 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMPG: MoE-based Adaptive Multi-Perspective Graph Fusion for Protein Representation Learning
Jan 15, 2026Graph Neural Networks (GNNs) have been widely adopted for Protein Representation Learning (PRL), as residue interaction networks can be naturally represented as graphs. Current GNN-based PRL methods typically rely on single-perspective graph construction strategies, which capture partial properties of residue interactions, resulting in incomplete protein representations. To address this limitation, we propose MMPG, a framework that constructs protein graphs from multiple perspectives and adaptively fuses them via Mixture of Experts (MoE) for PRL. MMPG constructs graphs from physical, chemical, and geometric perspectives to characterize different properties of residue interactions. To capture both perspective-specific features and their synergies, we develop an MoE module, which dynamically routes perspectives to specialized experts, where experts learn intrinsic features and cross-perspective interactions. We quantitatively verify that MoE automatically specializes experts in modeling distinct levels of interaction from individual representations, to pairwise inter-perspective synergies, and ultimately to a global consensus across all perspectives. Through integrating this multi-level information, MMPG produces superior protein representations and achieves advanced performance on four different downstream protein tasks.
Multi-Omics Analysis for Cancer Subtype Inference via Unrolling Graph Smoothness Priors
Aug 08, 2025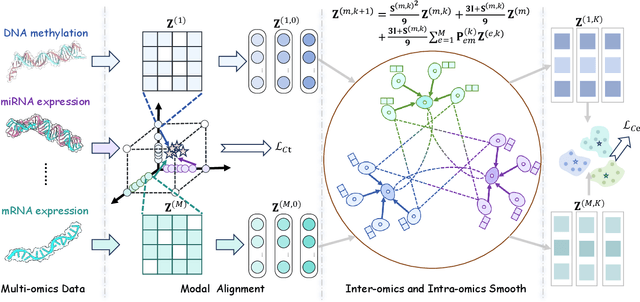
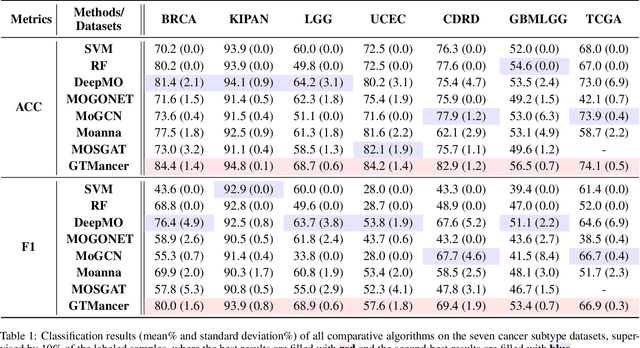
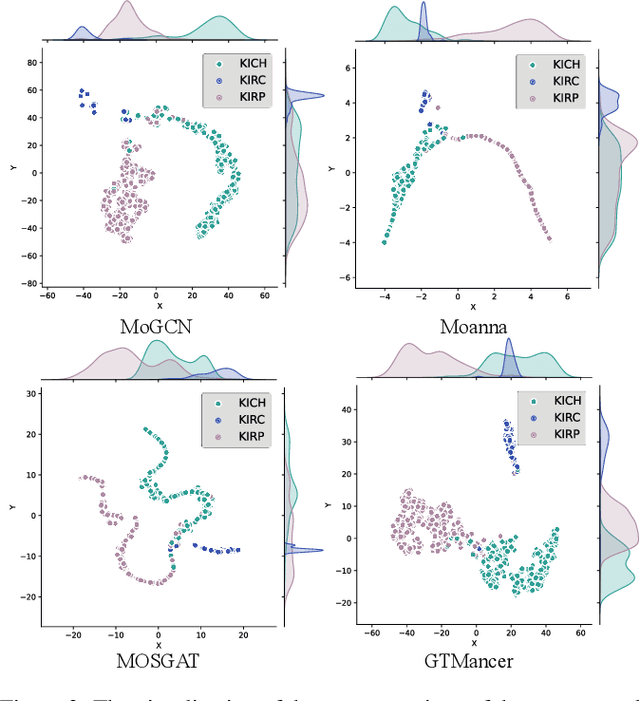
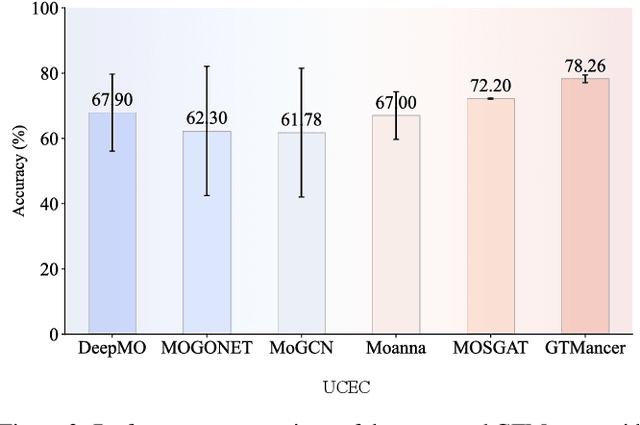
Integrating multi-omics datasets through data-driven analysis offers a comprehensive understanding of the complex biological processes underlying various diseases, particularly cancer. Graph Neural Networks (GNNs) have recently demonstrated remarkable ability to exploit relational structures in biological data, enabling advances in multi-omics integration for cancer subtype classification. Existing approaches often neglect the intricate coupling between heterogeneous omics, limiting their capacity to resolve subtle cancer subtype heterogeneity critical for precision oncology. To address these limitations, we propose a framework named Graph Transformer for Multi-omics Cancer Subtype Classification (GTMancer). This framework builds upon the GNN optimization problem and extends its application to complex multi-omics data. Specifically, our method leverages contrastive learning to embed multi-omics data into a unified semantic space. We unroll the multiplex graph optimization problem in that unified space and introduce dual sets of attention coefficients to capture structural graph priors both within and among multi-omics data. This approach enables global omics information to guide the refining of the representations of individual omics. Empirical experiments on seven real-world cancer datasets demonstrate that GTMancer outperforms existing state-of-the-art algorithms.
