 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Supervision Granularity: Segment-Level Learning for LLM-Based Theorem Proving
May 12, 2026Automated theorem proving with large language models in Lean 4 is commonly approached through either step-level tactic prediction with tree search or whole-proof generation. These two paradigms represent opposite granularities for constructing supervised training data: the former provides dense local signals but may fragment coherent proof processes, while the latter preserves global structure but requires complex end-to-end generation. In this paper, we revisit supervision granularity as a training set construction problem over proof trajectories and propose segment-level supervision, a training data construction strategy that extracts locally coherent proof segments for training policy models. We further reuse the same strategy at inference time to trigger short rollouts for existing step-level models. When trained with segment-level supervision on STP, LeanWorkbook, and NuminaMath-LEAN, the resulting policy models achieve proof success rates of 64.84%, 60.90%, and 66.31% on miniF2F, respectively, consistently outperforming both step-level and whole-proof baselines. Goal-aware rollout further improves existing step-level provers while reducing inference costs. It increases the proof success rate of BFS-Prover-V2-7B from 68.77% to 70.74% and that of InternLM2.5-StepProver from 59.59% to 60.33%, showing that appropriate supervision granularity better aligns model learning with proof structure and search. Code and models are available at https://github.com/NJUDeepEngine/SEG-ATP.
LLM-based Automated Theorem Proving Hinges on Scalable Synthetic Data Generation
May 17, 2025Recent advancements in large language models (LLMs) have sparked considerable interest in automated theorem proving and a prominent line of research integrates stepwise LLM-based provers into tree search. In this paper, we introduce a novel proof-state exploration approach for training data synthesis, designed to produce diverse tactics across a wide range of intermediate proof states, thereby facilitating effective one-shot fine-tuning of LLM as the policy model. We also propose an adaptive beam size strategy, which effectively takes advantage of our data synthesis method and achieves a trade-off between exploration and exploitation during tree search. Evaluations on the MiniF2F and ProofNet benchmarks demonstrate that our method outperforms strong baselines under the stringent Pass@1 metric, attaining an average pass rate of $60.74\%$ on MiniF2F and $21.18\%$ on ProofNet. These results underscore the impact of large-scale synthetic data in advancing automated theorem proving.
Neuro-Symbolic Data Generation for Math Reasoning
Dec 06, 2024



A critical question about Large Language Models (LLMs) is whether their apparent deficiency in mathematical reasoning is inherent, or merely a result of insufficient exposure to high-quality mathematical data. To explore this, we developed an automated method for generating high-quality, supervised mathematical datasets. The method carefully mutates existing math problems, ensuring both diversity and validity of the newly generated problems. This is achieved by a neuro-symbolic data generation framework combining the intuitive informalization strengths of LLMs, and the precise symbolic reasoning of math solvers along with projected Markov chain Monte Carlo sampling in the highly-irregular symbolic space. Empirical experiments demonstrate the high quality of data generated by the proposed method, and that the LLMs, specifically LLaMA-2 and Mistral, when realigned with the generated data, surpass their state-of-the-art counterparts.
Executing Arithmetic: Fine-Tuning Large Language Models as Turing Machines
Oct 10, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing and reasoning tasks. However, their performance in the foundational domain of arithmetic remains unsatisfactory. When dealing with arithmetic tasks, LLMs often memorize specific examples rather than learning the underlying computational logic, limiting their ability to generalize to new problems. In this paper, we propose a Composable Arithmetic Execution Framework (CAEF) that enables LLMs to learn to execute step-by-step computations by emulating Turing Machines, thereby gaining a genuine understanding of computational logic. Moreover, the proposed framework is highly scalable, allowing composing learned operators to significantly reduce the difficulty of learning complex operators. In our evaluation, CAEF achieves nearly 100% accuracy across seven common mathematical operations on the LLaMA 3.1-8B model, effectively supporting computations involving operands with up to 100 digits, a level where GPT-4o falls short noticeably in some settings.
Softened Symbol Grounding for Neuro-symbolic Systems
Mar 01, 2024



