 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecuting as You Generate: Hiding Execution Latency in LLM Code Generation
Apr 01, 2026Current LLM-based coding agents follow a serial execution paradigm: the model first generates the complete code, then invokes an interpreter to execute it. This sequential workflow leaves the executor idle during generation and the generator idle during execution, resulting in unnecessary end-to-end latency. We observe that, unlike human developers, LLMs produce code tokens sequentially without revision, making it possible to execute code as it is being generated. We formalize this parallel execution paradigm, modeling it as a three-stage pipeline of generation, detection, and execution, and derive closed-form latency bounds that characterize its speedup potential and operating regimes. We then present Eager, a concrete implementation featuring AST-based chunking, dynamic batching with gated execution, and early error interruption. We evaluate Eager across four benchmarks, seven LLMs, and three execution environments. Results show that Eager reduces the non-overlapped execution latency by up to 99.9% and the end-to-end latency by up to 55% across seven LLMs and four benchmarks.
Rethinking the Value of Agent-Generated Tests for LLM-Based Software Engineering Agents
Feb 08, 2026Large Language Model (LLM) code agents increasingly resolve repository-level issues by iteratively editing code, invoking tools, and validating candidate patches. In these workflows, agents often write tests on the fly, a paradigm adopted by many high-ranking agents on the SWE-bench leaderboard. However, we observe that GPT-5.2, which writes almost no new tests, can even achieve performance comparable to top-ranking agents. This raises the critical question: whether such tests meaningfully improve issue resolution or merely mimic human testing practices while consuming a substantial interaction budget. To reveal the impact of agent-written tests, we present an empirical study that analyzes agent trajectories across six state-of-the-art LLMs on SWE-bench Verified. Our results show that while test writing is commonly adopted, but resolved and unresolved tasks within the same model exhibit similar test-writing frequencies Furthermore, these tests typically serve as observational feedback channels, where agents prefer value-revealing print statements significantly more than formal assertion-based checks. Based on these insights, we perform a controlled experiment by revising the prompts of four agents to either increase or reduce test writing. The results suggest that changes in the volume of agent-written tests do not significantly change final outcomes. Taken together, our study reveals that current test-writing practices may provide marginal utility in autonomous software engineering tasks.
CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Feb 02, 2026Large Language Models (LLMs) have achieved remarkable success in source code understanding, yet as software systems grow in scale, computational efficiency has become a critical bottleneck. Currently, these models rely on a text-based paradigm that treats source code as a linear sequence of tokens, which leads to a linear increase in context length and associated computational costs. The rapid advancement of Multimodal LLMs (MLLMs) introduces an opportunity to optimize efficiency by representing source code as rendered images. Unlike text, which is difficult to compress without losing semantic meaning, the image modality is inherently suitable for compression. By adjusting resolution, images can be scaled to a fraction of their original token cost while remaining recognizable to vision-capable models. To explore the feasibility of this approach, we conduct the first systematic study on the effectiveness of MLLMs for code understanding. Our experiments reveal that: (1) MLLMs can effectively understand code with substantial token reduction, achieving up to 8x compression; (2) MLLMs can effectively leverage visual cues such as syntax highlighting, improving code completion performance under 4x compression; and (3) Code-understanding tasks like clone detection exhibit exceptional resilience to visual compression, with some compression ratios even slightly outperforming raw text inputs. Our findings highlight both the potential and current limitations of MLLMs in code understanding, which points out a shift toward image-modality code representation as a pathway to more efficient inference.
Autoregressive, Yet Revisable: In Decoding Revision for Secure Code Generation
Feb 01, 2026Large Language Model (LLM) based code generation is predominantly formulated as a strictly monotonic process, appending tokens linearly to an immutable prefix. This formulation contrasts to the cognitive process of programming, which is inherently interleaved with forward generation and on-the-fly revision. While prior works attempt to introduce revision via post-hoc agents or external static tools, they either suffer from high latency or fail to leverage the model's intrinsic semantic reasoning. In this paper, we propose Stream of Revision, a paradigm shift that elevates code generation from a monotonic stream to a dynamic, self-correcting trajectory by leveraging model's intrinsic capabilities. We introduce specific action tokens that enable the model to seamlessly backtrack and edit its own history within a single forward pass. By internalizing the revision loop, our framework Stream of Revision allows the model to activate its latent capabilities just-in-time without external dependencies. Empirical results on secure code generation show that Stream of Revision significantly reduces vulnerabilities with minimal inference overhead.
LLM as Runtime Error Handler: A Promising Pathway to Adaptive Self-Healing of Software Systems
Aug 02, 2024



