 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-Consistent Calibration for Cache-Accelerated Diffusion Models
May 24, 2026Diffusion Transformers require repeated denoiser evaluations during iterative sampling, making inference computationally expensive. Cache-based acceleration reduces this cost by reusing intermediate representations across denoising steps, but can introduce representation deviations and degrade generation quality. In this paper, we analyze these deviations and show that effective calibration should consider both the direct mismatch caused by reuse and the subsequent trajectory shift induced by earlier corrections. To address this challenge, we propose Trajectory-Consistent Calibration (TCC), a training-free method that calibrates cached representations toward their full-computation counterparts. Specifically, rather than estimating all calibration priors from a single uncorrected cache trajectory, TCC uses an offline iterative procedure so that each prior accounts for the trajectory shift induced by preceding calibrations. Experiments on PixArt-alpha and DiT-XL/2 show that TCC consistently improves FID across representative cache-based acceleration methods while preserving their underlying reuse policies. Notably, in a representative PixArt-alpha cache-acceleration setting based on FORA, TCC reduces FID from 29.83 to 27.35, slightly surpassing the full-computation baseline.
Rethinking Supervision Granularity: Segment-Level Learning for LLM-Based Theorem Proving
May 12, 2026Automated theorem proving with large language models in Lean 4 is commonly approached through either step-level tactic prediction with tree search or whole-proof generation. These two paradigms represent opposite granularities for constructing supervised training data: the former provides dense local signals but may fragment coherent proof processes, while the latter preserves global structure but requires complex end-to-end generation. In this paper, we revisit supervision granularity as a training set construction problem over proof trajectories and propose segment-level supervision, a training data construction strategy that extracts locally coherent proof segments for training policy models. We further reuse the same strategy at inference time to trigger short rollouts for existing step-level models. When trained with segment-level supervision on STP, LeanWorkbook, and NuminaMath-LEAN, the resulting policy models achieve proof success rates of 64.84%, 60.90%, and 66.31% on miniF2F, respectively, consistently outperforming both step-level and whole-proof baselines. Goal-aware rollout further improves existing step-level provers while reducing inference costs. It increases the proof success rate of BFS-Prover-V2-7B from 68.77% to 70.74% and that of InternLM2.5-StepProver from 59.59% to 60.33%, showing that appropriate supervision granularity better aligns model learning with proof structure and search. Code and models are available at https://github.com/NJUDeepEngine/SEG-ATP.
Pointer-CAD: Unifying B-Rep and Command Sequences via Pointer-based Edges & Faces Selection
Mar 04, 2026Constructing computer-aided design (CAD) models is labor-intensive but essential for engineering and manufacturing. Recent advances in Large Language Models (LLMs) have inspired the LLM-based CAD generation by representing CAD as command sequences. But these methods struggle in practical scenarios because command sequence representation does not support entity selection (e.g. faces or edges), limiting its ability to support complex editing operations such as chamfer or fillet. Further, the discretization of a continuous variable during sketch and extrude operations may result in topological errors. To address these limitations, we present Pointer-CAD, a novel LLM-based CAD generation framework that leverages a pointer-based command sequence representation to explicitly incorporate the geometric information of B-rep models into sequential modeling. In particular, Pointer-CAD decomposes CAD model generation into steps, conditioning the generation of each subsequent step on both the textual description and the B-rep generated from previous steps. Whenever an operation requires the selection of a specific geometric entity, the LLM predicts a Pointer that selects the most feature-consistent candidate from the available set. Such a selection operation also reduces the quantization error in the command sequence-based representation. To support the training of Pointer-CAD, we develop a data annotation pipeline that produces expert-level natural language descriptions and apply it to build a dataset of approximately 575K CAD models. Extensive experimental results demonstrate that Pointer-CAD effectively supports the generation of complex geometric structures and reduces segmentation error to an extremely low level, achieving a significant improvement over prior command sequence methods, thereby significantly mitigating the topological inaccuracies introduced by quantization error.
