 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrinity: A Scenario-Aware Recommendation Framework for Large-Scale Cold-Start Users
Feb 28, 2026Early-stage users in a new scenario intensify cold-start challenges, yet prior works often address only parts of the problem through model architecture. Launching a new user experience to replace an established product involves sparse behavioral signals, low-engagement cohorts, and unstable model performance. We argue that effective recommendations require the synergistic integration of feature engineering, model architecture, and stable model updating. We propose Trinity, a framework embodying this principle. Trinity extracts valuable information from existing scenarios while ensuring predictive effectiveness and accuracy in the new scenario. In this paper, we showcase Trinity applied to a billion-user Microsoft product transition. Both offline and online experiments demonstrate that our framework achieves substantial improvements in addressing the combined challenge of new users in new scenarios.
SparseEval: Efficient Evaluation of Large Language Models by Sparse Optimization
Feb 08, 2026As large language models (LLMs) continue to scale up, their performance on various downstream tasks has significantly improved. However, evaluating their capabilities has become increasingly expensive, as performing inference on a large number of benchmark samples incurs high computational costs. In this paper, we revisit the model-item performance matrix and show that it exhibits sparsity, that representative items can be selected as anchors, and that the task of efficient benchmarking can be formulated as a sparse optimization problem. Based on these insights, we propose SparseEval, a method that, for the first time, adopts gradient descent to optimize anchor weights and employs an iterative refinement strategy for anchor selection. We utilize the representation capacity of MLP to handle sparse optimization and propose the Anchor Importance Score and Candidate Importance Score to evaluate the value of each item for task-aware refinement. Extensive experiments demonstrate the low estimation error and high Kendall's~$τ$ of our method across a variety of benchmarks, showcasing its superior robustness and practicality in real-world scenarios. Code is available at {https://github.com/taolinzhang/SparseEval}.
Think Before You Move: Latent Motion Reasoning for Text-to-Motion Generation
Dec 30, 2025Current state-of-the-art paradigms predominantly treat Text-to-Motion (T2M) generation as a direct translation problem, mapping symbolic language directly to continuous poses. While effective for simple actions, this System 1 approach faces a fundamental theoretical bottleneck we identify as the Semantic-Kinematic Impedance Mismatch: the inherent difficulty of grounding semantically dense, discrete linguistic intent into kinematically dense, high-frequency motion data in a single shot. In this paper, we argue that the solution lies in an architectural shift towards Latent System 2 Reasoning. Drawing inspiration from Hierarchical Motor Control in cognitive science, we propose Latent Motion Reasoning (LMR) that reformulates generation as a two-stage Think-then-Act decision process. Central to LMR is a novel Dual-Granularity Tokenizer that disentangles motion into two distinct manifolds: a compressed, semantically rich Reasoning Latent for planning global topology, and a high-frequency Execution Latent for preserving physical fidelity. By forcing the model to autoregressively reason (plan the coarse trajectory) before it moves (instantiates the frames), we effectively bridge the ineffability gap between language and physics. We demonstrate LMR's versatility by implementing it for two representative baselines: T2M-GPT (discrete) and MotionStreamer (continuous). Extensive experiments show that LMR yields non-trivial improvements in both semantic alignment and physical plausibility, validating that the optimal substrate for motion planning is not natural language, but a learned, motion-aligned concept space. Codes and demos can be found in \hyperlink{https://chenhaoqcdyq.github.io/LMR/}{https://chenhaoqcdyq.github.io/LMR/}
HAROOD: A Benchmark for Out-of-distribution Generalization in Sensor-based Human Activity Recognition
Dec 12, 2025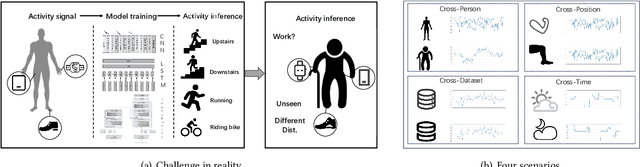



Sensor-based human activity recognition (HAR) mines activity patterns from the time-series sensory data. In realistic scenarios, variations across individuals, devices, environments, and time introduce significant distributional shifts for the same activities. Recent efforts attempt to solve this challenge by applying or adapting existing out-of-distribution (OOD) algorithms, but only in certain distribution shift scenarios (e.g., cross-device or cross-position), lacking comprehensive insights on the effectiveness of these algorithms. For instance, is OOD necessary to HAR? Which OOD algorithm performs the best? In this paper, we fill this gap by proposing HAROOD, a comprehensive benchmark for HAR in OOD settings. We define 4 OOD scenarios: cross-person, cross-position, cross-dataset, and cross-time, and build a testbed covering 6 datasets, 16 comparative methods (implemented with CNN-based and Transformer-based architectures), and two model selection protocols. Then, we conduct extensive experiments and present several findings for future research, e.g., no single method consistently outperforms others, highlighting substantial opportunity for advancement. Our codebase is highly modular and easy to extend for new datasets, algorithms, comparisons, and analysis, with the hope to facilitate the research in OOD-based HAR. Our implementation is released and can be found at https://github.com/AIFrontierLab/HAROOD.
