 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViMo: A Generative Visual GUI World Model for App Agent
Apr 15, 2025App agents, which autonomously operate mobile Apps through Graphical User Interfaces (GUIs), have gained significant interest in real-world applications. Yet, they often struggle with long-horizon planning, failing to find the optimal actions for complex tasks with longer steps. To address this, world models are used to predict the next GUI observation based on user actions, enabling more effective agent planning. However, existing world models primarily focus on generating only textual descriptions, lacking essential visual details. To fill this gap, we propose ViMo, the first visual world model designed to generate future App observations as images. For the challenge of generating text in image patches, where even minor pixel errors can distort readability, we decompose GUI generation into graphic and text content generation. We propose a novel data representation, the Symbolic Text Representation~(STR) to overlay text content with symbolic placeholders while preserving graphics. With this design, ViMo employs a STR Predictor to predict future GUIs' graphics and a GUI-text Predictor for generating the corresponding text. Moreover, we deploy ViMo to enhance agent-focused tasks by predicting the outcome of different action options. Experiments show ViMo's ability to generate visually plausible and functionally effective GUIs that enable App agents to make more informed decisions.
AppVLM: A Lightweight Vision Language Model for Online App Control
Feb 10, 2025



The utilisation of foundation models as smartphone assistants, termed app agents, is a critical research challenge. These agents aim to execute human instructions on smartphones by interpreting textual instructions and performing actions via the device's interface. While promising, current approaches face significant limitations. Methods that use large proprietary models, such as GPT-4o, are computationally expensive, while those that use smaller fine-tuned models often lack adaptability to out-of-distribution tasks. In this work, we introduce AppVLM, a lightweight Vision-Language Model (VLM). First, we fine-tune it offline on the AndroidControl dataset. Then, we refine its policy by collecting data from the AndroidWorld environment and performing further training iterations. Our results indicate that AppVLM achieves the highest action prediction accuracy in offline evaluation on the AndroidControl dataset, compared to all evaluated baselines, and matches GPT-4o in online task completion success rate in the AndroidWorld environment, while being up to ten times faster. This makes AppVLM a practical and efficient solution for real-world deployment.
Lightweight Neural App Control