AgentSwift: Efficient LLM Agent Design via Value-guided Hierarchical Search
Jun 06, 2025Large language model (LLM) agents have demonstrated strong capabilities across diverse domains. However, designing high-performing agentic systems remains challenging. Existing agent search methods suffer from three major limitations: (1) an emphasis on optimizing agentic workflows while under-utilizing proven human-designed components such as memory, planning, and tool use; (2) high evaluation costs, as each newly generated agent must be fully evaluated on benchmarks; and (3) inefficient search in large search space. In this work, we introduce a comprehensive framework to address these challenges. First, We propose a hierarchical search space that jointly models agentic workflow and composable functional components, enabling richer agentic system designs. Building on this structured design space, we introduce a predictive value model that estimates agent performance given agentic system and task description, allowing for efficient, low-cost evaluation during the search process. Finally, we present a hierarchical Monte Carlo Tree Search (MCTS) strategy informed by uncertainty to guide the search. Experiments on seven benchmarks, covering embodied, math, web, tool, and game, show that our method achieves an average performance gain of 8.34\% over state-of-the-art baselines and exhibits faster search progress with steeper improvement trajectories. Code repo is available at https://github.com/Ericccc02/AgentSwift.
Harmonizing Intra-coherence and Inter-divergence in Ensemble Attacks for Adversarial Transferability
May 02, 2025The development of model ensemble attacks has significantly improved the transferability of adversarial examples, but this progress also poses severe threats to the security of deep neural networks. Existing methods, however, face two critical challenges: insufficient capture of shared gradient directions across models and a lack of adaptive weight allocation mechanisms. To address these issues, we propose a novel method Harmonized Ensemble for Adversarial Transferability (HEAT), which introduces domain generalization into adversarial example generation for the first time. HEAT consists of two key modules: Consensus Gradient Direction Synthesizer, which uses Singular Value Decomposition to synthesize shared gradient directions; and Dual-Harmony Weight Orchestrator which dynamically balances intra-domain coherence, stabilizing gradients within individual models, and inter-domain diversity, enhancing transferability across models. Experimental results demonstrate that HEAT significantly outperforms existing methods across various datasets and settings, offering a new perspective and direction for adversarial attack research.
