 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Controlled Lean-as-Judge for Natural-Language Mathematical Reasoning
May 27, 2026Lean is increasingly used to judge natural-language mathematical answers, but its signal is partial: many answers never formalize, and a failed proof may reflect an ill-typed statement or a missing library fact, not a wrong answer. On MATH-500 we show this signal is (i) sharply coverage-dependent, that is the proof-winning answer is correct 96% of the time at high proved coverage but 20% at low, and (ii) sparse and often unfaithful: a 7B autoformalizer proves a class for only 28% of problems, and a manual audit finds only approximately 43% of those proofs faithful. We propose COVCAL, a selector over Lean-trace diagnostics that certifies a finite-sample selective-risk bound on accepted answers or abstains, under two regimes (a conservative Bonferroni bound and a tighter dev-then-cal rule). Feasibility depends on autoformalization coverage: with the 7B formalizer the signal is too sparse and Bonferroni abstains on all 20 bootstrap partitions, whereas a prover-specialized formalizer reaches 79% coverage and flips it to feasible on 17 of 20, accepting approximately 48% of problems at 0.98 accepted accuracy. Since self-consistency alone is already 91% accurate, our contribution is a precise account of when, and with which formalizer, a partial formal signal can be trusted under risk control.
The Model Knows, the Decoder Finds: Future Value Guided Particle Power Sampling
May 04, 2026A recurring pattern in "reasoning without training" is that base LLMs already assign non-trivial probability mass to correct multi-step solutions; the bottleneck is locating these modes efficiently at inference time. Power sampling provides a principled way to bias decoding toward such modes by targeting p_theta(x)^alpha with alpha > 1, but practical approximations must account for future-dependent correction factors that determine which prefixes remain promising. We introduce Auxiliary Particle Power Sampling (APPS), a blockwise particle algorithm for approximating the sequence-level power target with a bounded population of partial solutions. APPS propagates hypotheses in parallel using proposal-corrected power reweighting and refines their survival through future-value-guided selection at resampling boundaries. This redistributes finite compute across competing prefixes rather than committing to a single unfolding path, while providing a direct scaling knob in the particle count and predictable peak memory. We instantiate the future-value signal with short-horizon rollouts and also study an amortized variant that replaces rollouts with a lightweight learned selection head. Across reasoning benchmarks, APPS improves the accuracy-runtime trade-off of training-free decoding and suggests that part of the gap to post-trained systems can be recovered through more faithful inference-time power approximation.
The $\mathbf{Y}$-Combinator for LLMs: Solving Long-Context Rot with $λ$-Calculus
Mar 20, 2026LLMs are increasingly used as general-purpose reasoners, but long inputs remain bottlenecked by a fixed context window. Recursive Language Models (RLMs) address this by externalising the prompt and recursively solving subproblems. Yet existing RLMs depend on an open-ended read-eval-print loop (REPL) in which the model generates arbitrary control code, making execution difficult to verify, predict, and analyse. We introduce $λ$-RLM, a framework for long-context reasoning that replaces free-form recursive code generation with a typed functional runtime grounded in $λ$-calculus. It executes a compact library of pre-verified combinators and uses neural inference only on bounded leaf subproblems, turning recursive reasoning into a structured functional program with explicit control flow. We show that $λ$-RLM admits formal guarantees absent from standard RLMs, including termination, closed-form cost bounds, controlled accuracy scaling with recursion depth, and an optimal partition rule under a simple cost model. Empirically, across four long-context reasoning tasks and nine base models, $λ$-RLM outperforms standard RLM in 29 of 36 model-task comparisons, improves average accuracy by up to +21.9 points across model tiers, and reduces latency by up to 4.1x. These results show that typed symbolic control yields a more reliable and efficient foundation for long-context reasoning than open-ended recursive code generation. The complete implementation of $λ$-RLM, is open-sourced for the community at: https://github.com/lambda-calculus-LLM/lambda-RLM.