Oct 23, 2024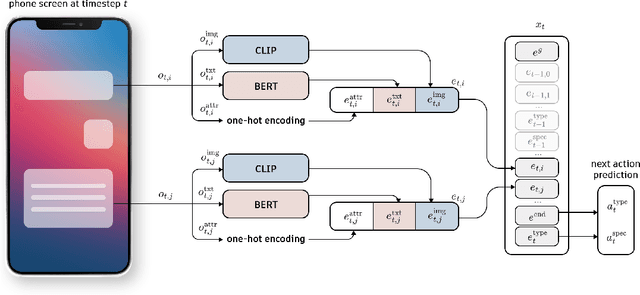
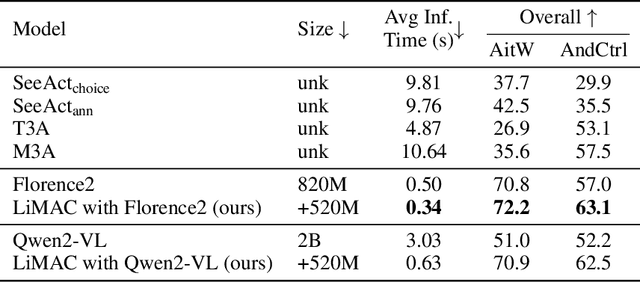
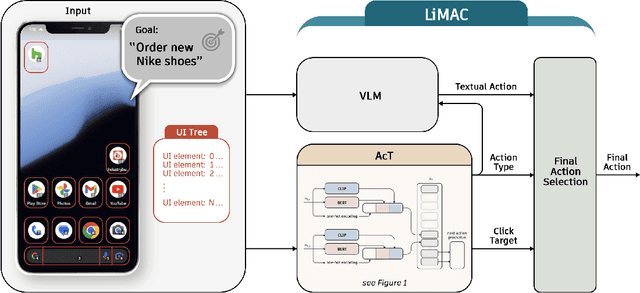
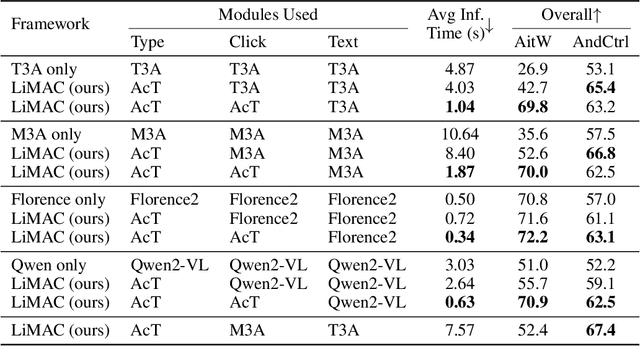
This paper introduces a novel mobile phone control architecture, termed ``app agents", for efficient interactions and controls across various Android apps. The proposed Lightweight Multi-modal App Control (LiMAC) takes as input a textual goal and a sequence of past mobile observations, such as screenshots and corresponding UI trees, to generate precise actions. To address the computational constraints inherent to smartphones, within LiMAC, we introduce a small Action Transformer (AcT) integrated with a fine-tuned vision-language model (VLM) for real-time decision-making and task execution. We evaluate LiMAC on two open-source mobile control datasets, demonstrating the superior performance of our small-form-factor approach against fine-tuned versions of open-source VLMs, such as Florence2 and Qwen2-VL. It also significantly outperforms prompt engineering baselines utilising closed-source foundation models like GPT-4o. More specifically, LiMAC increases the overall action accuracy by up to 19% compared to fine-tuned VLMs, and up to 42% compared to prompt-engineering baselines.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023



A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Scalable Multi-Agent Reinforcement Learning for Warehouse Logistics with Robotic and Human Co-Workers
Dec 22, 2022
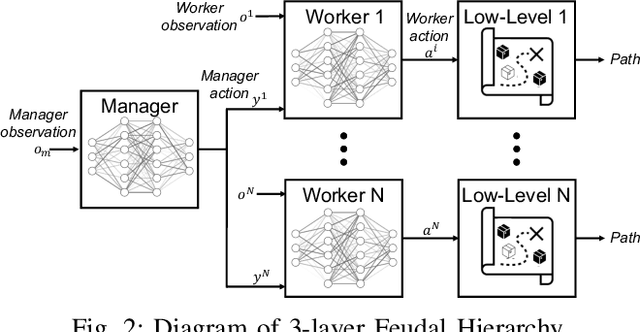
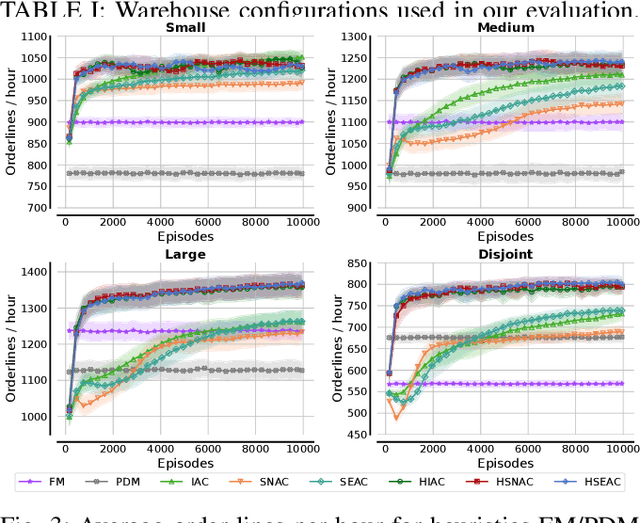
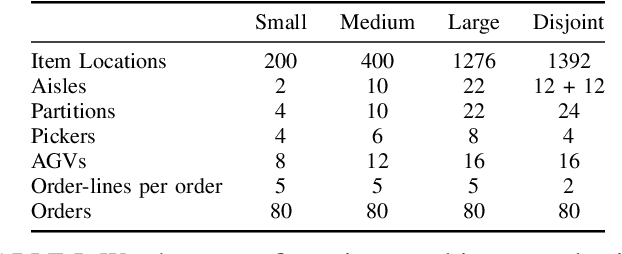
This project leverages advances in multi-agent reinforcement learning (MARL) to improve the efficiency and flexibility of order-picking systems for commercial warehouses. We envision a warehouse of the future in which dozens of mobile robots and human pickers work together to collect and deliver items within the warehouse. The fundamental problem we tackle, called the order-picking problem, is how these worker agents must coordinate their movement and actions in the warehouse to maximise performance (e.g. order throughput) under given resource constraints. Established industry methods using heuristic approaches require large engineering efforts to optimise for innately variable warehouse configurations. In contrast, the MARL framework can be flexibly applied to any warehouse configuration (e.g. size, layout, number/types of workers, item replenishment frequency) and the agents learn via a process of trial-and-error how to optimally cooperate with one another. This paper details the current status of the R&D effort initiated by Dematic and the University of Edinburgh towards a general-purpose and scalable MARL solution for the order-picking problem in realistic warehouses.