Neuro-symbolic learning generally consists of two separated worlds, i.e., neural network training and symbolic constraint solving, whose success hinges on symbol grounding, a fundamental problem in AI. This paper presents a novel, softened symbol grounding process, bridging the gap between the two worlds, and resulting in an effective and efficient neuro-symbolic learning framework. Technically, the framework features (1) modeling of symbol solution states as a Boltzmann distribution, which avoids expensive state searching and facilitates mutually beneficial interactions between network training and symbolic reasoning;(2) a new MCMC technique leveraging projection and SMT solvers, which efficiently samples from disconnected symbol solution spaces; (3) an annealing mechanism that can escape from %being trapped into sub-optimal symbol groundings. Experiments with three representative neuro symbolic learning tasks demonstrate that, owining to its superior symbol grounding capability, our framework successfully solves problems well beyond the frontier of the existing proposals.
Operational Calibration: Debugging Confidence Errors for DNNs in the Field
Oct 06, 2019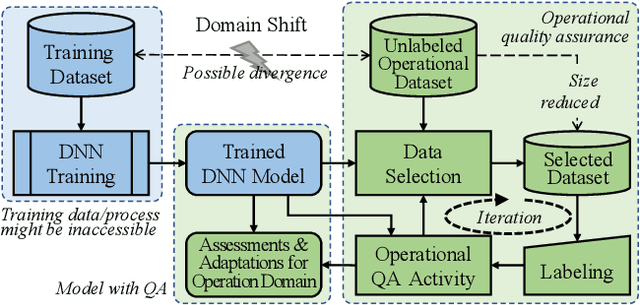
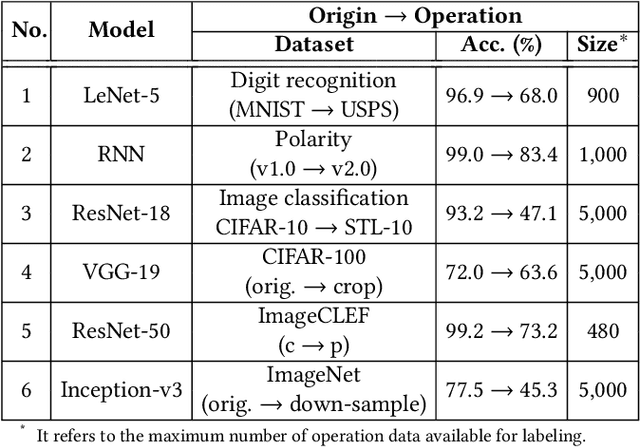
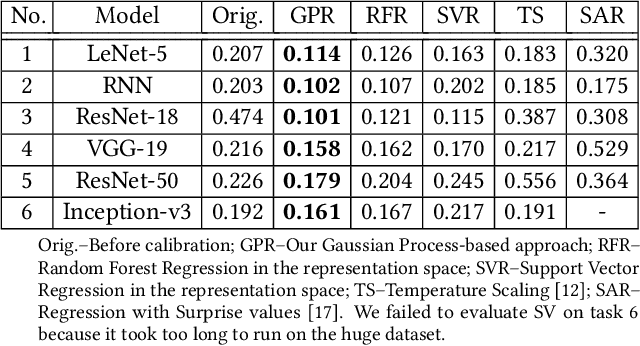
Trained DNN models are increasingly adopted as integral parts of software systems. However, they are often over-confident, especially in practical operation domains where slight divergence from their training data almost always exists. To minimize the loss due to inaccurate confidence, operational calibration, i.e., calibrating the confidence function of a DNN classifier against its operation domain, becomes a necessary debugging step in the engineering of the whole system. Operational calibration is difficult considering the limited budget of labeling operation data and the weak interpretability of DNN models. We propose a Bayesian approach to operational calibration that gradually corrects the confidence given by the model under calibration with a small number of labeled operational data deliberately selected from a larger set of unlabeled operational data. Exploiting the locality of the learned representation of the DNN model and modeling the calibration as Gaussian Process Regression, the approach achieves impressive efficacy and efficiency. Comprehensive experiments with various practical data sets and DNN models show that it significantly outperformed alternative methods, and in some difficult tasks it eliminated about 71% to 97% high-confidence errors with only about 10% of the minimal amount of labeled operation data needed for practical learning techniques to barely work.
Boosting Operational DNN Testing Efficiency through Conditioning
Jun 27, 2019



With the increasing adoption of Deep Neural Network (DNN) models as integral parts of software systems, efficient operational testing of DNNs is much in demand to ensure these models' actual performance in field conditions. A challenge is that the testing often needs to produce precise results with a very limited budget for labeling data collected in field. Viewing software testing as a practice of reliability estimation through statistical sampling, we re-interpret the idea behind conventional structural coverages as conditioning for variance reduction. With this insight we propose an efficient DNN testing method based on the conditioning on the representation learned by the DNN model under testing. The representation is defined by the probability distribution of the output of neurons in the last hidden layer of the model. To sample from this high dimensional distribution in which the operational data are sparsely distributed, we design an algorithm leveraging cross entropy minimization. Experiments with various DNN models and datasets were conducted to evaluate the general efficiency of the approach. The results show that, compared with simple random sampling, this approach requires only about a half of labeled inputs to achieve the same level of precision.