 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDiagram: Advancing Unified Diagram Code Generation via Visual Interrogation Reward
Apr 07, 2026The paradigm of programmable diagram generation is evolving rapidly, playing a crucial role in structured visualization. However, most existing studies are confined to a narrow range of task formulations and language support, constraining their applicability to diverse diagram types. In this work, we propose OmniDiagram, a unified framework that incorporates diverse diagram code languages and task definitions. To address the challenge of aligning code logic with visual fidelity in Reinforcement Learning (RL), we introduce a novel visual feedback strategy named Visual Interrogation Verifies All (\textsc{Viva}). Unlike brittle syntax-based rules or pixel-level matching, \textsc{Viva} rewards the visual structure of rendered diagrams through a generative approach. Specifically, \textsc{Viva} actively generates targeted visual inquiries to scrutinize diagram visual fidelity and provides fine-grained feedback for optimization. This mechanism facilitates a self-evolving training process, effectively obviating the need for manually annotated ground truth code. Furthermore, we construct M3$^2$Diagram, the first large-scale diagram code generation dataset, containing over 196k high-quality instances. Experimental results confirm that the combination of SFT and our \textsc{Viva}-based RL allows OmniDiagram to establish a new state-of-the-art (SOTA) across diagram code generation benchmarks.
FSMC-Pose: Frequency and Spatial Fusion with Multiscale Self-calibration for Cattle Mounting Pose Estimation
Mar 17, 2026Mounting posture is an important visual indicator of estrus in dairy cattle. However, achieving reliable mounting pose estimation in real-world environments remains challenging due to cluttered backgrounds and frequent inter-animal occlusion. We present FSMC-Pose, a top-down framework that integrates a lightweight frequency-spatial fusion backbone, CattleMountNet, and a multiscale self-calibration head, SC2Head. Specifically, we design two algorithmic components for CattleMountNet: the Spatial Frequency Enhancement Block (SFEBlock) and the Receptive Aggregation Block (RABlock). SFEBlock separates cattle from cluttered backgrounds, while RABlock captures multiscale contextual information. The Spatial-Channel Self-Calibration Head (SC2Head) attends to spatial and channel dependencies and introduces a self-calibration branch to mitigate structural misalignment under inter-animal overlap. We construct a mounting dataset, MOUNT-Cattle, covering 1176 mounting instances, which follows the COCO format and supports drop-in training across pose estimation models. Using a comprehensive dataset that combines MOUNT-Cattle with the public NWAFU-Cattle dataset, FSMC-Pose achieves higher accuracy than strong baselines, with markedly lower computational and parameter costs, while maintaining real-time inference on commodity GPUs. Extensive experiments and qualitative analyses show that FSMC-Pose effectively captures and estimates cattle mounting pose in complex and cluttered environments. Dataset and code are available at https://github.com/elianafang/FSMC-Pose.
Beyond Scaling: Assessing Strategic Reasoning and Rapid Decision-Making Capability of LLMs in Zero-sum Environments
Mar 10, 2026Large Language Models (LLMs) have achieved strong performance on static reasoning benchmarks, yet their effectiveness as interactive agents operating in adversarial, time-sensitive environments remains poorly understood. Existing evaluations largely treat reasoning as a single-shot capability, overlooking the challenges of opponent-aware decision-making, temporal constraints, and execution under pressure. This paper introduces Strategic Tactical Agent Reasoning (STAR) Benchmark, a multi-agent evaluation framework that assesses LLMs through 1v1 zero-sum competitive interactions, framing reasoning as an iterative, adaptive decision-making process. STAR supports both turn-based and real-time settings, enabling controlled analysis of long-horizon strategic planning and fast-paced tactical execution within a unified environment. Built on a modular architecture with a standardized API and fully implemented execution engine, STAR facilitates reproducible evaluation and flexible task customization. To move beyond binary win-loss outcomes, we introduce a Strategic Evaluation Suite that assesses not only competitive success but also the quality of strategic behavior, such as execution efficiency and outcome stability. Extensive pairwise evaluations reveal a pronounced strategy-execution gap: while reasoning-intensive models dominate turn-based settings, their inference latency often leads to inferior performance in real-time scenarios, where faster instruction-tuned models prevail. These results show that strategic intelligence in interactive environments depends not only on reasoning depth, but also on the ability to translate plans into timely actions, positioning STAR as a principled benchmark for studying this trade-off in competitive, dynamic settings.
