 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Event-triggered Reinforcement Learning Control for Complex Nonlinear Systems
Paper and Code
Sep 29, 2024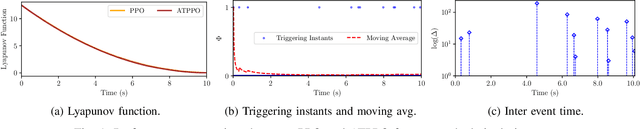
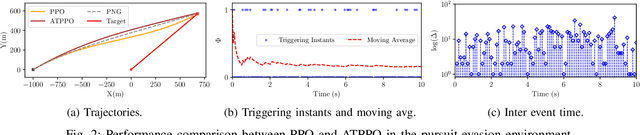
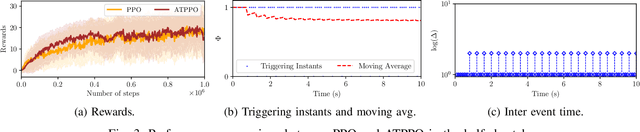
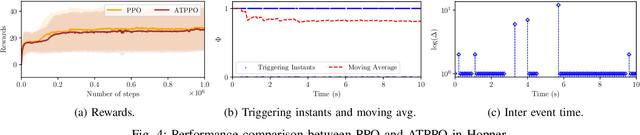
In this paper, we propose an adaptive event-triggered reinforcement learning control for continuous-time nonlinear systems, subject to bounded uncertainties, characterized by complex interactions. Specifically, the proposed method is capable of jointly learning both the control policy and the communication policy, thereby reducing the number of parameters and computational overhead when learning them separately or only one of them. By augmenting the state space with accrued rewards that represent the performance over the entire trajectory, we show that accurate and efficient determination of triggering conditions is possible without the need for explicit learning triggering conditions, thereby leading to an adaptive non-stationary policy. Finally, we provide several numerical examples to demonstrate the effectiveness of the proposed approach.