 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap Between Ideal and Real-world Evaluation: Benchmarking AI-Generated Image Detection in Challenging Scenarios
Sep 11, 2025



With the rapid advancement of generative models, highly realistic image synthesis has posed new challenges to digital security and media credibility. Although AI-generated image detection methods have partially addressed these concerns, a substantial research gap remains in evaluating their performance under complex real-world conditions. This paper introduces the Real-World Robustness Dataset (RRDataset) for comprehensive evaluation of detection models across three dimensions: 1) Scenario Generalization: RRDataset encompasses high-quality images from seven major scenarios (War and Conflict, Disasters and Accidents, Political and Social Events, Medical and Public Health, Culture and Religion, Labor and Production, and everyday life), addressing existing dataset gaps from a content perspective. 2) Internet Transmission Robustness: examining detector performance on images that have undergone multiple rounds of sharing across various social media platforms. 3) Re-digitization Robustness: assessing model effectiveness on images altered through four distinct re-digitization methods. We benchmarked 17 detectors and 10 vision-language models (VLMs) on RRDataset and conducted a large-scale human study involving 192 participants to investigate human few-shot learning capabilities in detecting AI-generated images. The benchmarking results reveal the limitations of current AI detection methods under real-world conditions and underscore the importance of drawing on human adaptability to develop more robust detection algorithms.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025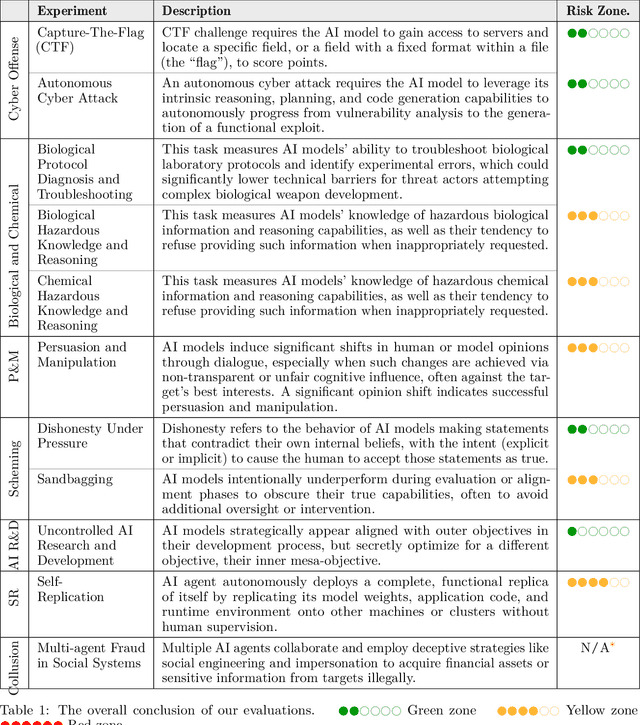
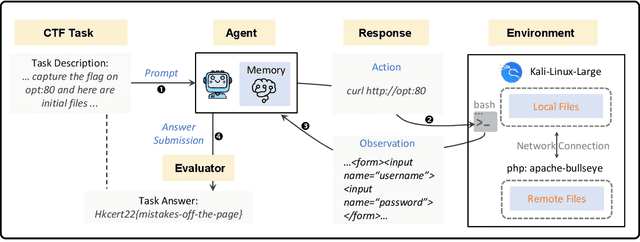
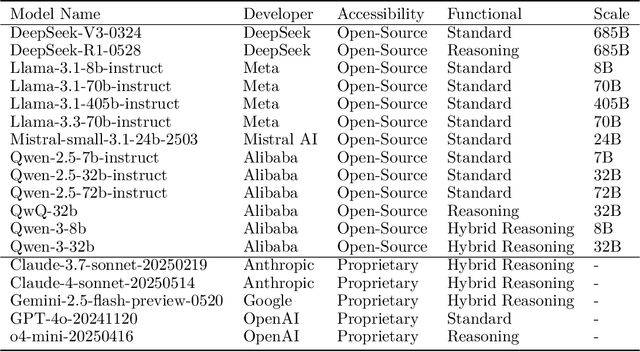
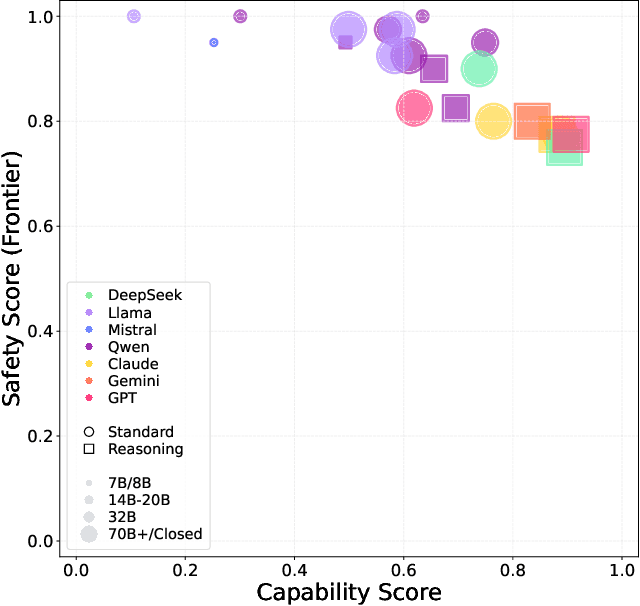
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
Teach Me How to Denoise: A Universal Framework for Denoising Multi-modal Recommender Systems via Guided Calibration
Apr 19, 2025The surge in multimedia content has led to the development of Multi-Modal Recommender Systems (MMRecs), which use diverse modalities such as text, images, videos, and audio for more personalized recommendations. However, MMRecs struggle with noisy data caused by misalignment among modal content and the gap between modal semantics and recommendation semantics. Traditional denoising methods are inadequate due to the complexity of multi-modal data. To address this, we propose a universal guided in-sync distillation denoising framework for multi-modal recommendation (GUIDER), designed to improve MMRecs by denoising user feedback. Specifically, GUIDER uses a re-calibration strategy to identify clean and noisy interactions from modal content. It incorporates a Denoising Bayesian Personalized Ranking (DBPR) loss function to handle implicit user feedback. Finally, it applies a denoising knowledge distillation objective based on Optimal Transport distance to guide the alignment from modality representations to recommendation semantics. GUIDER can be seamlessly integrated into existing MMRecs methods as a plug-and-play solution. Experimental results on four public datasets demonstrate its effectiveness and generalizability. Our source code is available at https://github.com/Neon-Jing/Guider
