 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCert: Probabilistic Certification for Behavioral Similarity in Deep Neural Network Compression
Mar 16, 2026Deploying Deep Neural Networks (DNNs) on resource-constrained embedded systems requires aggressive model compression techniques like quantization and pruning. However, ensuring that the compressed model preserves the behavioral fidelity of the original design is a critical challenge in the safety-critical system design flow. Existing verification methods often lack scalability or fail to handle the architectural heterogeneity introduced by pruning. In this work, we propose SimCert, a probabilistic certification framework for verifying the behavioral similarity of compressed neural networks. Unlike worst-case analysis, SimCert provides quantitative safety guarantees with adjustable confidence levels. Our framework features: (1) A dual-network symbolic propagation method supporting both quantization and pruning; (2) A variance-aware bounding technique using Bernstein's inequality to tighten safety certificates; and (3) An automated verification toolchain. Experimental results on ACAS Xu and computer vision benchmarks demonstrate that SimCert outperforms state-of-the-art baselines.
AudioJailbreak: Jailbreak Attacks against End-to-End Large Audio-Language Models
May 21, 2025



Jailbreak attacks to Large audio-language models (LALMs) are studied recently, but they achieve suboptimal effectiveness, applicability, and practicability, particularly, assuming that the adversary can fully manipulate user prompts. In this work, we first conduct an extensive experiment showing that advanced text jailbreak attacks cannot be easily ported to end-to-end LALMs via text-to speech (TTS) techniques. We then propose AudioJailbreak, a novel audio jailbreak attack, featuring (1) asynchrony: the jailbreak audio does not need to align with user prompts in the time axis by crafting suffixal jailbreak audios; (2) universality: a single jailbreak perturbation is effective for different prompts by incorporating multiple prompts into perturbation generation; (3) stealthiness: the malicious intent of jailbreak audios will not raise the awareness of victims by proposing various intent concealment strategies; and (4) over-the-air robustness: the jailbreak audios remain effective when being played over the air by incorporating the reverberation distortion effect with room impulse response into the generation of the perturbations. In contrast, all prior audio jailbreak attacks cannot offer asynchrony, universality, stealthiness, or over-the-air robustness. Moreover, AudioJailbreak is also applicable to the adversary who cannot fully manipulate user prompts, thus has a much broader attack scenario. Extensive experiments with thus far the most LALMs demonstrate the high effectiveness of AudioJailbreak. We highlight that our work peeks into the security implications of audio jailbreak attacks against LALMs, and realistically fosters improving their security robustness. The implementation and audio samples are available at our website https://audiojailbreak.github.io/AudioJailbreak.
Verification of Bit-Flip Attacks against Quantized Neural Networks
Feb 22, 2025



In the rapidly evolving landscape of neural network security, the resilience of neural networks against bit-flip attacks (i.e., an attacker maliciously flips an extremely small amount of bits within its parameter storage memory system to induce harmful behavior), has emerged as a relevant area of research. Existing studies suggest that quantization may serve as a viable defense against such attacks. Recognizing the documented susceptibility of real-valued neural networks to such attacks and the comparative robustness of quantized neural networks (QNNs), in this work, we introduce BFAVerifier, the first verification framework designed to formally verify the absence of bit-flip attacks or to identify all vulnerable parameters in a sound and rigorous manner. BFAVerifier comprises two integral components: an abstraction-based method and an MILP-based method. Specifically, we first conduct a reachability analysis with respect to symbolic parameters that represent the potential bit-flip attacks, based on a novel abstract domain with a sound guarantee. If the reachability analysis fails to prove the resilience of such attacks, then we encode this verification problem into an equivalent MILP problem which can be solved by off-the-shelf solvers. Therefore, BFAVerifier is sound, complete, and reasonably efficient. We conduct extensive experiments, which demonstrate its effectiveness and efficiency across various network architectures, quantization bit-widths, and adversary capabilities.
Training Verification-Friendly Neural Networks via Neuron Behavior Consistency
Dec 17, 2024



Formal verification provides critical security assurances for neural networks, yet its practical application suffers from the long verification time. This work introduces a novel method for training verification-friendly neural networks, which are robust, easy to verify, and relatively accurate. Our method integrates neuron behavior consistency into the training process, making neuron activation states consistent across different inputs in a local neighborhood, reducing the number of unstable neurons and tightening the bounds of neurons thereby enhancing neural network verifiability. We evaluated our method using the MNIST, Fashion-MNIST, and CIFAR-10 datasets across various network architectures. The results of the experiment demonstrate that networks trained using our method are verification-friendly across different radii and different model architectures, whereas other tools fail to maintain verifiability as the radius increases. We also show that our method can be combined with existing methods to further improve the verifiability of networks.
LaserGuider: A Laser Based Physical Backdoor Attack against Deep Neural Networks
Dec 05, 2024