Pareto Actor-Critic for Equilibrium Selection in Multi-Agent Reinforcement Learning
Sep 28, 2022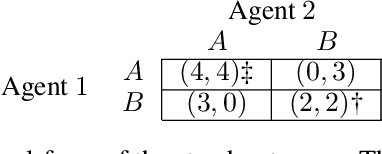
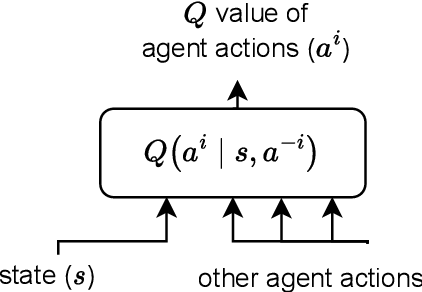
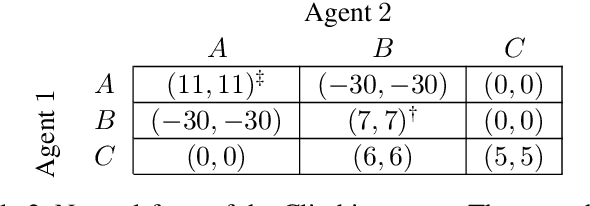
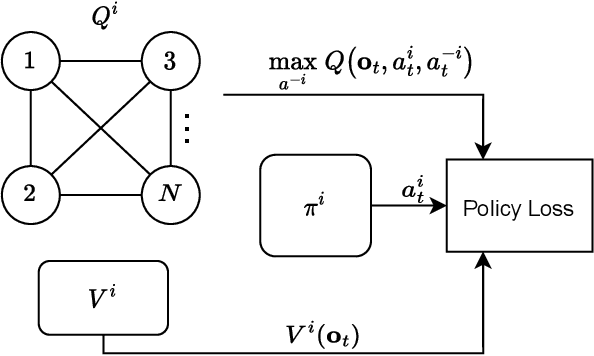
Equilibrium selection in multi-agent games refers to the problem of selecting a Pareto-optimal equilibrium. It has been shown that many state-of-the-art multi-agent reinforcement learning (MARL) algorithms are prone to converging to Pareto-dominated equilibria due to the uncertainty each agent has about the policy of the other agents during training. To address suboptimal equilibrium selection, we propose Pareto-AC (PAC), an actor-critic algorithm that utilises a simple principle of no-conflict games (a superset of cooperative games with identical rewards): each agent can assume the others will choose actions that will lead to a Pareto-optimal equilibrium. We evaluate PAC in a diverse set of multi-agent games and show that it converges to higher episodic returns compared to alternative MARL algorithms, as well as successfully converging to a Pareto-optimal equilibrium in a range of matrix games. Finally, we propose a graph neural network extension which is shown to efficiently scale in games with up to 15 agents.
Deep Reinforcement Learning for Multi-Agent Interaction
Aug 02, 2022The development of autonomous agents which can interact with other agents to accomplish a given task is a core area of research in artificial intelligence and machine learning. Towards this goal, the Autonomous Agents Research Group develops novel machine learning algorithms for autonomous systems control, with a specific focus on deep reinforcement learning and multi-agent reinforcement learning. Research problems include scalable learning of coordinated agent policies and inter-agent communication; reasoning about the behaviours, goals, and composition of other agents from limited observations; and sample-efficient learning based on intrinsic motivation, curriculum learning, causal inference, and representation learning. This article provides a broad overview of the ongoing research portfolio of the group and discusses open problems for future directions.
