 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVivid-VR: Distilling Concepts from Text-to-Video Diffusion Transformer for Photorealistic Video Restoration
Aug 20, 2025



We present Vivid-VR, a DiT-based generative video restoration method built upon an advanced T2V foundation model, where ControlNet is leveraged to control the generation process, ensuring content consistency. However, conventional fine-tuning of such controllable pipelines frequently suffers from distribution drift due to limitations in imperfect multimodal alignment, resulting in compromised texture realism and temporal coherence. To tackle this challenge, we propose a concept distillation training strategy that utilizes the pretrained T2V model to synthesize training samples with embedded textual concepts, thereby distilling its conceptual understanding to preserve texture and temporal quality. To enhance generation controllability, we redesign the control architecture with two key components: 1) a control feature projector that filters degradation artifacts from input video latents to minimize their propagation through the generation pipeline, and 2) a new ControlNet connector employing a dual-branch design. This connector synergistically combines MLP-based feature mapping with cross-attention mechanism for dynamic control feature retrieval, enabling both content preservation and adaptive control signal modulation. Extensive experiments show that Vivid-VR performs favorably against existing approaches on both synthetic and real-world benchmarks, as well as AIGC videos, achieving impressive texture realism, visual vividness, and temporal consistency. The codes and checkpoints are publicly available at https://github.com/csbhr/Vivid-VR.
MFDNet: Towards Real-time Image Denoising On Mobile Devices
Nov 09, 2022



Deep convolutional neural networks have achieved great progress in image denoising tasks. However, their complicated architectures and heavy computational cost hinder their deployments on a mobile device. Some recent efforts in designing lightweight denoising networks focus on reducing either FLOPs (floating-point operations) or the number of parameters. However, these metrics are not directly correlated with the on-device latency. By performing extensive analysis and experiments, we identify the network architectures that can fully utilize powerful neural processing units (NPUs) and thus enjoy both low latency and excellent denoising performance. To this end, we propose a mobile-friendly denoising network, namely MFDNet. The experiments show that MFDNet achieves state-of-the-art performance on real-world denoising benchmarks SIDD and DND under real-time latency on mobile devices. The code and pre-trained models will be released.
SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image Enhancement
Jul 18, 2022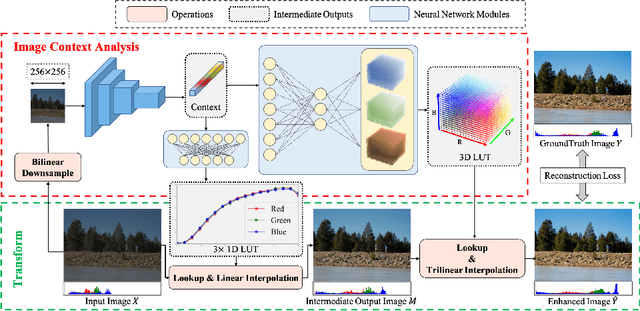
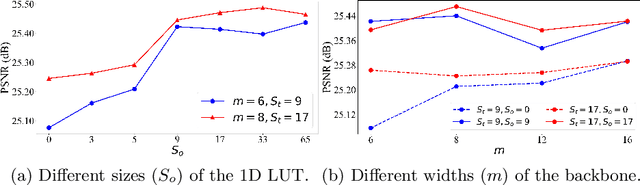
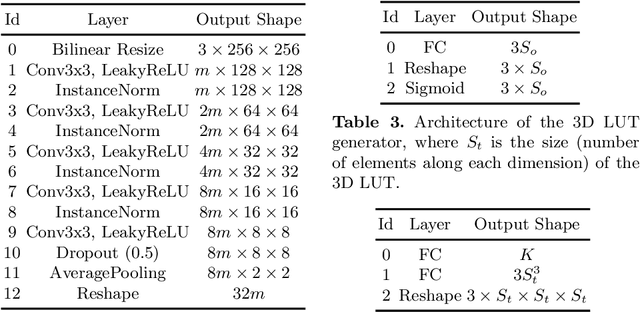
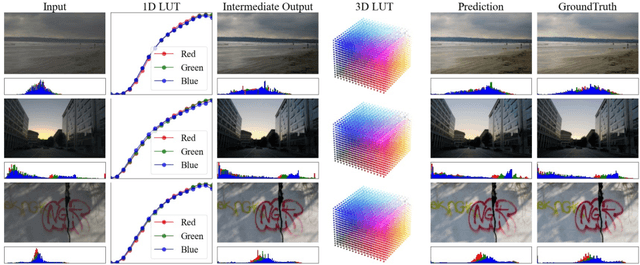
Image-adaptive lookup tables (LUTs) have achieved great success in real-time image enhancement tasks due to their high efficiency for modeling color transforms. However, they embed the complete transform, including the color component-independent and the component-correlated parts, into only a single type of LUTs, either 1D or 3D, in a coupled manner. This scheme raises a dilemma of improving model expressiveness or efficiency due to two factors. On the one hand, the 1D LUTs provide high computational efficiency but lack the critical capability of color components interaction. On the other, the 3D LUTs present enhanced component-correlated transform capability but suffer from heavy memory footprint, high training difficulty, and limited cell utilization. Inspired by the conventional divide-and-conquer practice in the image signal processor, we present SepLUT (separable image-adaptive lookup table) to tackle the above limitations. Specifically, we separate a single color transform into a cascade of component-independent and component-correlated sub-transforms instantiated as 1D and 3D LUTs, respectively. In this way, the capabilities of two sub-transforms can facilitate each other, where the 3D LUT complements the ability to mix up color components, and the 1D LUT redistributes the input colors to increase the cell utilization of the 3D LUT and thus enable the use of a more lightweight 3D LUT. Experiments demonstrate that the proposed method presents enhanced performance on photo retouching benchmark datasets than the current state-of-the-art and achieves real-time processing on both GPUs and CPUs.
AdaInt: Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement
Apr 29, 2022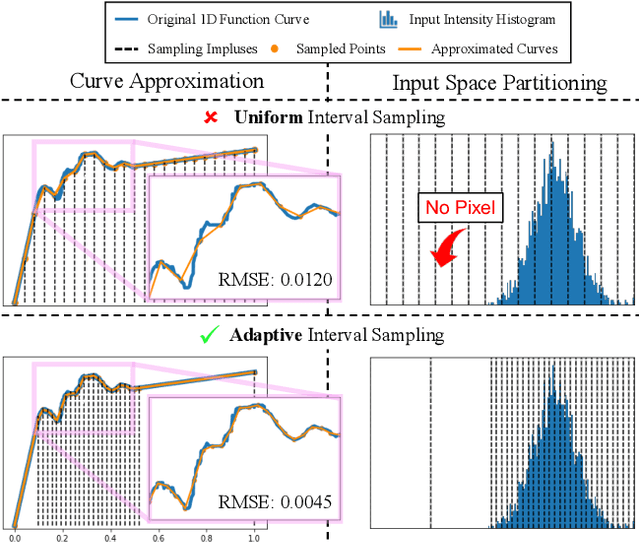

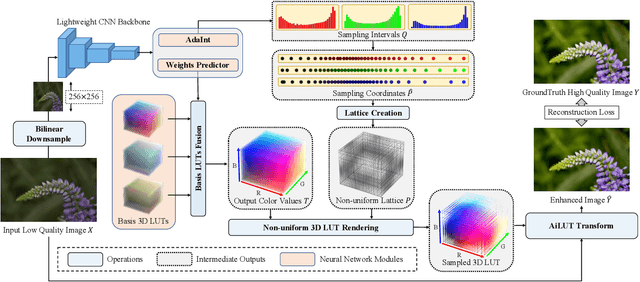
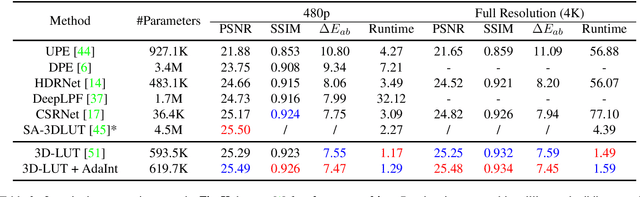