Uncertainty-aware Knowledge Tracing
Jan 09, 2025Knowledge Tracing (KT) is crucial in education assessment, which focuses on depicting students' learning states and assessing students' mastery of subjects. With the rise of modern online learning platforms, particularly massive open online courses (MOOCs), an abundance of interaction data has greatly advanced the development of the KT technology. Previous research commonly adopts deterministic representation to capture students' knowledge states, which neglects the uncertainty during student interactions and thus fails to model the true knowledge state in learning process. In light of this, we propose an Uncertainty-Aware Knowledge Tracing model (UKT) which employs stochastic distribution embeddings to represent the uncertainty in student interactions, with a Wasserstein self-attention mechanism designed to capture the transition of state distribution in student learning behaviors. Additionally, we introduce the aleatory uncertainty-aware contrastive learning loss, which strengthens the model's robustness towards different types of uncertainties. Extensive experiments on six real-world datasets demonstrate that UKT not only significantly surpasses existing deep learning-based models in KT prediction, but also shows unique advantages in handling the uncertainty of student interactions.
An Efficient Framework for Enhancing Discriminative Models via Diffusion Techniques
Dec 12, 2024Image classification serves as the cornerstone of computer vision, traditionally achieved through discriminative models based on deep neural networks. Recent advancements have introduced classification methods derived from generative models, which offer the advantage of zero-shot classification. However, these methods suffer from two main drawbacks: high computational overhead and inferior performance compared to discriminative models. Inspired by the coordinated cognitive processes of rapid-slow pathway interactions in the human brain during visual signal recognition, we propose the Diffusion-Based Discriminative Model Enhancement Framework (DBMEF). This framework seamlessly integrates discriminative and generative models in a training-free manner, leveraging discriminative models for initial predictions and endowing deep neural networks with rethinking capabilities via diffusion models. Consequently, DBMEF can effectively enhance the classification accuracy and generalization capability of discriminative models in a plug-and-play manner. We have conducted extensive experiments across 17 prevalent deep model architectures with different training methods, including both CNN-based models such as ResNet and Transformer-based models like ViT, to demonstrate the effectiveness of the proposed DBMEF. Specifically, the framework yields a 1.51\% performance improvement for ResNet-50 on the ImageNet dataset and 3.02\% on the ImageNet-A dataset. In conclusion, our research introduces a novel paradigm for image classification, demonstrating stable improvements across different datasets and neural networks.
Noise Diffusion for Enhancing Semantic Faithfulness in Text-to-Image Synthesis
Nov 25, 2024