Scaling Multi-Agent Reinforcement Learning with Selective Parameter Sharing
Feb 15, 2021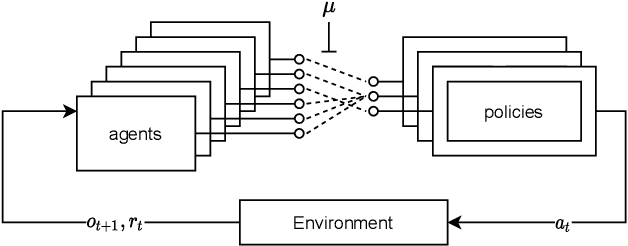
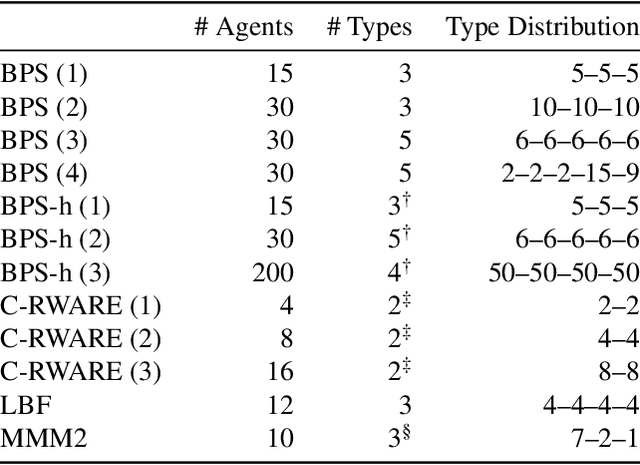
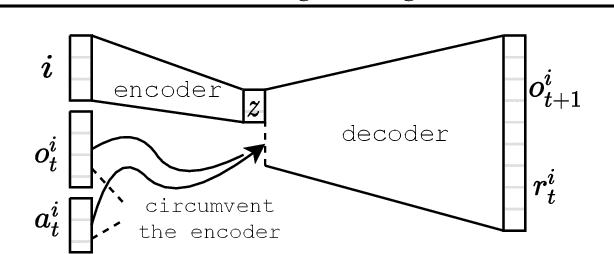
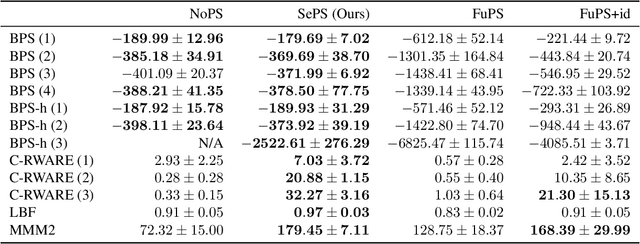
Sharing parameters in multi-agent deep reinforcement learning has played an essential role in allowing algorithms to scale to a large number of agents. Parameter sharing between agents significantly decreases the number of trainable parameters, shortening training times to tractable levels, and has been linked to more efficient learning. However, having all agents share the same parameters can also have a detrimental effect on learning. We demonstrate the impact of parameter sharing methods on training speed and converged returns, establishing that when applied indiscriminately, their effectiveness is highly dependent on the environment. Therefore, we propose a novel method to automatically identify agents which may benefit from sharing parameters by partitioning them based on their abilities and goals. Our approach combines the increased sample efficiency of parameter sharing with the representational capacity of multiple independent networks to reduce training time and increase final returns.