Multi-Task GRPO: Reliable LLM Reasoning Across Tasks
Feb 05, 2026RL-based post-training with GRPO is widely used to improve large language models on individual reasoning tasks. However, real-world deployment requires reliable performance across diverse tasks. A straightforward multi-task adaptation of GRPO often leads to imbalanced outcomes, with some tasks dominating optimization while others stagnate. Moreover, tasks can vary widely in how frequently prompts yield zero advantages (and thus zero gradients), which further distorts their effective contribution to the optimization signal. To address these issues, we propose a novel Multi-Task GRPO (MT-GRPO) algorithm that (i) dynamically adapts task weights to explicitly optimize worst-task performance and promote balanced progress across tasks, and (ii) introduces a ratio-preserving sampler to ensure task-wise policy gradients reflect the adapted weights. Experiments on both 3-task and 9-task settings show that MT-GRPO consistently outperforms baselines in worst-task accuracy. In particular, MT-GRPO achieves 16-28% and 6% absolute improvement on worst-task performance over standard GRPO and DAPO, respectively, while maintaining competitive average accuracy. Moreover, MT-GRPO requires 50% fewer training steps to reach 50% worst-task accuracy in the 3-task setting, demonstrating substantially improved efficiency in achieving reliable performance across tasks.
Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening
Jan 29, 2026Reinforcement learning (RL) post-training is a dominant approach for improving the reasoning performance of large language models (LLMs), yet growing evidence suggests that its gains arise primarily from distribution sharpening rather than the acquisition of new capabilities. Recent work has shown that sampling from the power distribution of LLMs using Markov chain Monte Carlo (MCMC) can recover performance comparable to RL post-training without relying on external rewards; however, the high computational cost of MCMC makes such approaches impractical for widespread adoption. In this work, we propose a theoretically grounded alternative that eliminates the need for iterative MCMC. We derive a novel formulation showing that the global power distribution can be approximated by a token-level scaled low-temperature one, where the scaling factor captures future trajectory quality. Leveraging this insight, we introduce a training-free and verifier-free algorithm that sharpens the base model's generative distribution autoregressively. Empirically, we evaluate our method on math, QA, and code tasks across four LLMs, and show that our method matches or surpasses one-shot GRPO without relying on any external rewards, while reducing inference latency by over 10x compared to MCMC-based sampling.
Tree-OPO: Off-policy Monte Carlo Tree-Guided Advantage Optimization for Multistep Reasoning
Sep 11, 2025
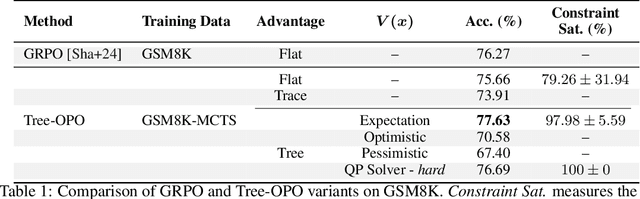


Recent advances in reasoning with large language models (LLMs) have shown the effectiveness of Monte Carlo Tree Search (MCTS) for generating high-quality intermediate trajectories, particularly in math and symbolic domains. Inspired by this, we explore how MCTS-derived trajectories, traditionally used for training value or reward models, can be repurposed to improve policy optimization in preference-based reinforcement learning (RL). Specifically, we focus on Group Relative Policy Optimization (GRPO), a recent algorithm that enables preference-consistent policy learning without value networks. We propose a staged GRPO training paradigm where completions are derived from partially revealed MCTS rollouts, introducing a novel tree-structured setting for advantage estimation. This leads to a rich class of prefix-conditioned reward signals, which we analyze theoretically and empirically. Our initial results indicate that while structured advantage estimation can stabilize updates and better reflect compositional reasoning quality, challenges such as advantage saturation and reward signal collapse remain. We propose heuristic and statistical solutions to mitigate these issues and discuss open challenges for learning under staged or tree-like reward structures.
