 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for LLM-based Code Generation
May 12, 2026Prediction sets provide a theoretically grounded framework for quantifying uncertainty in machine learning models. Adapting them to structured generation tasks, in particular, large language model (LLM) based code generation, remains a challenging problem. An existing attempt proposes PAC prediction sets but is limited by its strong monotonicity assumption on risk and single-label classification framework, which severely limits the space of candidate programs and cannot accommodate the multiple valid outputs inherent to code generation. To address these limitations, we propose an approach RisCoSet that leverages multiple hypothesis testing to construct risk-controlling predictions for LLM-based code generation. Given a trained code generation model, we produce a prediction set represented by a partial program, which is guaranteed to contain a correct solution with high confidence. Extensive experiments on three LLMs demonstrate the effectiveness of the proposed method. For instance, compared with the state-of-the-art, our method can significantly reduce the code removal by up to 24.5%, at the same level of risk.
Fair Conformal Classification via Learning Representation-Based Groups
May 12, 2026Conformal prediction methods provide statistically rigorous marginal coverage guarantees for machine learning models, but such guarantees fail to account for algorithmic biases, thereby undermining fairness and trust. This paper introduces a fair conformal inference framework for classification tasks. The proposed method constructs prediction sets that guarantee conditional coverage on adaptively identified subgroups, which can be implicitly defined through nonlinear feature combinations. By balancing effectiveness and efficiency in producing compact, informative prediction sets and ensuring adaptive equalized coverage across unfairly treated subgroups, our approach paves a practical pathway toward trustworthy machine learning. Extensive experiments on both synthetic and real-world datasets demonstrate the effectiveness of the framework.
Stepwise: Neuro-Symbolic Proof Search for Automated Systems Verification
Mar 20, 2026Formal verification via interactive theorem proving is increasingly used to ensure the correctness of critical systems, yet constructing large proof scripts remains highly manual and limits scalability. Advances in large language models (LLMs), especially in mathematical reasoning, make their integration into software verification increasingly promising. This paper introduces a neuro-symbolic proof generation framework designed to automate proof search for systems-level verification projects. The framework performs a best-first tree search over proof states, repeatedly querying an LLM for the next candidate proof step. On the neural side, we fine-tune LLMs using datasets of proof state-step pairs; on the symbolic side, we incorporate a range of ITP tools to repair rejected steps, filter and rank proof states, and automatically discharge subgoals when search progress stalls. This synergy enables data-efficient LLM adaptation and semantics-informed pruning of the search space. We implement the framework on a new Isabelle REPL that exposes fine-grained proof states and automation tools, and evaluate it on the FVEL seL4 benchmark and additional Isabelle developments. On seL4, the system proves up to 77.6\% of the theorems, substantially surpassing previous LLM-based approaches and standalone Sledgehammer, while solving significantly more multi-step proofs. Results across further benchmarks demonstrate strong generalization, indicating a viable path toward scalable automated software verification.
CODE-DITING: A Reasoning-Based Metric for Functional Alignment in Code Evaluation
May 26, 2025Trustworthy evaluation methods for code snippets play a crucial role in neural code generation. Traditional methods, which either rely on reference solutions or require executable test cases, have inherent limitation in flexibility and scalability. The recent LLM-as-Judge methodology offers a promising alternative by directly evaluating functional consistency between the problem description and the generated code. To systematically understand the landscape of these LLM-as-Judge methods, we conduct a comprehensive empirical study across three diverse datasets. Our investigation reveals the pros and cons of two categories of LLM-as-Judge methods: the methods based on general foundation models can achieve good performance but require complex prompts and lack explainability, while the methods based on reasoning foundation models provide better explainability with simpler prompts but demand substantial computational resources due to their large parameter sizes. To address these limitations, we propose CODE-DITING, a novel code evaluation method that balances accuracy, efficiency and explainability. We develop a data distillation framework that effectively transfers reasoning capabilities from DeepSeek-R1671B to our CODE-DITING 1.5B and 7B models, significantly enhancing evaluation explainability and reducing the computational cost. With the majority vote strategy in the inference process, CODE-DITING 1.5B outperforms all models with the same magnitude of parameters and achieves performance which would normally exhibit in a model with 5 times of parameter scale. CODE-DITING 7B surpasses GPT-4o and DeepSeek-V3 671B, even though it only uses 1% of the parameter volume of these large models. Further experiments show that CODEDITING is robust to preference leakage and can serve as a promising alternative for code evaluation.
LLM-based Automated Theorem Proving Hinges on Scalable Synthetic Data Generation
May 17, 2025Recent advancements in large language models (LLMs) have sparked considerable interest in automated theorem proving and a prominent line of research integrates stepwise LLM-based provers into tree search. In this paper, we introduce a novel proof-state exploration approach for training data synthesis, designed to produce diverse tactics across a wide range of intermediate proof states, thereby facilitating effective one-shot fine-tuning of LLM as the policy model. We also propose an adaptive beam size strategy, which effectively takes advantage of our data synthesis method and achieves a trade-off between exploration and exploitation during tree search. Evaluations on the MiniF2F and ProofNet benchmarks demonstrate that our method outperforms strong baselines under the stringent Pass@1 metric, attaining an average pass rate of $60.74\%$ on MiniF2F and $21.18\%$ on ProofNet. These results underscore the impact of large-scale synthetic data in advancing automated theorem proving.