The 3D Lookup Table (3D LUT) is a highly-efficient tool for real-time image enhancement tasks, which models a non-linear 3D color transform by sparsely sampling it into a discretized 3D lattice. Previous works have made efforts to learn image-adaptive output color values of LUTs for flexible enhancement but neglect the importance of sampling strategy. They adopt a sub-optimal uniform sampling point allocation, limiting the expressiveness of the learned LUTs since the (tri-)linear interpolation between uniform sampling points in the LUT transform might fail to model local non-linearities of the color transform. Focusing on this problem, we present AdaInt (Adaptive Intervals Learning), a novel mechanism to achieve a more flexible sampling point allocation by adaptively learning the non-uniform sampling intervals in the 3D color space. In this way, a 3D LUT can increase its capability by conducting dense sampling in color ranges requiring highly non-linear transforms and sparse sampling for near-linear transforms. The proposed AdaInt could be implemented as a compact and efficient plug-and-play module for a 3D LUT-based method. To enable the end-to-end learning of AdaInt, we design a novel differentiable operator called AiLUT-Transform (Adaptive Interval LUT Transform) to locate input colors in the non-uniform 3D LUT and provide gradients to the sampling intervals. Experiments demonstrate that methods equipped with AdaInt can achieve state-of-the-art performance on two public benchmark datasets with a negligible overhead increase. Our source code is available at https://github.com/ImCharlesY/AdaInt.
Interventional Multi-Instance Learning with Deconfounded Instance-Level Prediction
Apr 22, 2022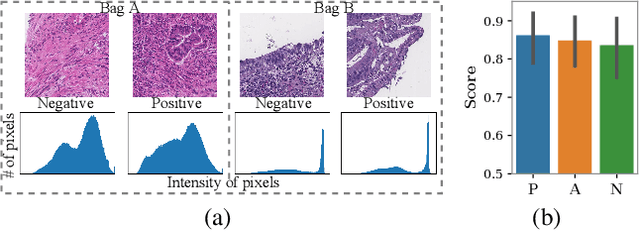
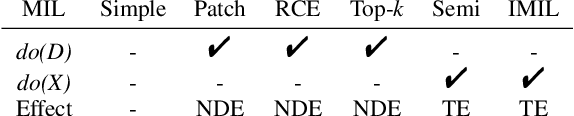
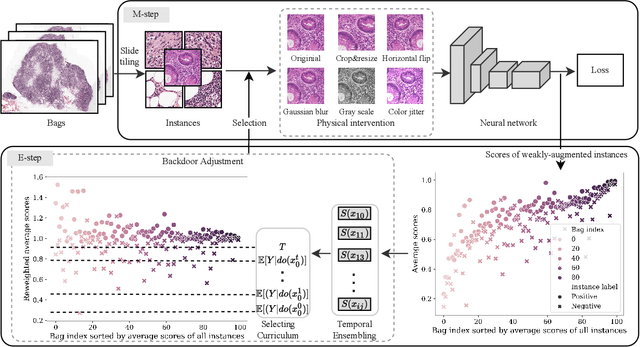
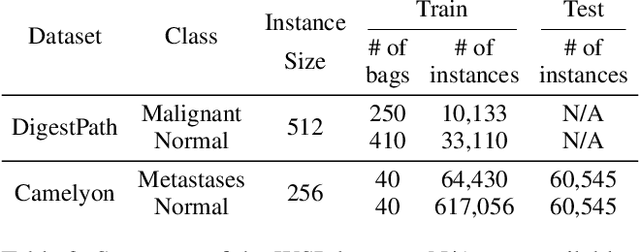
When applying multi-instance learning (MIL) to make predictions for bags of instances, the prediction accuracy of an instance often depends on not only the instance itself but also its context in the corresponding bag. From the viewpoint of causal inference, such bag contextual prior works as a confounder and may result in model robustness and interpretability issues. Focusing on this problem, we propose a novel interventional multi-instance learning (IMIL) framework to achieve deconfounded instance-level prediction. Unlike traditional likelihood-based strategies, we design an Expectation-Maximization (EM) algorithm based on causal intervention, providing a robust instance selection in the training phase and suppressing the bias caused by the bag contextual prior. Experiments on pathological image analysis demonstrate that our IMIL method substantially reduces false positives and outperforms state-of-the-art MIL methods.