Unanticipated runtime errors, lacking predefined handlers, can abruptly terminate execution and lead to severe consequences, such as data loss or system crashes. Despite extensive efforts to identify potential errors during the development phase, such unanticipated errors remain a challenge to to be entirely eliminated, making the runtime mitigation measurements still indispensable to minimize their impact. Automated self-healing techniques, such as reusing existing handlers, have been investigated to reduce the loss coming through with the execution termination. However, the usability of existing methods is retained by their predefined heuristic rules and they fail to handle diverse runtime errors adaptively. Recently, the advent of Large Language Models (LLMs) has opened new avenues for addressing this problem. Inspired by their remarkable capabilities in understanding and generating code, we propose to deal with the runtime errors in a real-time manner using LLMs. Specifically, we propose Healer, the first LLM-assisted self-healing framework for handling runtime errors. When an unhandled runtime error occurs, Healer will be activated to generate a piece of error-handling code with the help of its internal LLM and the code will be executed inside the runtime environment owned by the framework to obtain a rectified program state from which the program should continue its execution. Our exploratory study evaluates the performance of Healer using four different code benchmarks and three state-of-the-art LLMs, GPT-3.5, GPT-4, and CodeQwen-7B. Results show that, without the need for any fine-tuning, GPT-4 can successfully help programs recover from 72.8% of runtime errors, highlighting the potential of LLMs in handling runtime errors.
AI Coders Are Among Us: Rethinking Programming Language Grammar Towards Efficient Code Generation
Apr 25, 2024Besides humans and machines, Artificial Intelligence (AI) models have emerged to be another important audience of programming languages, as we come to the era of large language models (LLMs). LLMs can now excel at coding competitions and even program like developers to address various tasks, such as math calculation. Yet, the grammar and layout of existing programs are designed for humans. Particularly, abundant grammar tokens and formatting tokens are included to make the code more readable to humans. While beneficial, such a human-centric design imposes an unnecessary computational burden on LLMs where each token, either consumed or generated, consumes computational resources. To improve inference efficiency and reduce computational costs, we propose the concept of AI-oriented grammar, which aims to represent the code in a way that better suits the working mechanism of AI models. Code written with AI-oriented grammar discards formats and uses a minimum number of tokens to convey code semantics effectively. To demonstrate the feasibility of this concept, we explore and implement the first AI-oriented grammar for Python, named Simple Python (SimPy). SimPy is crafted by revising the original Python grammar through a series of heuristic rules. Programs written in SimPy maintain identical Abstract Syntax Tree (AST) structures to those in standard Python, allowing execution via a modified AST parser. In addition, we explore methods to enable existing LLMs to proficiently understand and use SimPy, and ensure the changes remain imperceptible for human developers. Compared with the original Python, SimPy not only reduces token usage by 13.5% and 10.4% for CodeLlama and GPT-4, but can also achieve equivalent, even improved, performance over the models trained on Python code.
Reversible Jump Attack to Textual Classifiers with Modification Reduction
Mar 21, 2024



Recent studies on adversarial examples expose vulnerabilities of natural language processing (NLP) models. Existing techniques for generating adversarial examples are typically driven by deterministic hierarchical rules that are agnostic to the optimal adversarial examples, a strategy that often results in adversarial samples with a suboptimal balance between magnitudes of changes and attack successes. To this end, in this research we propose two algorithms, Reversible Jump Attack (RJA) and Metropolis-Hasting Modification Reduction (MMR), to generate highly effective adversarial examples and to improve the imperceptibility of the examples, respectively. RJA utilizes a novel randomization mechanism to enlarge the search space and efficiently adapts to a number of perturbed words for adversarial examples. With these generated adversarial examples, MMR applies the Metropolis-Hasting sampler to enhance the imperceptibility of adversarial examples. Extensive experiments demonstrate that RJA-MMR outperforms current state-of-the-art methods in attack performance, imperceptibility, fluency and grammar correctness.
When Neural Code Completion Models Size up the Situation: Attaining Cheaper and Faster Completion through Dynamic Model Inference
Jan 18, 2024