LLM-based Automated Theorem Proving Hinges on Scalable Synthetic Data Generation
May 17, 2025Recent advancements in large language models (LLMs) have sparked considerable interest in automated theorem proving and a prominent line of research integrates stepwise LLM-based provers into tree search. In this paper, we introduce a novel proof-state exploration approach for training data synthesis, designed to produce diverse tactics across a wide range of intermediate proof states, thereby facilitating effective one-shot fine-tuning of LLM as the policy model. We also propose an adaptive beam size strategy, which effectively takes advantage of our data synthesis method and achieves a trade-off between exploration and exploitation during tree search. Evaluations on the MiniF2F and ProofNet benchmarks demonstrate that our method outperforms strong baselines under the stringent Pass@1 metric, attaining an average pass rate of $60.74\%$ on MiniF2F and $21.18\%$ on ProofNet. These results underscore the impact of large-scale synthetic data in advancing automated theorem proving.
FUSION: Fully Integration of Vision-Language Representations for Deep Cross-Modal Understanding
Apr 14, 2025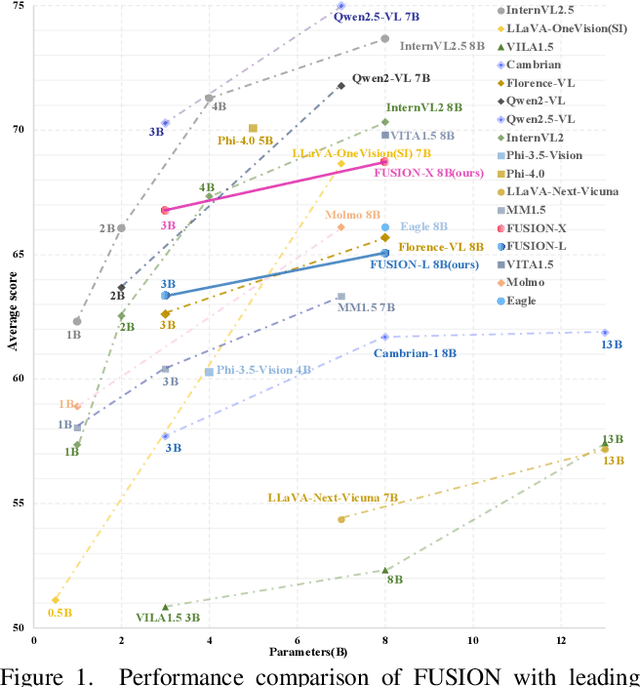
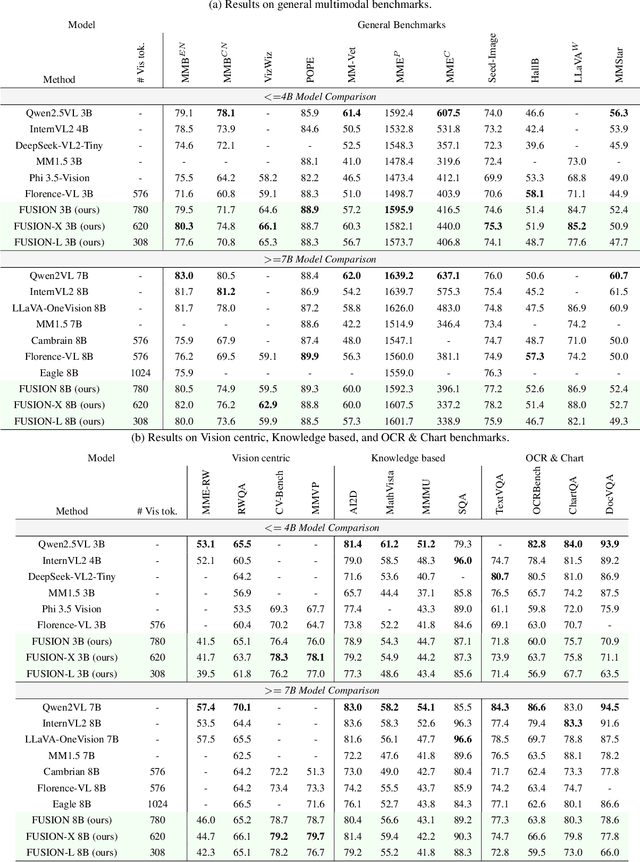
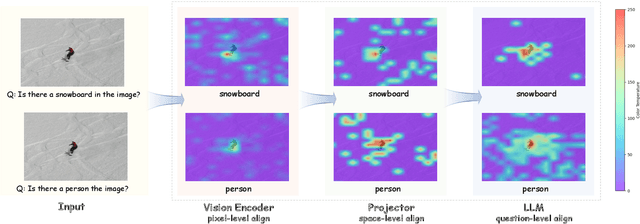
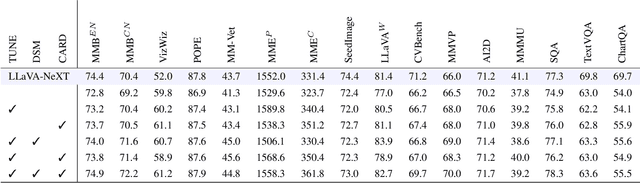
We introduce FUSION, a family of multimodal large language models (MLLMs) with a fully vision-language alignment and integration paradigm. Unlike existing methods that primarily rely on late-stage modality interaction during LLM decoding, our approach achieves deep, dynamic integration throughout the entire processing pipeline. To this end, we propose Text-Guided Unified Vision Encoding, incorporating textual information in vision encoding to achieve pixel-level integration. We further design Context-Aware Recursive Alignment Decoding that recursively aggregates visual features conditioned on textual context during