Self-Ensemble Post Learning for Noisy Domain Generalization
Dec 11, 2025While computer vision and machine learning have made great progress, their robustness is still challenged by two key issues: data distribution shift and label noise. When domain generalization (DG) encounters noise, noisy labels further exacerbate the emergence of spurious features in deep layers, i.e. spurious feature enlargement, leading to a degradation in the performance of existing algorithms. This paper, starting from domain generalization, explores how to make existing methods rework when meeting noise. We find that the latent features inside the model have certain discriminative capabilities, and different latent features focus on different parts of the image. Based on these observations, we propose the Self-Ensemble Post Learning approach (SEPL) to diversify features which can be leveraged. Specifically, SEPL consists of two parts: feature probing training and prediction ensemble inference. It leverages intermediate feature representations within the model architecture, training multiple probing classifiers to fully exploit the capabilities of pre-trained models, while the final predictions are obtained through the integration of outputs from these diverse classification heads. Considering the presence of noisy labels, we employ semi-supervised algorithms to train probing classifiers. Given that different probing classifiers focus on different areas, we integrate their predictions using a crowdsourcing inference approach. Extensive experimental evaluations demonstrate that the proposed method not only enhances the robustness of existing methods but also exhibits significant potential for real-world applications with high flexibility.
Exploring Scale Shift in Crowd Localization under the Context of Domain Generalization
Oct 22, 2025Crowd localization plays a crucial role in visual scene understanding towards predicting each pedestrian location in a crowd, thus being applicable to various downstream tasks. However, existing approaches suffer from significant performance degradation due to discrepancies in head scale distributions (scale shift) between training and testing data, a challenge known as domain generalization (DG). This paper aims to comprehend the nature of scale shift within the context of domain generalization for crowd localization models. To this end, we address four critical questions: (i) How does scale shift influence crowd localization in a DG scenario? (ii) How can we quantify this influence? (iii) What causes this influence? (iv) How to mitigate the influence? Initially, we conduct a systematic examination of how crowd localization performance varies with different levels of scale shift. Then, we establish a benchmark, ScaleBench, and reproduce 20 advanced DG algorithms to quantify the influence. Through extensive experiments, we demonstrate the limitations of existing algorithms and underscore the importance and complexity of scale shift, a topic that remains insufficiently explored. To deepen our understanding, we provide a rigorous theoretical analysis on scale shift. Building on these insights, we further propose an effective algorithm called Causal Feature Decomposition and Anisotropic Processing (Catto) to mitigate the influence of scale shift in DG settings. Later, we also provide extensive analytical experiments, revealing four significant insights for future research. Our results emphasize the importance of this novel and applicable research direction, which we term Scale Shift Domain Generalization.