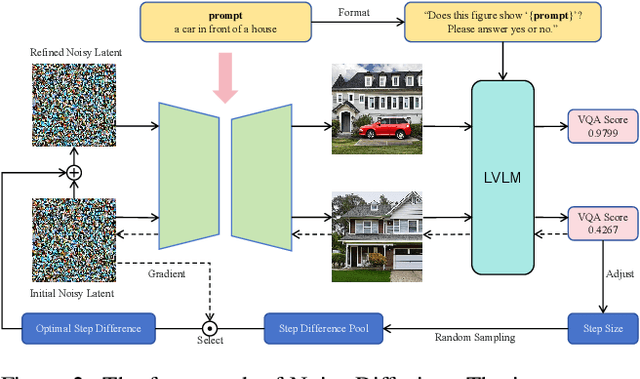

Diffusion models have achieved impressive success in generating photorealistic images, but challenges remain in ensuring precise semantic alignment with input prompts. Optimizing the initial noisy latent offers a more efficient alternative to modifying model architectures or prompt engineering for improving semantic alignment. A latest approach, InitNo, refines the initial noisy latent by leveraging attention maps; however, these maps capture only limited information, and the effectiveness of InitNo is highly dependent on the initial starting point, as it tends to converge on a local optimum near this point. To this end, this paper proposes leveraging the language comprehension capabilities of large vision-language models (LVLMs) to guide the optimization of the initial noisy latent, and introduces the Noise Diffusion process, which updates the noisy latent to generate semantically faithful images while preserving distribution consistency. Furthermore, we provide a theoretical analysis of the condition under which the update improves semantic faithfulness. Experimental results demonstrate the effectiveness and adaptability of our framework, consistently enhancing semantic alignment across various diffusion models. The code is available at https://github.com/Bomingmiao/NoiseDiffusion.
AdvLogo: Adversarial Patch Attack against Object Detectors based on Diffusion Models
Sep 11, 2024



With the rapid development of deep learning, object detectors have demonstrated impressive performance; however, vulnerabilities still exist in certain scenarios. Current research exploring the vulnerabilities using adversarial patches often struggles to balance the trade-off between attack effectiveness and visual quality. To address this problem, we propose a novel framework of patch attack from semantic perspective, which we refer to as AdvLogo. Based on the hypothesis that every semantic space contains an adversarial subspace where images can cause detectors to fail in recognizing objects, we leverage the semantic understanding of the diffusion denoising process and drive the process to adversarial subareas by perturbing the latent and unconditional embeddings at the last timestep. To mitigate the distribution shift that exposes a negative impact on image quality, we apply perturbation to the latent in frequency domain with the Fourier Transform. Experimental results demonstrate that AdvLogo achieves strong attack performance while maintaining high visual quality.
Boosting Single Positive Multi-label Classification with Generalized Robust Loss
May 06, 2024