Backdoor attacks embed hidden associations between triggers and targets in deep neural networks (DNNs), causing them to predict the target when a trigger is present while maintaining normal behavior otherwise. Physical backdoor attacks, which use physical objects as triggers, are feasible but lack remote control, temporal stealthiness, flexibility, and mobility. To overcome these limitations, in this work, we propose a new type of backdoor triggers utilizing lasers that feature long-distance transmission and instant-imaging properties. Based on the laser-based backdoor triggers, we present a physical backdoor attack, called LaserGuider, which possesses remote control ability and achieves high temporal stealthiness, flexibility, and mobility. We also introduce a systematic approach to optimize laser parameters for improving attack effectiveness. Our evaluation on traffic sign recognition DNNs, critical in autonomous vehicles, demonstrates that LaserGuider with three different laser-based triggers achieves over 90% attack success rate with negligible impact on normal inputs. Additionally, we release LaserMark, the first dataset of real world traffic signs stamped with physical laser spots, to support further research in backdoor attacks and defenses.
A Proactive and Dual Prevention Mechanism against Illegal Song Covers empowered by Singing Voice Conversion
Jan 30, 2024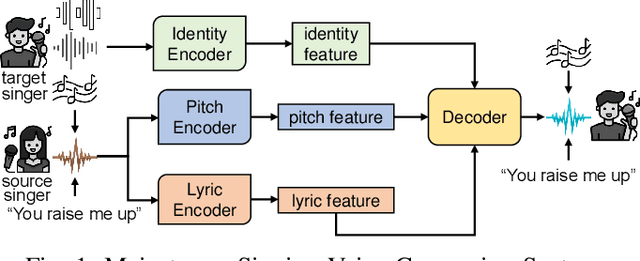
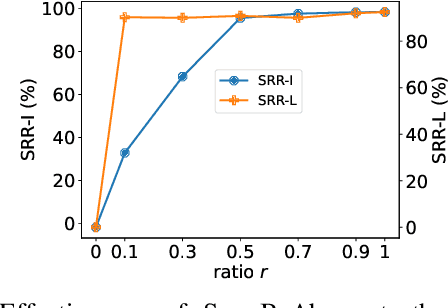
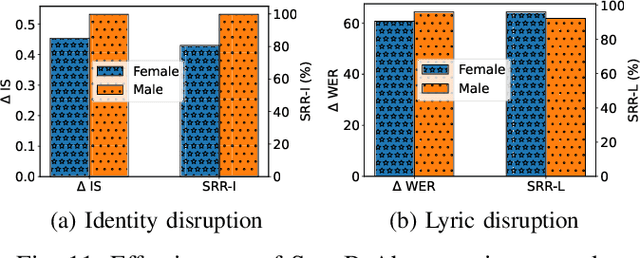
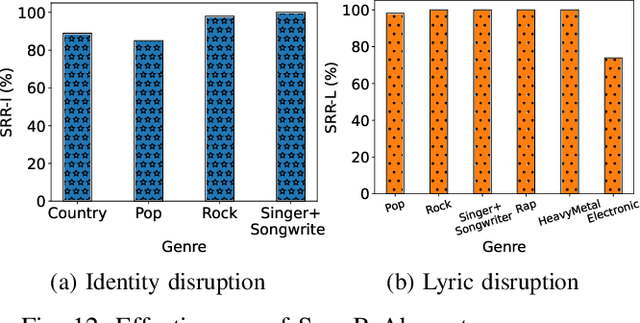
Singing voice conversion (SVC) automates song covers by converting one singer's singing voice into another target singer's singing voice with the original lyrics and melody. However, it raises serious concerns about copyright and civil right infringements to multiple entities. This work proposes SongBsAb, the first proactive approach to mitigate unauthorized SVC-based illegal song covers. SongBsAb introduces human-imperceptible perturbations to singing voices before releasing them, so that when they are used, the generation process of SVC will be interfered, resulting in unexpected singing voices. SongBsAb features a dual prevention effect by causing both (singer) identity disruption and lyric disruption, namely, the SVC-covered singing voice neither imitates the target singer nor preserves the original lyrics. To improve the imperceptibility of perturbations, we refine a psychoacoustic model-based loss with the backing track as an additional masker, a unique accompanying element for singing voices compared to ordinary speech voices. To enhance the transferability, we propose to utilize a frame-level interaction reduction-based loss. We demonstrate the prevention effectiveness, utility, and robustness of SongBsAb on three SVC models and two datasets using both objective and human study-based subjective metrics. Our work fosters an emerging research direction for mitigating illegal automated song covers.
When Neural Code Completion Models Size up the Situation: Attaining Cheaper and Faster Completion through Dynamic Model Inference
Jan 18, 2024