Simplifying Graph Convolutional Networks with Redundancy-Free Neighbors
Apr 21, 2025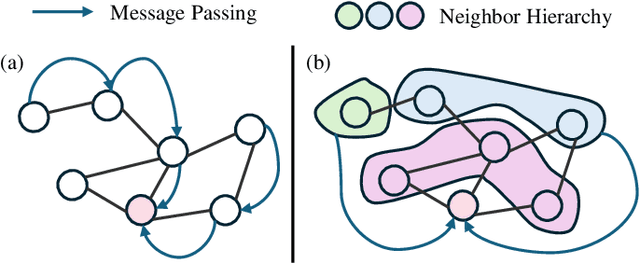
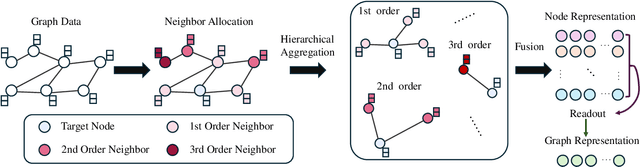
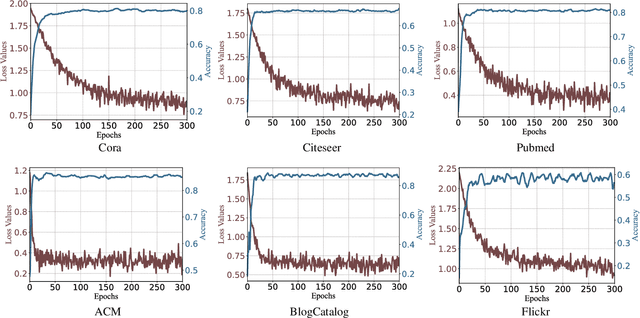
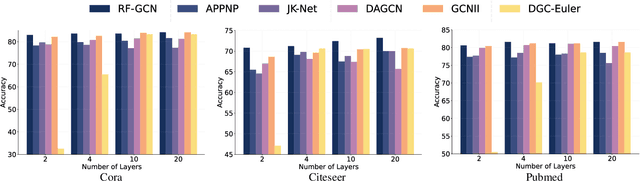
In recent years, Graph Convolutional Networks (GCNs) have gained popularity for their exceptional ability to process graph-structured data. Existing GCN-based approaches typically employ a shallow model architecture due to the over-smoothing phenomenon. Current approaches to mitigating over-smoothing primarily involve adding supplementary components to GCN architectures, such as residual connections and random edge-dropping strategies. However, these improvements toward deep GCNs have achieved only limited success. In this work, we analyze the intrinsic message passing mechanism of GCNs and identify a critical issue: messages originating from high-order neighbors must traverse through low-order neighbors to reach the target node. This repeated reliance on low-order neighbors leads to redundant information aggregation, a phenomenon we term over-aggregation. Our analysis demonstrates that over-aggregation not only introduces significant redundancy but also serves as the fundamental cause of over-smoothing in GCNs.
AppVLM: A Lightweight Vision Language Model for Online App Control
Feb 10, 2025



The utilisation of foundation models as smartphone assistants, termed app agents, is a critical research challenge. These agents aim to execute human instructions on smartphones by interpreting textual instructions and performing actions via the device's interface. While promising, current approaches face significant limitations. Methods that use large proprietary models, such as GPT-4o, are computationally expensive, while those that use smaller fine-tuned models often lack adaptability to out-of-distribution tasks. In this work, we introduce AppVLM, a lightweight Vision-Language Model (VLM). First, we fine-tune it offline on the AndroidControl dataset. Then, we refine its policy by collecting data from the AndroidWorld environment and performing further training iterations. Our results indicate that AppVLM achieves the highest action prediction accuracy in offline evaluation on the AndroidControl dataset, compared to all evaluated baselines, and matches GPT-4o in online task completion success rate in the AndroidWorld environment, while being up to ten times faster. This makes AppVLM a practical and efficient solution for real-world deployment.