decoding, enabling fine-grained, question-level semantic integration. To guide feature mapping and mitigate modality discrepancies, we develop Dual-Supervised Semantic Mapping Loss. Additionally, we construct a Synthesized Language-Driven Question-Answer (QA) dataset through a new data synthesis method, prioritizing high-quality QA pairs to optimize text-guided feature integration. Building on these foundations, we train FUSION at two scales-3B, 8B-and demonstrate that our full-modality integration approach significantly outperforms existing methods with only 630 vision tokens. Notably, FUSION 3B surpasses Cambrian-1 8B and Florence-VL 8B on most benchmarks. FUSION 3B continues to outperform Cambrian-1 8B even when limited to 300 vision tokens. Our ablation studies show that FUSION outperforms LLaVA-NeXT on over half of the benchmarks under same configuration without dynamic resolution, highlighting the effectiveness of our approach. We release our code, model weights, and dataset. https://github.com/starriver030515/FUSION
FastMap: Fast Queries Initialization Based Vectorized HD Map Reconstruction Framework
Mar 07, 2025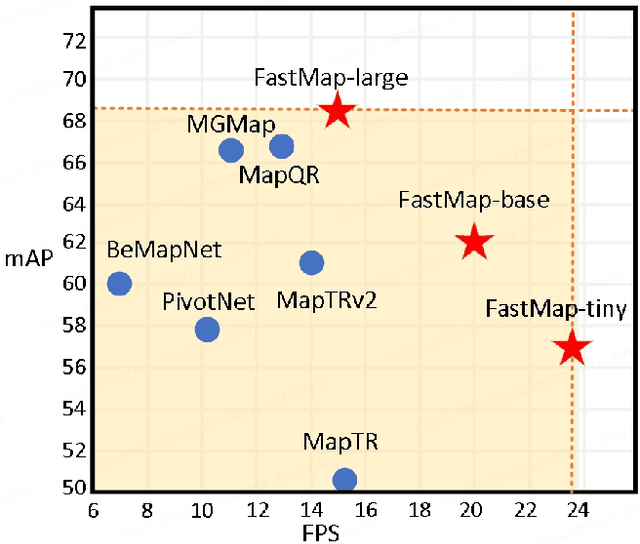
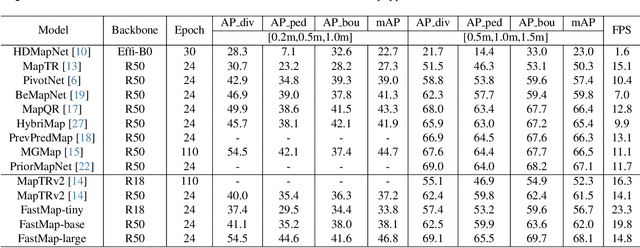
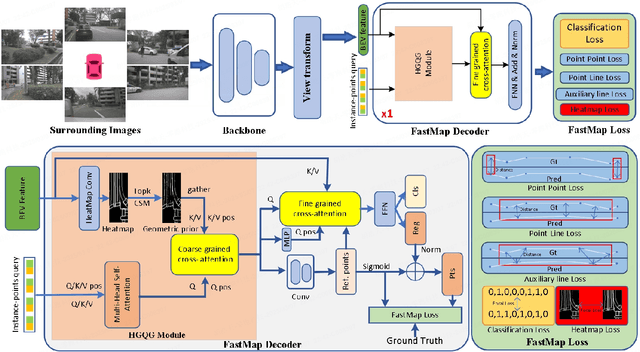
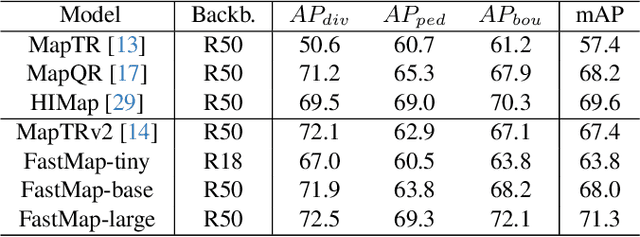
Reconstruction of high-definition maps is a crucial task in perceiving the autonomous driving environment, as its accuracy directly impacts the reliability of prediction and planning capabilities in downstream modules. Current vectorized map reconstruction methods based on the DETR framework encounter limitations due to the redundancy in the decoder structure, necessitating the stacking of six decoder layers to maintain performance, which significantly hampers computational efficiency. To tackle this issue, we introduce FastMap, an innovative framework designed to reduce decoder redundancy in existing approaches. FastMap optimizes the decoder architecture by employing a