Bourbaki: Self-Generated and Goal-Conditioned MDPs for Theorem Proving
Jul 03, 2025Reasoning remains a challenging task for large language models (LLMs), especially within the logically constrained environment of automated theorem proving (ATP), due to sparse rewards and the vast scale of proofs. These challenges are amplified in benchmarks like PutnamBench, which contains university-level problems requiring complex, multi-step reasoning. To address this, we introduce self-generated goal-conditioned MDPs (sG-MDPs), a new framework in which agents generate and pursue their subgoals based on the evolving proof state. Given this more structured generation of goals, the resulting problem becomes more amenable to search. We then apply Monte Carlo Tree Search (MCTS)-like algorithms to solve the sG-MDP, instantiating our approach in Bourbaki (7B), a modular system that can ensemble multiple 7B LLMs for subgoal generation and tactic synthesis. On PutnamBench, Bourbaki (7B) solves 26 problems, achieving new state-of-the-art results with models at this scale.
Almost Surely Safe Alignment of Large Language Models at Inference-Time
Feb 03, 2025Even highly capable large language models (LLMs) can produce biased or unsafe responses, and alignment techniques, such as RLHF, aimed at mitigating this issue, are expensive and prone to overfitting as they retrain the LLM. This paper introduces a novel inference-time alignment approach that ensures LLMs generate safe responses almost surely, i.e., with a probability approaching one. We achieve this by framing the safe generation of inference-time responses as a constrained Markov decision process within the LLM's latent space. Crucially, we augment a safety state that tracks the evolution of safety constraints and enables us to demonstrate formal safety guarantees upon solving the MDP in the latent space. Building on this foundation, we propose InferenceGuard, a practical implementation that safely aligns LLMs without modifying the model weights. Empirically, we demonstrate InferenceGuard effectively balances safety and task performance, outperforming existing inference-time alignment methods in generating safe and aligned responses.
Mixture of Attentions For Speculative Decoding
Oct 04, 2024The growth in the number of parameters of Large Language Models (LLMs) has led to a significant surge in computational requirements, making them challenging and costly to deploy. Speculative decoding (SD) leverages smaller models to efficiently propose future tokens, which are then verified by the LLM in parallel. Small models that utilise activations from the LLM currently achieve the fastest decoding speeds. However, we identify several limitations of SD models including the lack of on-policyness during training and partial observability. To address these shortcomings, we propose a more grounded architecture for small models by introducing a Mixture of Attentions for SD. Our novel architecture can be applied in two scenarios: a conventional single device deployment and a novel client-server deployment where the small model is hosted on a consumer device and the LLM on a server. In a single-device scenario, we demonstrate state-of-the-art speedups improving EAGLE-2 by 9.5% and its acceptance length by 25%. In a client-server setting, our experiments demonstrate: 1) state-of-the-art latencies with minimal calls to the server for different network conditions, and 2) in the event of a complete disconnection, our approach can maintain higher accuracy compared to other SD methods and demonstrates advantages over API calls to LLMs, which would otherwise be unable to continue the generation process.