OCMDP: Observation-Constrained Markov Decision Process
Nov 12, 2024In many practical applications, decision-making processes must balance the costs of acquiring information with the benefits it provides. Traditional control systems often assume full observability, an unrealistic assumption when observations are expensive. We tackle the challenge of simultaneously learning observation and control strategies in such cost-sensitive environments by introducing the Observation-Constrained Markov Decision Process (OCMDP), where the policy influences the observability of the true state. To manage the complexity arising from the combined observation and control actions, we develop an iterative, model-free deep reinforcement learning algorithm that separates the sensing and control components of the policy. This decomposition enables efficient learning in the expanded action space by focusing on when and what to observe, as well as determining optimal control actions, without requiring knowledge of the environment's dynamics. We validate our approach on a simulated diagnostic task and a realistic healthcare environment using HeartPole. Given both scenarios, the experimental results demonstrate that our model achieves a substantial reduction in observation costs on average, significantly outperforming baseline methods by a notable margin in efficiency.
SPA-Bench: A Comprehensive Benchmark for SmartPhone Agent Evaluation
Oct 19, 2024



Smartphone agents are increasingly important for helping users control devices efficiently, with (Multimodal) Large Language Model (MLLM)-based approaches emerging as key contenders. Fairly comparing these agents is essential but challenging, requiring a varied task scope, the integration of agents with different implementations, and a generalisable evaluation pipeline to assess their strengths and weaknesses. In this paper, we present SPA-Bench, a comprehensive SmartPhone Agent Benchmark designed to evaluate (M)LLM-based agents in an interactive environment that simulates real-world conditions. SPA-Bench offers three key contributions: (1) A diverse set of tasks covering system and third-party apps in both English and Chinese, focusing on features commonly used in daily routines; (2) A plug-and-play framework enabling real-time agent interaction with Android devices, integrating over ten agents with the flexibility to add more; (3) A novel evaluation pipeline that automatically assesses agent performance across multiple dimensions, encompassing seven metrics related to task completion and resource consumption. Our extensive experiments across tasks and agents reveal challenges like interpreting mobile user interfaces, action grounding, memory retention, and execution costs. We propose future research directions to ease these difficulties, moving closer to real-world smartphone agent applications.
DistRL: An Asynchronous Distributed Reinforcement Learning Framework for On-Device Control Agents
Oct 18, 2024



On-device control agents, especially on mobile devices, are responsible for operating mobile devices to fulfill users' requests, enabling seamless and intuitive interactions. Integrating Multimodal Large Language Models (MLLMs) into these agents enhances their ability to understand and execute complex commands, thereby improving user experience. However, fine-tuning MLLMs for on-device control presents significant challenges due to limited data availability and inefficient online training processes. This paper introduces DistRL, a novel framework designed to enhance the efficiency of online RL fine-tuning for mobile device control agents. DistRL employs centralized training and decentralized data acquisition to ensure efficient fine-tuning in the context of dynamic online interactions. Additionally, the framework is backed by our tailor-made RL algorithm, which effectively balances exploration with the prioritized utilization of collected data to ensure stable and robust training. Our experiments show that, on average, DistRL delivers a 3X improvement in training efficiency and enables training data collection 2.4X faster than the leading synchronous multi-machine methods. Notably, after training, DistRL achieves a 20% relative improvement in success rate compared to state-of-the-art methods on general Android tasks from an open benchmark, significantly outperforming existing approaches while maintaining the same training time. These results validate DistRL as a scalable and efficient solution, offering substantial improvements in both training efficiency and agent performance for real-world, in-the-wild device control tasks.