single-layer, two-stage transformer that achieves multilevel representation capabilities. Our framework eliminates the conventional practice of randomly initializing queries and instead incorporates a heatmap-guided query generation module during the decoding phase, which effectively maps image features into structured query vectors using learnable positional encoding. Additionally, we propose a geometry-constrained point-to-line loss mechanism for FastMap, which adeptly addresses the challenge of distinguishing highly homogeneous features that often arise in traditional point-to-point loss computations. Extensive experiments demonstrate that FastMap achieves state-of-the-art performance in both nuScenes and Argoverse2 datasets, with its decoder operating 3.2 faster than the baseline. Code and more demos are available at https://github.com/hht1996ok/FastMap.
CAD-MLLM: Unifying Multimodality-Conditioned CAD Generation With MLLM
Nov 07, 2024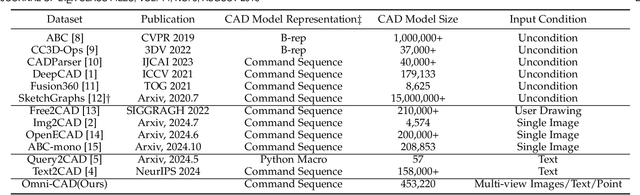
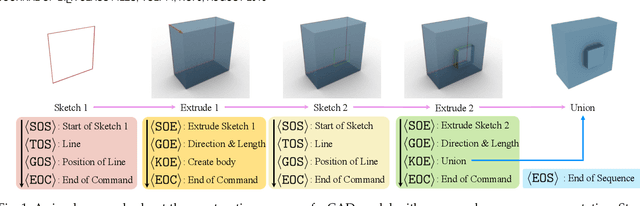
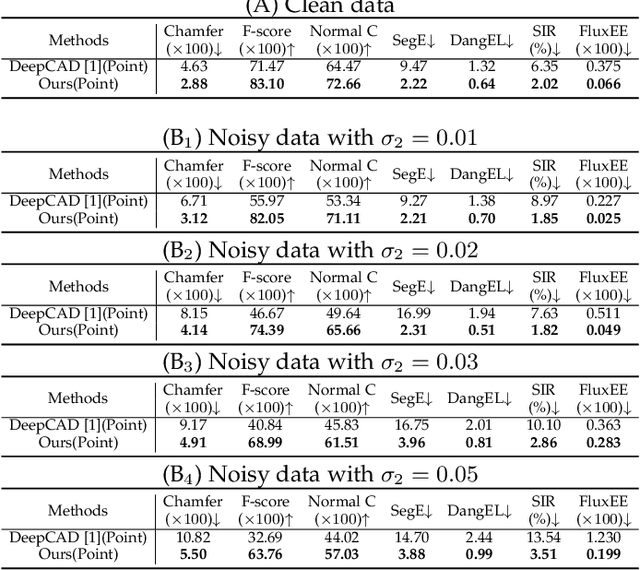
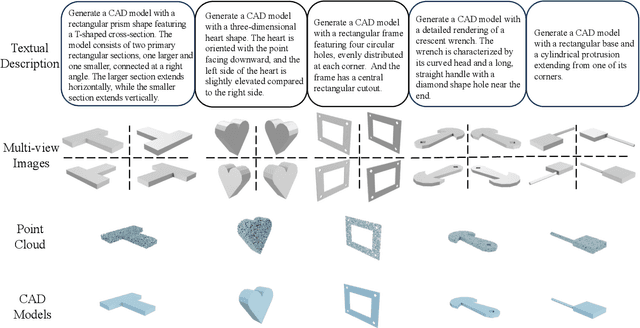
This paper aims to design a unified Computer-Aided Design (CAD) generation system that can easily generate CAD models based on the user's inputs in the form of textual description, images, point clouds, or even a combination of them. Towards this goal, we introduce the CAD-MLLM, the first system capable of generating parametric CAD models conditioned on the multimodal input. Specifically, within the CAD-MLLM framework, we leverage the command sequences of CAD models and then employ advanced large language models (LLMs) to align the feature space across these diverse multi-modalities data and CAD models' vectorized representations. To facilitate the model training, we design a comprehensive data construction and annotation pipeline that equips each CAD model with corresponding multimodal data. Our resulting dataset, named Omni-CAD, is the first multimodal