Self Supervised Lesion Recognition For Breast Ultrasound Diagnosis
Apr 18, 2022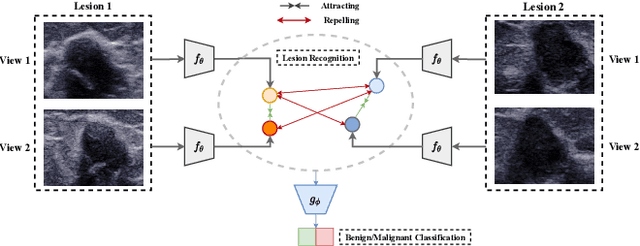


Previous deep learning based Computer Aided Diagnosis (CAD) system treats multiple views of the same lesion as independent images. Since an ultrasound image only describes a partial 2D projection of a 3D lesion, such paradigm ignores the semantic relationship between different views of a lesion, which is inconsistent with the traditional diagnosis where sonographers analyze a lesion from at least two views. In this paper, we propose a multi-task framework that complements Benign/Malignant classification task with lesion recognition (LR) which helps leveraging relationship among multiple views of a single lesion to learn a complete representation of the lesion. To be specific, LR task employs contrastive learning to encourage representation that pulls multiple views of the same lesion and repels those of different lesions. The task therefore facilitates a representation that is not only invariant to the view change of the lesion, but also capturing fine-grained features to distinguish between different lesions. Experiments show that the proposed multi-task framework boosts the performance of Benign/Malignant classification as two sub-tasks complement each other and enhance the learned representation of ultrasound images.
Decoupled Gradient Harmonized Detector for Partial Annotation: Application to Signet Ring Cell Detection
Apr 09, 2020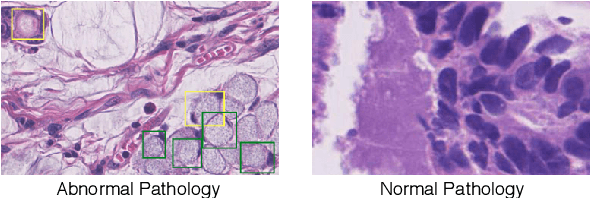
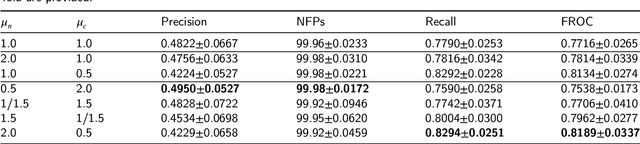
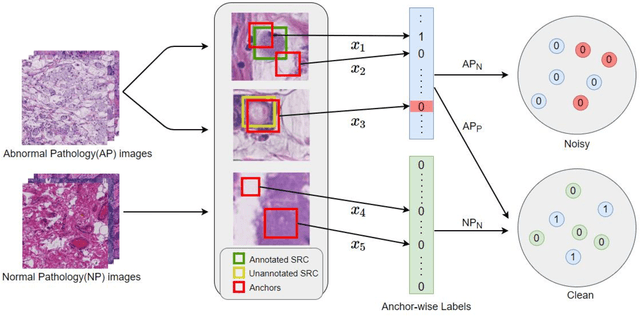
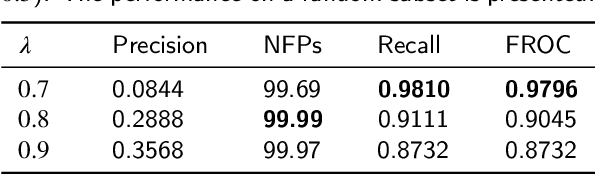
Early diagnosis of signet ring cell carcinoma dramatically improves the survival rate of patients. Due to lack of public dataset and expert-level annotations, automatic detection on signet ring cell (SRC) has not been thoroughly investigated. In MICCAI DigestPath2019 challenge, apart from foreground (SRC region)-background (normal tissue area) class imbalance, SRCs are partially annotated due to costly medical image annotation, which introduces extra label noise. To address the issues simultaneously, we propose Decoupled Gradient Harmonizing Mechanism (DGHM) and embed it into classification loss, denoted as DGHM-C loss. Specifically, besides positive (SRCs) and negative (normal tissues) examples, we further decouple noisy examples from clean examples and harmonize the corresponding gradient distributions in classification respectively. Without whistles and bells, we achieved the 2nd place in the challenge. Ablation studies and controlled label missing rate experiments demonstrate that DGHM-C loss can bring substantial improvement in partially annotated object detection.