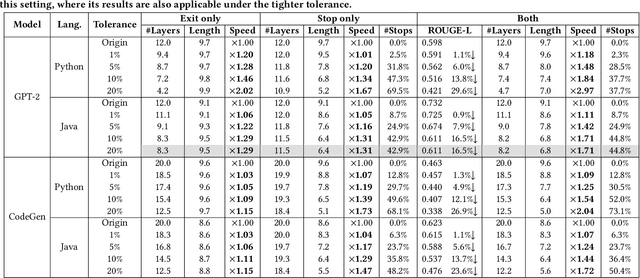

Leveraging recent advancements in large language models, modern neural code completion models have demonstrated the capability to generate highly accurate code suggestions. However, their massive size poses challenges in terms of computational costs and environmental impact, hindering their widespread adoption in practical scenarios. Dynamic inference emerges as a promising solution, as it allocates minimal computation during inference while maintaining the model's performance. In this research, we explore dynamic inference within the context of code completion. Initially, we conducted an empirical investigation on GPT-2, focusing on the inference capabilities of intermediate layers for code completion. We found that 54.4% of tokens can be accurately generated using just the first layer, signifying significant computational savings potential. Moreover, despite using all layers, the model still fails to predict 14.5% of tokens correctly, and the subsequent completions continued from them are rarely considered helpful, with only a 4.2% Acceptance Rate. These findings motivate our exploration of dynamic inference in code completion and inspire us to enhance it with a decision-making mechanism that stops the generation of incorrect code. We thus propose a novel dynamic inference method specifically tailored for code completion models. This method aims not only to produce correct predictions with largely reduced computation but also to prevent incorrect predictions proactively. Our extensive evaluation shows that it can averagely skip 1.7 layers out of 16 layers in the models, leading to an 11.2% speedup with only a marginal 1.1% reduction in ROUGE-L.
SLMIA-SR: Speaker-Level Membership Inference Attacks against Speaker Recognition Systems
Sep 14, 2023Membership inference attacks allow adversaries to determine whether a particular example was contained in the model's training dataset. While previous works have confirmed the feasibility of such attacks in various applications, none has focused on speaker recognition (SR), a promising voice-based biometric recognition technique. In this work, we propose SLMIA-SR, the first membership inference attack tailored to SR. In contrast to conventional example-level attack, our attack features speaker-level membership inference, i.e., determining if any voices of a given speaker, either the same as or different from the given inference voices, have been involved in the training of a model. It is particularly useful and practical since the training and inference voices are usually distinct, and it is also meaningful considering the open-set nature of SR, namely, the recognition speakers were often not present in the training data. We utilize intra-closeness and inter-farness, two training objectives of SR, to characterize the differences between training and non-training speakers and quantify them with two groups of features driven by carefully-established feature engineering to mount the attack. To improve the generalizability of our attack, we propose a novel mixing ratio training strategy to train attack models. To enhance the attack performance, we introduce voice chunk splitting to cope with the limited number of inference voices and propose to train attack models dependent on the number of inference voices. Our attack is versatile and can work in both white-box and black-box scenarios. Additionally, we propose two novel techniques to reduce the number of black-box queries while maintaining the attack performance. Extensive experiments demonstrate the effectiveness of SLMIA-SR.
CodeMark: Imperceptible Watermarking for Code Datasets against Neural Code Completion Models
Aug 28, 2023



Code datasets are of immense value for training neural-network-based code completion models, where companies or organizations have made substantial investments to establish and process these datasets. Unluckily, these datasets, either built for proprietary or public usage, face the high risk of unauthorized exploits, resulting from data leakages, license violations, etc. Even worse, the ``black-box'' nature of neural models sets a high barrier for externals to audit their training datasets, which further connives these unauthorized usages. Currently, watermarking methods have been proposed to prohibit inappropriate usage of image and natural language datasets. However, due to domain specificity, they are not directly applicable to code datasets, leaving the copyright protection of this emerging and important field of code data still exposed to threats. To fill this gap, we propose a method, named CodeMark, to embed user-defined imperceptible watermarks into code datasets to trace their usage in training neural code completion models. CodeMark is based on adaptive semantic-preserving transformations, which preserve the exact functionality of the code data and keep the changes covert against rule-breakers. We implement CodeMark in a toolkit and conduct an extensive evaluation of code completion models. CodeMark is validated to fulfill all desired properties of practical watermarks, including harmlessness to model accuracy, verifiability, robustness, and imperceptibility.
An Empirical Study of Bugs in Open-Source Federated Learning Framework
Aug 09, 2023



Federated learning (FL), as a decentralized machine learning solution to the protection of users' private data, has become an important learning paradigm in recent years, especially since the enforcement of stricter laws and regulations in most countries. Therefore, a variety of FL frameworks are released to facilitate the development and application of federated learning. Despite the considerable amount of research on the security and privacy of FL models and systems, the security issues in FL frameworks have not been systematically studied yet. In this paper, we conduct the first empirical study on 1,112 FL framework bugs to investigate their characteristics. These bugs are manually collected, classified, and labeled from 12 open-source FL frameworks on GitHub. In detail, we construct taxonomies of 15 symptoms, 12 root causes, and 20 fix patterns of these bugs and investigate their correlations and distributions on 23 logical components and two main application scenarios. From the results of our study, we present nine findings, discuss their implications, and propound several suggestions to FL framework developers and security researchers on the FL frameworks.