FlattenGPT: Depth Compression for Transformer with Layer Flattening
Feb 09, 2026Recent works have indicated redundancy across transformer blocks, prompting the research of depth compression to prune less crucial blocks. However, current ways of entire-block pruning suffer from risks of discarding meaningful cues learned in those blocks, leading to substantial performance degradation. As another line of model compression, channel pruning can better preserve performance, while it cannot reduce model depth and is challenged by inconsistent pruning ratios for individual layers. To pursue better model compression and acceleration, this paper proposes \textbf{FlattenGPT}, a novel way to detect and reduce depth-wise redundancies. By flatting two adjacent blocks into one, it compresses the network depth, meanwhile enables more effective parameter redundancy detection and removal. FlattenGPT allows to preserve the knowledge learned in all blocks, and remains consistent with the original transformer architecture. Extensive experiments demonstrate that FlattenGPT enhances model efficiency with a decent trade-off to performance. It outperforms existing pruning methods in both zero-shot accuracies and WikiText-2 perplexity across various model types and parameter sizes. On LLaMA-2/3 and Qwen-1.5 models, FlattenGPT retains 90-96\% of zero-shot performance with a compression ratio of 20\%. It also outperforms other pruning methods in accelerating LLM inference, making it promising for enhancing the efficiency of transformers.
Pruning as a Cooperative Game: Surrogate-Assisted Layer Contribution Estimation for Large Language Models
Feb 08, 2026While large language models (LLMs) demonstrate impressive performance across various tasks, their deployment in real-world scenarios is still constrained by high computational demands. Layer-wise pruning, a commonly employed strategy to mitigate inference costs, can partially address this challenge. However, existing approaches generally depend on static heuristic rules and fail to account for the interdependencies among layers, thereby limiting the effectiveness of the pruning process. To this end, this paper proposes a game-theoretic framework that formulates layer pruning as a cooperative game in which each layer acts as a player and model performance serves as the utility. As computing exact Shapley values is computationally infeasible for large language models (LLMs), we propose using a lightweight surrogate network to estimate layer-wise marginal contributions. This network can predict LLM performance for arbitrary layer combinations at a low computational cost. Additionally, we employ stratified Monte Carlo mask sampling to further reduce the cost of Sharpley value estimation. This approach captures inter-layer dependencies and dynamically identifies critical layers for pruning. Extensive experiments demonstrate the consistent superiority of our method in terms of perplexity and zero-shot accuracy, achieving more efficient and effective layer-wise pruning for large language models.
Focus-Scan-Refine: From Human Visual Perception to Efficient Visual Token Pruning
Feb 05, 2026Vision-language models (VLMs) often generate massive visual tokens that greatly increase inference latency and memory footprint; while training-free token pruning offers a practical remedy, existing methods still struggle to balance local evidence and global context under aggressive compression. We propose Focus-Scan-Refine (FSR), a human-inspired, plug-and-play pruning framework that mimics how humans answer visual questions: focus on key evidence, then scan globally if needed, and refine the scanned context by aggregating relevant details. FSR first focuses on key evidence by combining visual importance with instruction relevance, avoiding the bias toward visually salient but query-irrelevant regions. It then scans for complementary context conditioned on the focused set, selecting tokens that are most different from the focused evidence. Finally, FSR refines the scanned context by aggregating nearby informative tokens into the scan anchors via similarity-based assignment and score-weighted merging, without increasing the token budget. Extensive experiments across multiple VLM backbones and vision-language benchmarks show that FSR consistently improves the accuracy-efficiency trade-off over existing state-of-the-art pruning methods. The source codes can be found at https://github.com/ILOT-code/FSR
Resource-Efficient Reinforcement for Reasoning Large Language Models via Dynamic One-Shot Policy Refinement
Jan 31, 2026Large language models (LLMs) have exhibited remarkable performance on complex reasoning tasks, with reinforcement learning under verifiable rewards (RLVR) emerging as a principled framework for aligning model behavior with reasoning chains. Despite its promise, RLVR remains prohibitively resource-intensive, requiring extensive reward signals and incurring substantial rollout costs during training. In this work, we revisit the fundamental question of data and compute efficiency in RLVR. We first establish a theoretical lower bound on the sample complexity required to unlock reasoning capabilities, and empirically validate that strong performance can be achieved with a surprisingly small number of training instances. To tackle the computational burden, we propose Dynamic One-Shot Policy Refinement (DoPR), an uncertainty-aware RL strategy that dynamically selects a single informative training sample per batch for policy updates, guided by reward volatility and exploration-driven acquisition. DoPR reduces rollout overhead by nearly an order of magnitude while preserving competitive reasoning accuracy, offering a scalable and resource-efficient solution for LLM post-training. This approach offers a practical path toward more efficient and accessible RL-based training for reasoning-intensive LLM applications.