Opponent Modelling with Local Information Variational Autoencoders
Jun 16, 2020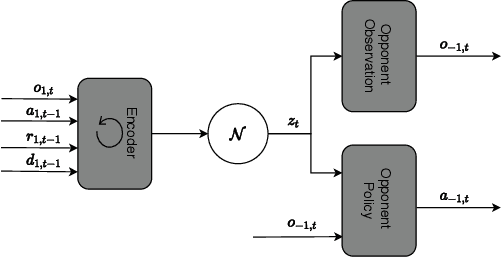
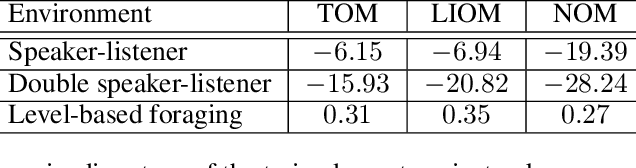
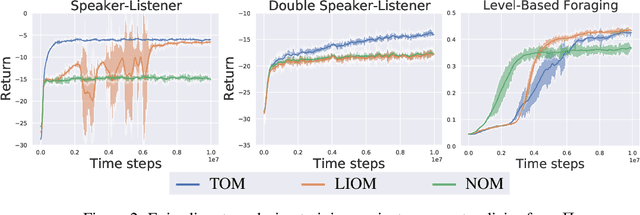
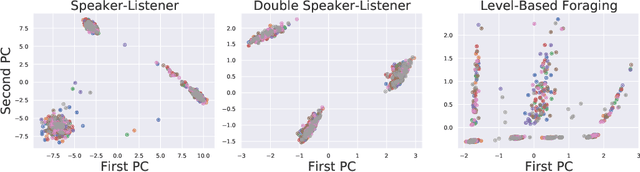
Modelling the behaviours of other agents (opponents) is essential for understanding how agents interact and making effective decisions. Existing methods for opponent modelling commonly assume knowledge of the local observations and chosen actions of the modelled opponents, which can significantly limit their applicability. We propose a new modelling technique based on variational autoencoders which uses only the local observations of the agent under control: its observed world state, chosen actions, and received rewards. The model is jointly trained with the agent's decision policy using deep reinforcement learning techniques. We provide a comprehensive evaluation and ablation study in diverse multi-agent tasks, showing that our method achieves significantly higher returns than a baseline method which does not use opponent modelling, and comparable performance to an ideal baseline which has full access to opponent information.
Comparative Evaluation of Multi-Agent Deep Reinforcement Learning Algorithms
Jun 14, 2020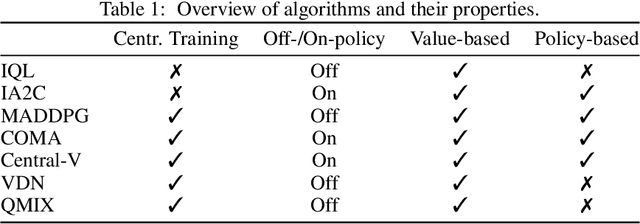
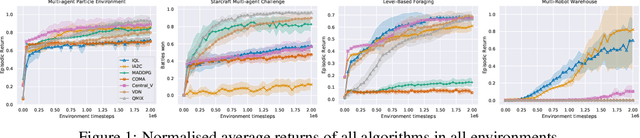
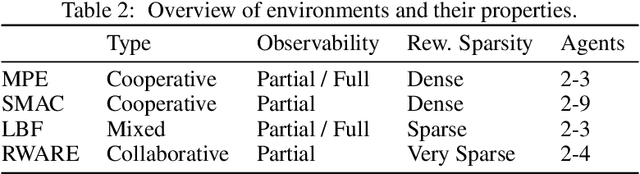
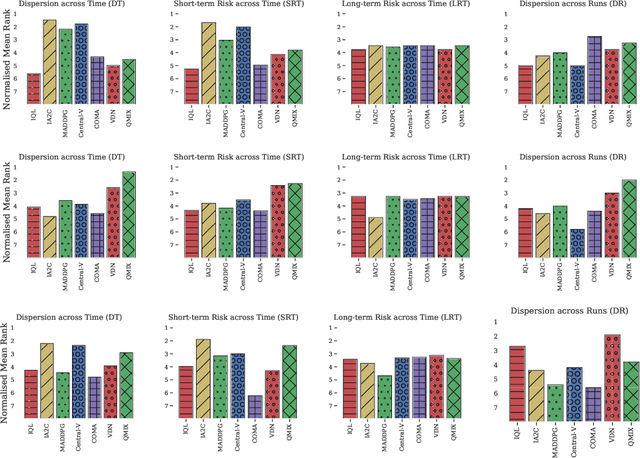
Multi-agent deep reinforcement learning (MARL) suffers from a lack of commonly-used evaluation tasks and criteria, making comparisons between approaches difficult. In this work, we evaluate and compare three different classes of MARL algorithms (independent learners, centralised training with decentralised execution, and value decomposition) in a diverse range of multi-agent learning tasks. Our results show that (1) algorithm performance depends strongly on environment properties and no algorithm learns efficiently across all learning tasks; (2) independent learners often achieve equal or better performance than more complex algorithms; (3) tested algorithms struggle to solve multi-agent tasks with sparse rewards. We report detailed empirical data, including a reliability analysis, and provide insights into the limitations of the tested algorithms.