Less is More: Towards Green Code Large Language Models via Unified Structural Pruning
Dec 20, 2024The extensive application of Large Language Models (LLMs) in generative coding tasks has raised concerns due to their high computational demands and energy consumption. Unlike previous structural pruning methods designed for classification models that deal with lowdimensional classification logits, generative Code LLMs produce high-dimensional token logit sequences, making traditional pruning objectives inherently limited. Moreover, existing single component pruning approaches further constrain the effectiveness when applied to generative Code LLMs. In response, we propose Flab-Pruner, an innovative unified structural pruning method that combines vocabulary, layer, and Feed-Forward Network (FFN) pruning. This approach effectively reduces model parameters while maintaining performance. Additionally, we introduce a customized code instruction data strategy for coding tasks to enhance the performance recovery efficiency of the pruned model. Through extensive evaluations on three state-of-the-art Code LLMs across multiple generative coding tasks, the results demonstrate that Flab-Pruner retains 97% of the original performance after pruning 22% of the parameters and achieves the same or even better performance after post-training. The pruned models exhibit significant improvements in storage, GPU usage, computational efficiency, and environmental impact, while maintaining well robustness. Our research provides a sustainable solution for green software engineering and promotes the efficient deployment of LLMs in real-world generative coding intelligence applications.
SimADFuzz: Simulation-Feedback Fuzz Testing for Autonomous Driving Systems
Dec 18, 2024

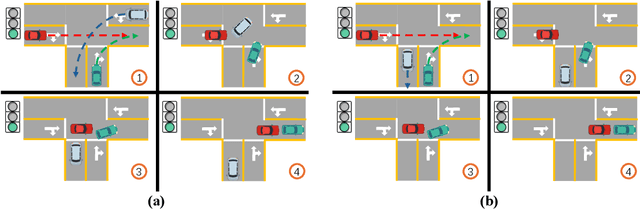

Autonomous driving systems (ADS) have achieved remarkable progress in recent years. However, ensuring their safety and reliability remains a critical challenge due to the complexity and uncertainty of driving scenarios. In this paper, we focus on simulation testing for ADS, where generating diverse and effective testing scenarios is a central task. Existing fuzz testing methods face limitations, such as overlooking the temporal and spatial dynamics of scenarios and failing to leverage simulation feedback (e.g., speed, acceleration and heading) to guide scenario selection and mutation. To address these issues, we propose SimADFuzz, a novel framework designed to generate high-quality scenarios that reveal violations in ADS behavior. Specifically, SimADFuzz employs violation prediction models, which evaluate the likelihood of ADS violations, to optimize scenario selection. Moreover, SimADFuzz proposes distance-guided mutation strategies to enhance interactions among vehicles in offspring scenarios, thereby triggering more edge-case behaviors of vehicles. Comprehensive experiments demonstrate that SimADFuzz outperforms state-of-the-art fuzzers by identifying 32 more unique violations, including 4 reproducible cases of vehicle-vehicle and vehicle-pedestrian collisions. These results demonstrate SimADFuzz's effectiveness in enhancing the robustness and safety of autonomous driving systems.
Neuro-symbolic Learning Yielding Logical Constraints
Oct 28, 2024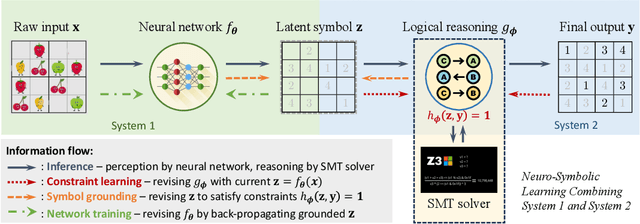
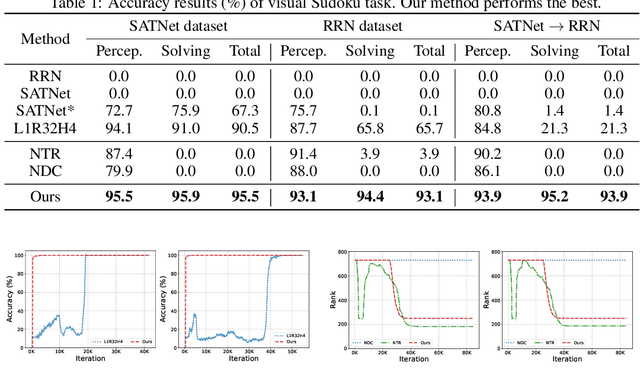
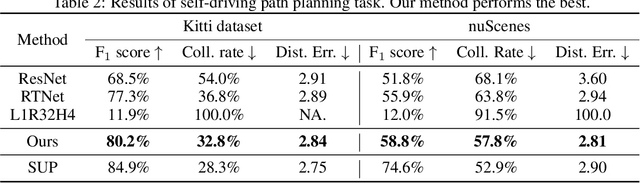
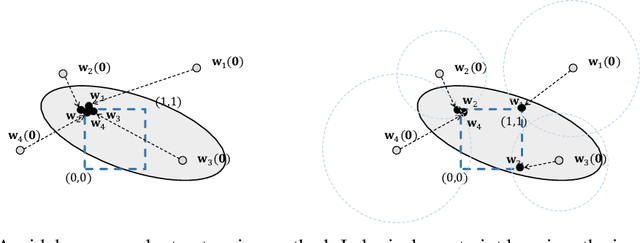
Neuro-symbolic systems combine the abilities of neural perception and logical reasoning. However, end-to-end learning of neuro-symbolic systems is still an unsolved challenge. This paper proposes a natural framework that fuses neural network training, symbol grounding, and logical constraint synthesis into a coherent and efficient end-to-end learning process. The capability of this framework comes from the improved interactions between the neural and the symbolic parts of the system in both the training and inference stages. Technically, to bridge the gap between the continuous neural network and the discrete logical constraint, we introduce a difference-of-convex programming technique to relax the logical constraints while maintaining their precision. We also employ cardinality constraints as the language for logical constraint learning and incorporate a trust region method to avoid the degeneracy of logical constraint in learning. Both theoretical analyses and empirical evaluations substantiate the effectiveness of the proposed framework.