Reinventing 2D Convolutions for 3D Medical Images
Nov 24, 2019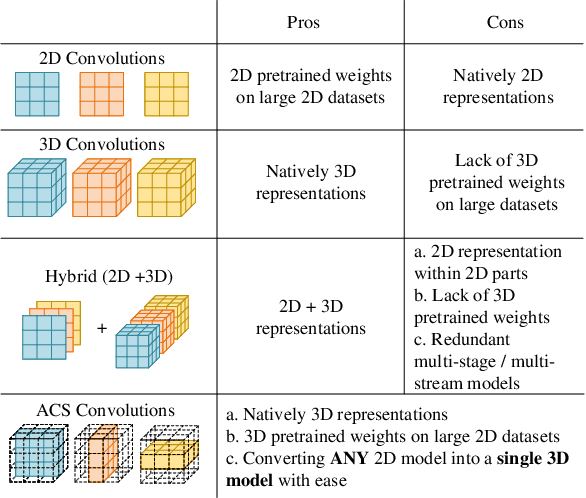
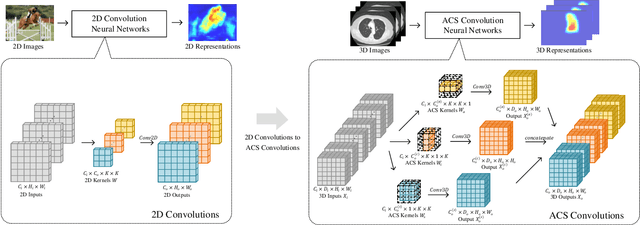

There has been considerable debate over 2D and 3D representation learning on 3D medical images. 2D approaches could benefit from large-scale 2D pretraining, whereas they are generally weak in capturing large 3D contexts. 3D approaches are natively strong in 3D contexts, however few publicly available 3D medical dataset is large and diverse enough for universal 3D pretraining. Even for hybrid (2D + 3D) approaches, the intrinsic disadvantages within the 2D / 3D parts still exist. In this study, we bridge the gap between 2D and 3D convolutions by reinventing the 2D convolutions. We propose ACS (axial-coronal-sagittal) convolutions to perform natively 3D representation learning, while utilizing the pretrained weights from 2D counterparts. In ACS convolutions, 2D convolution kernels are split by channel into three parts, and convoluted separately on the three views (axial, coronal and sagittal) of 3D representations. Theoretically, ANY 2D CNN (ResNet, DenseNet, or DeepLab) is able to be converted into a 3D ACS CNN, with pretrained weights of same parameter sizes. Extensive experiments on proof-of-concept dataset and several medical benchmarks validate the consistent superiority of the pretrained ACS CNNs, over the 2D / 3D CNN counterparts with / without pretraining. Even without pretraining, the ACS convolution can be used as a plug-and-play replacement of standard 3D convolution, with smaller model size.