Harmonizing Intra-coherence and Inter-divergence in Ensemble Attacks for Adversarial Transferability
May 02, 2025The development of model ensemble attacks has significantly improved the transferability of adversarial examples, but this progress also poses severe threats to the security of deep neural networks. Existing methods, however, face two critical challenges: insufficient capture of shared gradient directions across models and a lack of adaptive weight allocation mechanisms. To address these issues, we propose a novel method Harmonized Ensemble for Adversarial Transferability (HEAT), which introduces domain generalization into adversarial example generation for the first time. HEAT consists of two key modules: Consensus Gradient Direction Synthesizer, which uses Singular Value Decomposition to synthesize shared gradient directions; and Dual-Harmony Weight Orchestrator which dynamically balances intra-domain coherence, stabilizing gradients within individual models, and inter-domain diversity, enhancing transferability across models. Experimental results demonstrate that HEAT significantly outperforms existing methods across various datasets and settings, offering a new perspective and direction for adversarial attack research.
FHBench: Towards Efficient and Personalized Federated Learning for Multimodal Healthcare
Apr 15, 2025



Federated Learning (FL) has emerged as an effective solution for multi-institutional collaborations without sharing patient data, offering a range of methods tailored for diverse applications. However, real-world medical datasets are often multimodal, and computational resources are limited, posing significant challenges for existing FL approaches. Recognizing these limitations, we developed the Federated Healthcare Benchmark(FHBench), a benchmark specifically designed from datasets derived from real-world healthcare applications. FHBench encompasses critical diagnostic tasks across domains such as the nervous, cardiovascular, and respiratory systems and general pathology, providing comprehensive support for multimodal healthcare evaluations and filling a significant gap in existing benchmarks. Building on FHBench, we introduced Efficient Personalized Federated Learning with Adaptive LoRA(EPFL), a personalized FL framework that demonstrates superior efficiency and effectiveness across various healthcare modalities. Our results highlight the robustness of FHBench as a benchmarking tool and the potential of EPFL as an innovative approach to advancing healthcare-focused FL, addressing key limitations of existing methods.
A Language Anchor-Guided Method for Robust Noisy Domain Generalization
Mar 21, 2025Real-world machine learning applications often struggle with two major challenges: distribution shift and label noise. Models tend to overfit by focusing on redundant and uninformative features in the training data, which makes it hard for them to generalize to the target domain. Noisy data worsens this problem by causing further overfitting to the noise, meaning that existing methods often fail to tell the difference between true, invariant features and misleading, spurious ones. To tackle these issues, we introduce Anchor Alignment and Adaptive Weighting (A3W). This new algorithm uses sample reweighting guided by natural language processing (NLP) anchors to extract more representative features. In simple terms, A3W leverages semantic representations from natural language models as a source of domain-invariant prior knowledge. Additionally, it employs a weighted loss function that adjusts each sample's contribution based on its similarity to the corresponding NLP anchor. This adjustment makes the model more robust to noisy labels. Extensive experiments on standard benchmark datasets show that A3W consistently outperforms state-of-the-art domain generalization methods, offering significant improvements in both accuracy and robustness across different datasets and noise levels.
Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application
Jul 02, 2024



Large Language Models (LLMs) have showcased exceptional capabilities in various domains, attracting significant interest from both academia and industry. Despite their impressive performance, the substantial size and computational demands of LLMs pose considerable challenges for practical deployment, particularly in environments with limited resources. The endeavor to compress language models while maintaining their accuracy has become a focal point of research. Among the various methods, knowledge distillation has emerged as an effective technique to enhance inference speed without greatly compromising performance. This paper presents a thorough survey from three aspects: method, evaluation, and application, exploring knowledge distillation techniques tailored specifically for LLMs. Specifically, we divide the methods into white-box KD and black-box KD to better illustrate their differences. Furthermore, we also explored the evaluation tasks and distillation effects between different distillation methods, and proposed directions for future research. Through in-depth understanding of the latest advancements and practical applications, this survey provides valuable resources for researchers, paving the way for sustained progress in this field.