CAD dataset that contains textual description, multi-view images, points, and command sequence for each CAD model. It contains approximately 450K instances and their CAD construction sequences. To thoroughly evaluate the quality of our generated CAD models, we go beyond current evaluation metrics that focus on reconstruction quality by introducing additional metrics that assess topology quality and surface enclosure extent. Extensive experimental results demonstrate that CAD-MLLM significantly outperforms existing conditional generative methods and remains highly robust to noises and missing points. The project page and more visualizations can be found at: https://cad-mllm.github.io/
Neuro-symbolic Learning Yielding Logical Constraints
Oct 28, 2024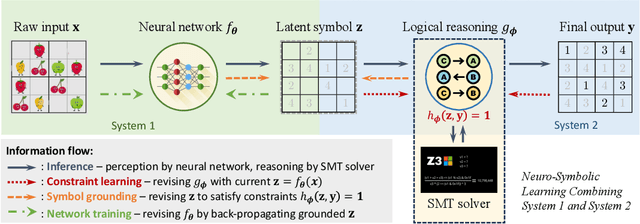
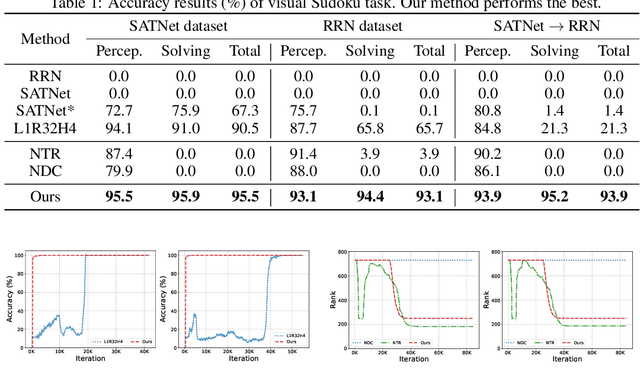
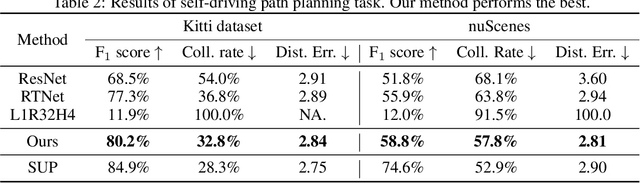
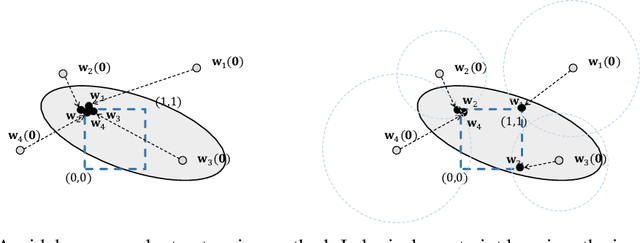
Neuro-symbolic systems combine the abilities of neural perception and logical reasoning. However, end-to-end learning of neuro-symbolic systems is still an unsolved challenge. This paper proposes a natural framework that fuses neural network training, symbol grounding, and logical constraint synthesis into a coherent and efficient end-to-end learning process. The capability of this framework comes from the improved interactions between the neural and the symbolic parts of the system in both the training and inference stages. Technically, to bridge the gap between the continuous neural network and the discrete logical constraint, we introduce a difference-of-convex programming technique to relax the logical constraints while maintaining their precision. We also employ cardinality constraints as the language for logical constraint learning and incorporate a trust region method to avoid the degeneracy of logical constraint in learning. Both theoretical analyses and empirical evaluations substantiate the effectiveness of the proposed framework.