ROS-LLM: A ROS framework for embodied AI with task feedback and structured reasoning
Jun 28, 2024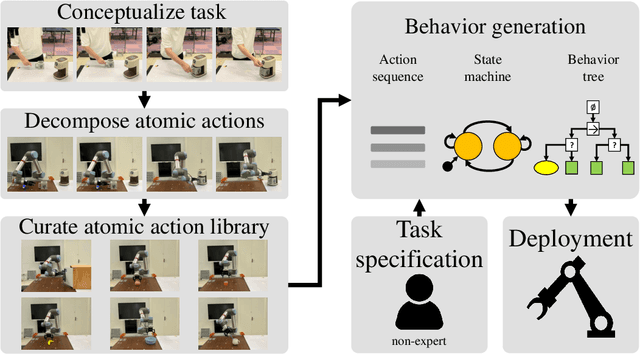
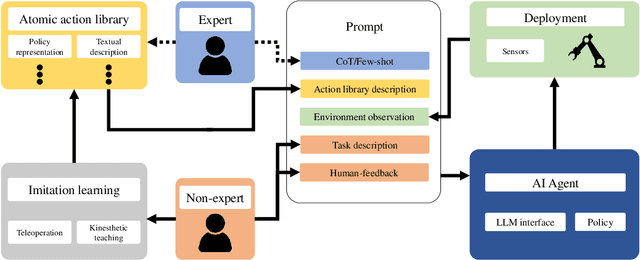
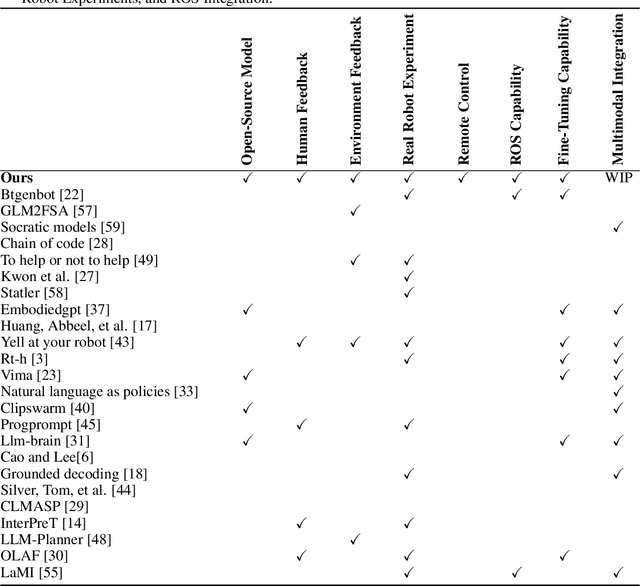
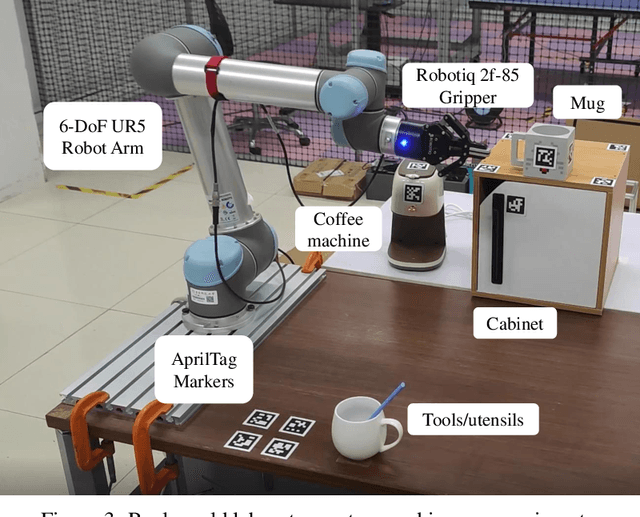
We present a framework for intuitive robot programming by non-experts, leveraging natural language prompts and contextual information from the Robot Operating System (ROS). Our system integrates large language models (LLMs), enabling non-experts to articulate task requirements to the system through a chat interface. Key features of the framework include: integration of ROS with an AI agent connected to a plethora of open-source and commercial LLMs, automatic extraction of a behavior from the LLM output and execution of ROS actions/services, support for three behavior modes (sequence, behavior tree, state machine), imitation learning for adding new robot actions to the library of possible actions, and LLM reflection via human and environment feedback. Extensive experiments validate the framework, showcasing robustness, scalability, and versatility in diverse scenarios, including long-horizon tasks, tabletop rearrangements, and remote supervisory control. To facilitate the adoption of our framework and support the reproduction of our results, we have made our code open-source. You can access it at: https://github.com/huawei-noah/HEBO/tree/master/ROSLLM.