LASER: Script Execution by Autonomous Agents for On-demand Traffic Simulation
Oct 21, 2024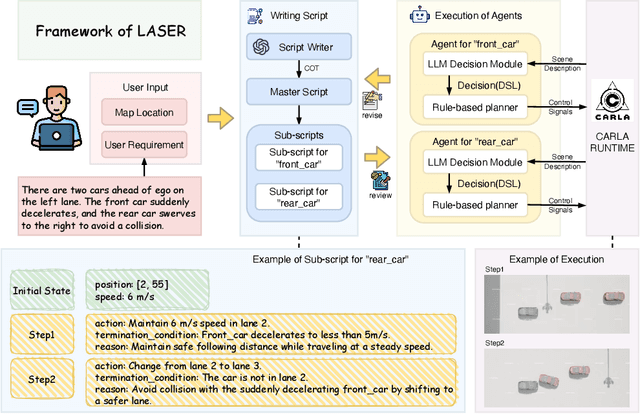
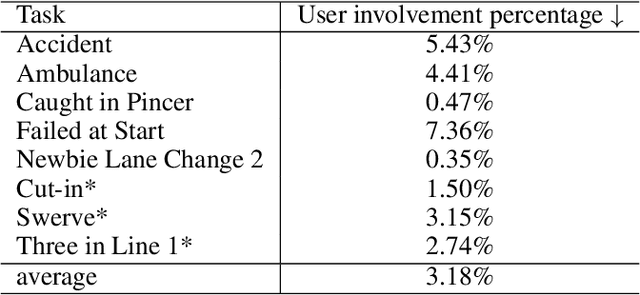
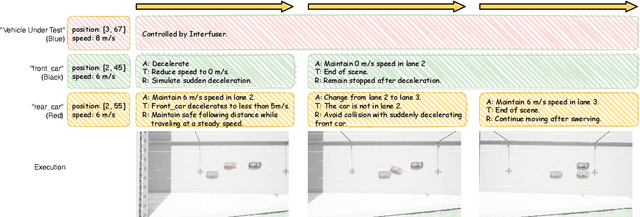
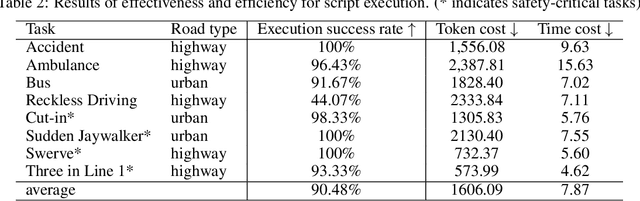
Autonomous Driving Systems (ADS) require diverse and safety-critical traffic scenarios for effective training and testing, but the existing data generation methods struggle to provide flexibility and scalability. We propose LASER, a novel frame-work that leverage large language models (LLMs) to conduct traffic simulations based on natural language inputs. The framework operates in two stages: it first generates scripts from user-provided descriptions and then executes them using autonomous agents in real time. Validated in the CARLA simulator, LASER successfully generates complex, on-demand driving scenarios, significantly improving ADS training and testing data generation.
Learning with Logical Constraints but without Shortcut Satisfaction
Mar 01, 2024



Recent studies in neuro-symbolic learning have explored the integration of logical knowledge into deep learning via encoding logical constraints as an additional loss function. However, existing approaches tend to vacuously satisfy logical constraints through shortcuts, failing to fully exploit the knowledge. In this paper, we present a new framework for learning with logical constraints. Specifically, we address the shortcut satisfaction issue by introducing dual variables for logical connectives, encoding how the constraint is satisfied. We further propose a variational framework where the encoded logical constraint is expressed as a distributional loss that is compatible with the model's original training loss. The theoretical analysis shows that the proposed approach bears salient properties, and the experimental evaluations demonstrate its superior performance in both model generalizability and constraint satisfaction.