Masked Two-channel Decoupling Framework for Incomplete Multi-view Weak Multi-label Learning
Apr 26, 2024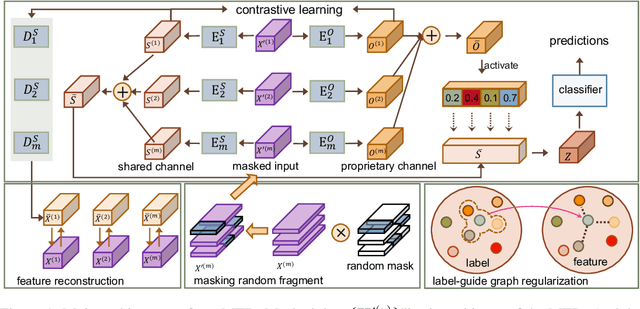
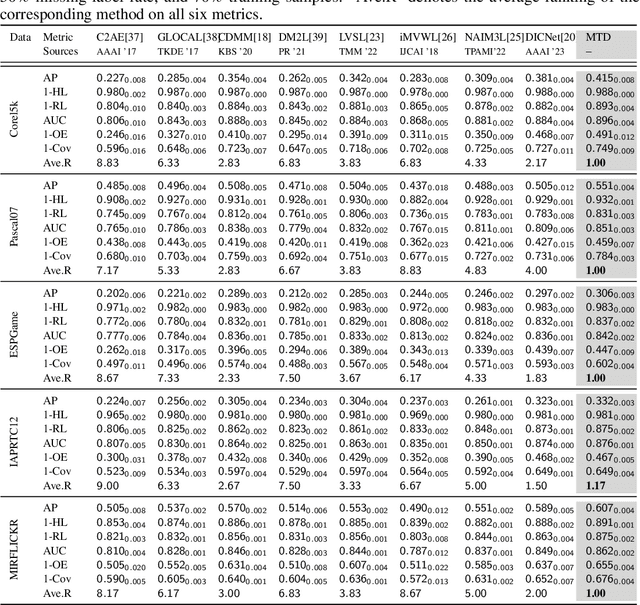
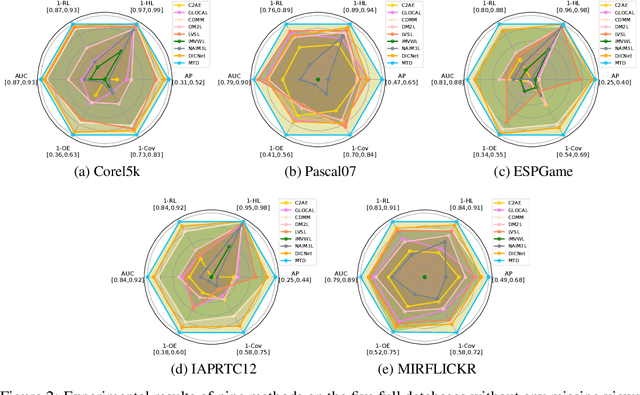
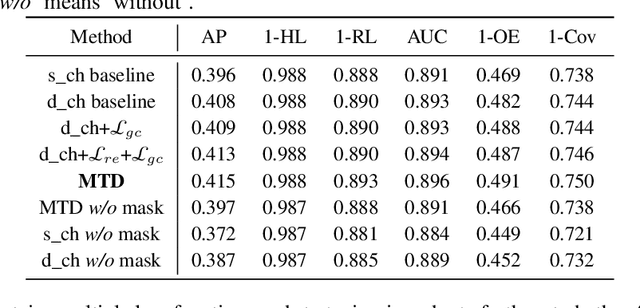
Multi-view learning has become a popular research topic in recent years, but research on the cross-application of classic multi-label classification and multi-view learning is still in its early stages. In this paper, we focus on the complex yet highly realistic task of incomplete multi-view weak multi-label learning and propose a masked two-channel decoupling framework based on deep neural networks to solve this problem. The core innovation of our method lies in decoupling the single-channel view-level representation, which is common in deep multi-view learning methods, into a shared representation and a view-proprietary representation. We also design a cross-channel contrastive loss to enhance the semantic property of the two channels. Additionally, we exploit supervised information to design a label-guided graph regularization loss, helping the extracted embedding features preserve the geometric structure among samples. Inspired by the success of masking mechanisms in image and text analysis, we develop a random fragment masking strategy for vector features to improve the learning ability of encoders. Finally, it is important to emphasize that our model is fully adaptable to arbitrary view and label absences while also performing well on the ideal full data. We have conducted sufficient and convincing experiments to confirm the effectiveness and advancement of our model.