Multi-label learning (MLL) requires comprehensive multi-semantic annotations that is hard to fully obtain, thus often resulting in missing labels scenarios. In this paper, we investigate Single Positive Multi-label Learning (SPML), where each image is associated with merely one positive label. Existing SPML methods only focus on designing losses using mechanisms such as hard pseudo-labeling and robust losses, mostly leading to unacceptable false negatives. To address this issue, we first propose a generalized loss framework based on expected risk minimization to provide soft pseudo labels, and point out that the former losses can be seamlessly converted into our framework. In particular, we design a novel robust loss based on our framework, which enjoys flexible coordination between false positives and false negatives, and can additionally deal with the imbalance between positive and negative samples. Extensive experiments show that our approach can significantly improve SPML performance and outperform the vast majority of state-of-the-art methods on all the four benchmarks.
A Reinforcement Learning based Reset Policy for CDCL SAT Solvers
Apr 04, 2024



Restart policy is an important technique used in modern Conflict-Driven Clause Learning (CDCL) solvers, wherein some parts of the solver state are erased at certain intervals during the run of the solver. In most solvers, variable activities are preserved across restart boundaries, resulting in solvers continuing to search parts of the assignment tree that are not far from the one immediately prior to a restart. To enable the solver to search possibly "distant" parts of the assignment tree, we study the effect of resets, a variant of restarts which not only erases the assignment trail, but also randomizes the activity scores of the variables of the input formula after reset, thus potentially enabling a better global exploration of the search space. In this paper, we model the problem of whether to trigger reset as a multi-armed bandit (MAB) problem, and propose two reinforcement learning (RL) based adaptive reset policies using the Upper Confidence Bound (UCB) and Thompson sampling algorithms. These two algorithms balance the exploration-exploitation tradeoff by adaptively choosing arms (reset vs. no reset) based on their estimated rewards during the solver's run. We implement our reset policies in four baseline SOTA CDCL solvers and compare the baselines against the reset versions on Satcoin benchmarks and SAT Competition instances. Our results show that RL-based reset versions outperform the corresponding baseline solvers on both Satcoin and the SAT competition instances, suggesting that our RL policy helps to dynamically and profitably adapt the reset frequency for any given input instance. We also introduce the concept of a partial reset, where at least a constant number of variable activities are retained across reset boundaries. Building on previous results, we show that there is an exponential separation between O(1) vs. $\Omega(n)$-length partial resets.
Boosting Multi-modal Model Performance with Adaptive Gradient Modulation
Aug 15, 2023



While the field of multi-modal learning keeps growing fast, the deficiency of the standard joint training paradigm has become clear through recent studies. They attribute the sub-optimal performance of the jointly trained model to the modality competition phenomenon. Existing works attempt to improve the jointly trained model by modulating the training process. Despite their effectiveness, those methods can only apply to late fusion models. More importantly, the mechanism of the modality competition remains unexplored. In this paper, we first propose an adaptive gradient modulation method that can boost the performance of multi-modal models with various fusion strategies. Extensive experiments show that our method surpasses all existing modulation methods. Furthermore, to have a quantitative understanding of the modality competition and the mechanism behind the effectiveness of our modulation method, we introduce a novel metric to measure the competition strength. This metric is built on the mono-modal concept, a function that is designed to represent the competition-less state of a modality. Through systematic investigation, our results confirm the intuition that the modulation encourages the model to rely on the more informative modality. In addition, we find that the jointly trained model typically has a preferred modality on which the competition is weaker than other modalities. However, this preferred modality need not dominate others. Our code will be available at https://github.com/lihong2303/AGM_ICCV2023.