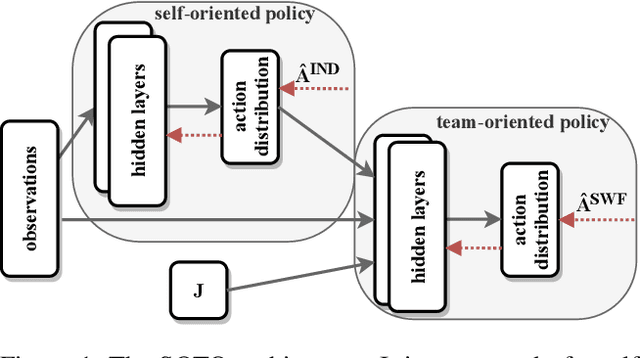
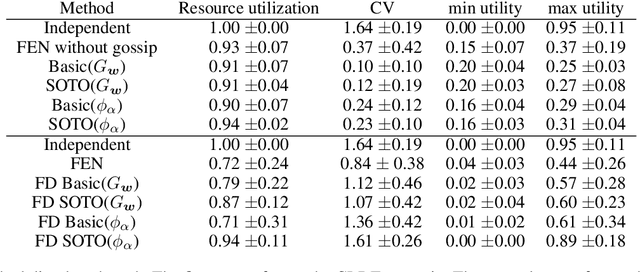
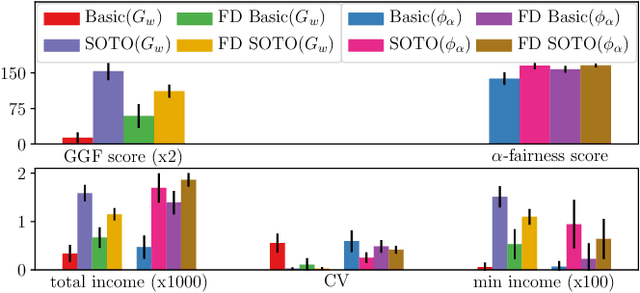
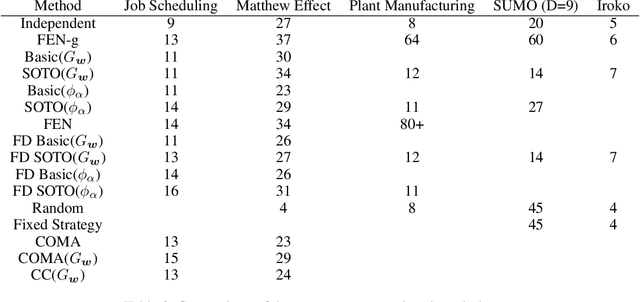
We consider the problem of learning fair policies in (deep) cooperative multi-agent reinforcement learning (MARL). We formalize it in a principled way as the problem of optimizing a welfare function that explicitly encodes two important aspects of fairness: efficiency and equity. As a solution method, we propose a novel neural network architecture, which is composed of two sub-networks specifically designed for taking into account the two aspects of fairness. In experiments, we demonstrate the importance of the two sub-networks for fair optimization. Our overall approach is general as it can accommodate any (sub)differentiable welfare function. Therefore, it is compatible with various notions of fairness that have been proposed in the literature (e.g., lexicographic maximin, generalized Gini social welfare function, proportional fairness). Our solution method is generic and can be implemented in various MARL settings: centralized training and decentralized execution, or fully decentralized. Finally, we experimentally validate our approach in various domains and show that it can perform much better than previous methods.
Learning Fair Policies in Multiobjective (Deep) Reinforcement Learning with Average and Discounted Rewards
Aug 18, 2020



As the operations of autonomous systems generally affect simultaneously several users, it is crucial that their designs account for fairness considerations. In contrast to standard (deep) reinforcement learning (RL), we investigate the problem of learning a policy that treats its users equitably. In this paper, we formulate this novel RL problem, in which an objective function, which encodes a notion of fairness that we formally define, is optimized. For this problem, we provide a theoretical discussion where we examine the case of discounted rewards and that of average rewards. During this analysis, we notably derive a new result in the standard RL setting, which is of independent interest: it states a novel bound on the approximation error with respect to the optimal average reward of that of a policy optimal for the discounted reward. Since learning with discounted rewards is generally easier, this discussion further justifies finding a fair policy for the average reward by learning a fair policy for the discounted reward. Thus, we describe how several classic deep RL algorithms can be adapted to our fair optimization problem, and we validate our approach with extensive experiments in three different domains.