LASER: Script Execution by Autonomous Agents for On-demand Traffic Simulation
Oct 21, 2024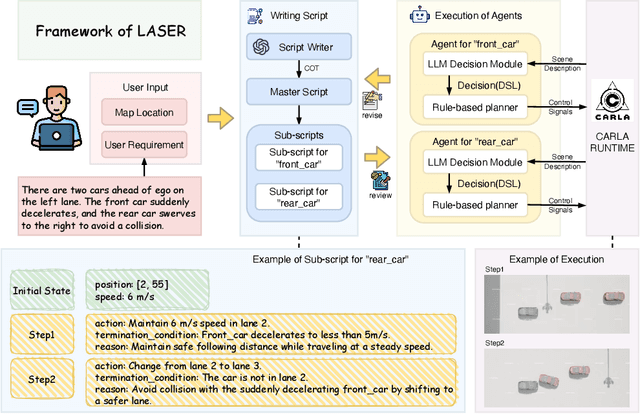
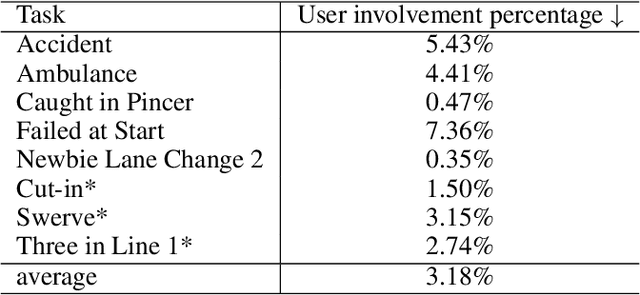
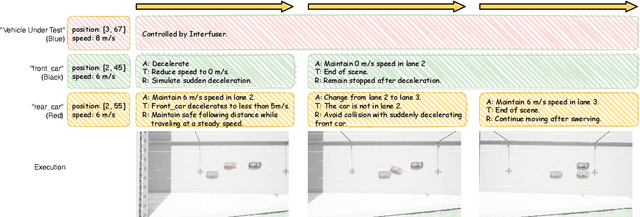
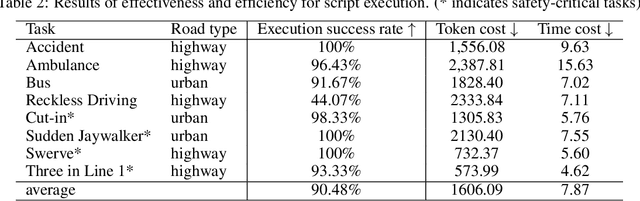
Autonomous Driving Systems (ADS) require diverse and safety-critical traffic scenarios for effective training and testing, but the existing data generation methods struggle to provide flexibility and scalability. We propose LASER, a novel frame-work that leverage large language models (LLMs) to conduct traffic simulations based on natural language inputs. The framework operates in two stages: it first generates scripts from user-provided descriptions and then executes them using autonomous agents in real time. Validated in the CARLA simulator, LASER successfully generates complex, on-demand driving scenarios, significantly improving ADS training and testing data generation.
Executing Arithmetic: Fine-Tuning Large Language Models as Turing Machines
Oct 10, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing and reasoning tasks. However, their performance in the foundational domain of arithmetic remains unsatisfactory. When dealing with arithmetic tasks, LLMs often memorize specific examples rather than learning the underlying computational logic, limiting their ability to generalize to new problems. In this paper, we propose a Composable Arithmetic Execution Framework (CAEF) that enables LLMs to learn to execute step-by-step computations by emulating Turing Machines, thereby gaining a genuine understanding of computational logic. Moreover, the proposed framework is highly scalable, allowing composing learned operators to significantly reduce the difficulty of learning complex operators. In our evaluation, CAEF achieves nearly 100% accuracy across seven common mathematical operations on the LLaMA 3.1-8B model, effectively supporting computations involving operands with up to 100 digits, a level where GPT-4o falls short noticeably in some settings.