ONRW: Optimizing inversion noise for high-quality and robust watermark
Jan 24, 2026Watermarking methods have always been effective means of protecting intellectual property, yet they face significant challenges. Although existing deep learning-based watermarking systems can hide watermarks in images with minimal impact on image quality, they often lack robustness when encountering image corruptions during transmission, which undermines their practical application value. To this end, we propose a high-quality and robust watermark framework based on the diffusion model. Our method first converts the clean image into inversion noise through a null-text optimization process, and after optimizing the inversion noise in the latent space, it produces a high-quality watermarked image through an iterative denoising process of the diffusion model. The iterative denoising process serves as a powerful purification mechanism, ensuring both the visual quality of the watermarked image and enhancing the robustness of the watermark against various corruptions. To prevent the optimizing of inversion noise from distorting the original semantics of the image, we specifically introduced self-attention constraints and pseudo-mask strategies. Extensive experimental results demonstrate the superior performance of our method against various image corruptions. In particular, our method outperforms the stable signature method by an average of 10\% across 12 different image transformations on COCO datasets. Our codes are available at https://github.com/920927/ONRW.
On Signal Peak Power Constraint of Over-the-Air Federated Learning
Dec 29, 2025Federated learning (FL) has been considered a promising privacy preserving distributed edge learning framework. Over-the-air computation (AirComp) technique leveraging analog transmission enables the aggregation of local updates directly over-the-air by exploiting the superposition properties of wireless multiple-access channel, thereby drastically reducing the communication bottleneck issues of FL compared with digital transmission schemes. This work points out that existing AirComp-FL overlooks a key practical constraint, the instantaneous peak-power constraints imposed by the non-linearity of radiofrequency power amplifiers. We present and analyze the effect of the classic method to deal with this issue, amplitude clipping combined with filtering. We investigate the effect of instantaneous peak-power constraints in AirComp-FL for both single-carrier and multi-carrier orthogonal frequency-division multiplexing (OFDM) systems. We highlight the specificity of AirComp-FL: the samples depend on the gradient value distribution, leading to a higher peak-to-average power ratio (PAPR) than that observed for uniformly distributed signals. Simulation results demonstrate that, in practical settings, the instantaneous transmit power regularly exceeds the power-amplifier limit; however, by applying clipping and filtering, the FL performance can be degraded. The degradation becomes pronounced especially in multi-carrier OFDM systems due to the in-band distortions caused by clipping and filtering.
HAROOD: A Benchmark for Out-of-distribution Generalization in Sensor-based Human Activity Recognition
Dec 12, 2025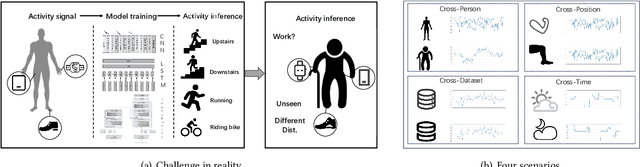



Sensor-based human activity recognition (HAR) mines activity patterns from the time-series sensory data. In realistic scenarios, variations across individuals, devices, environments, and time introduce significant distributional shifts for the same activities. Recent efforts attempt to solve this challenge by applying or adapting existing out-of-distribution (OOD) algorithms, but only in certain distribution shift scenarios (e.g., cross-device or cross-position), lacking comprehensive insights on the effectiveness of these algorithms. For instance, is OOD necessary to HAR? Which OOD algorithm performs the best? In this paper, we fill this gap by proposing HAROOD, a comprehensive benchmark for HAR in OOD settings. We define 4 OOD scenarios: cross-person, cross-position, cross-dataset, and cross-time, and build a testbed covering 6 datasets, 16 comparative methods (implemented with CNN-based and Transformer-based architectures), and two model selection protocols. Then, we conduct extensive experiments and present several findings for future research, e.g., no single method consistently outperforms others, highlighting substantial opportunity for advancement. Our codebase is highly modular and easy to extend for new datasets, algorithms, comparisons, and analysis, with the hope to facilitate the research in OOD-based HAR. Our implementation is released and can be found at https://github.com/AIFrontierLab/HAROOD.