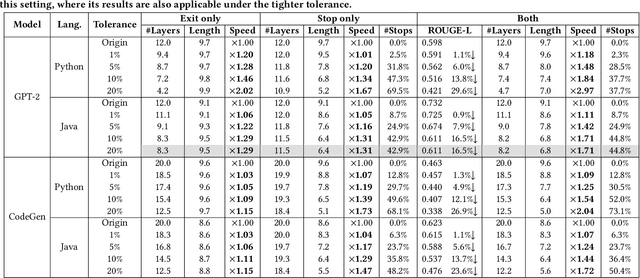

Leveraging recent advancements in large language models, modern neural code completion models have demonstrated the capability to generate highly accurate code suggestions. However, their massive size poses challenges in terms of computational costs and environmental impact, hindering their widespread adoption in practical scenarios. Dynamic inference emerges as a promising solution, as it allocates minimal computation during inference while maintaining the model's performance. In this research, we explore dynamic inference within the context of code completion. Initially, we conducted an empirical investigation on GPT-2, focusing on the inference capabilities of intermediate layers for code completion. We found that 54.4% of tokens can be accurately generated using just the first layer, signifying significant computational savings potential. Moreover, despite using all layers, the model still fails to predict 14.5% of tokens correctly, and the subsequent completions continued from them are rarely considered helpful, with only a 4.2% Acceptance Rate. These findings motivate our exploration of dynamic inference in code completion and inspire us to enhance it with a decision-making mechanism that stops the generation of incorrect code. We thus propose a novel dynamic inference method specifically tailored for code completion models. This method aims not only to produce correct predictions with largely reduced computation but also to prevent incorrect predictions proactively. Our extensive evaluation shows that it can averagely skip 1.7 layers out of 16 layers in the models, leading to an 11.2% speedup with only a marginal 1.1% reduction in ROUGE-L.
CodeMark: Imperceptible Watermarking for Code Datasets against Neural Code Completion Models
Aug 28, 2023



Code datasets are of immense value for training neural-network-based code completion models, where companies or organizations have made substantial investments to establish and process these datasets. Unluckily, these datasets, either built for proprietary or public usage, face the high risk of unauthorized exploits, resulting from data leakages, license violations, etc. Even worse, the ``black-box'' nature of neural models sets a high barrier for externals to audit their training datasets, which further connives these unauthorized usages. Currently, watermarking methods have been proposed to prohibit inappropriate usage of image and natural language datasets. However, due to domain specificity, they are not directly applicable to code datasets, leaving the copyright protection of this emerging and important field of code data still exposed to threats. To fill this gap, we propose a method, named CodeMark, to embed user-defined imperceptible watermarks into code datasets to trace their usage in training neural code completion models. CodeMark is based on adaptive semantic-preserving transformations, which preserve the exact functionality of the code data and keep the changes covert against rule-breakers. We implement CodeMark in a toolkit and conduct an extensive evaluation of code completion models. CodeMark is validated to fulfill all desired properties of practical watermarks, including harmlessness to model accuracy, verifiability, robustness, and imperceptibility.
Data Augmentation Approaches for Source Code Models: A Survey
Jun 12, 2023



The increasingly popular adoption of source code in many critical tasks motivates the development of data augmentation (DA) techniques to enhance training data and improve various capabilities (e.g., robustness and generalizability) of these models. Although a series of DA methods have been proposed and tailored for source code models, there lacks a comprehensive survey and examination to understand their effectiveness and implications. This paper fills this gap by conducting a comprehensive and integrative survey of data augmentation for source code, wherein we systematically compile and encapsulate existing literature to provide a comprehensive overview of the field. We start by constructing a taxonomy of DA for source code models model approaches, followed by a discussion on prominent, methodologically illustrative approaches. Next, we highlight the general strategies and techniques to optimize the DA quality. Subsequently, we underscore techniques that find utility in widely-accepted source code scenarios and downstream tasks. Finally, we outline the prevailing challenges and potential opportunities for future research. In essence, this paper endeavors to demystify the corpus of existing literature on DA for source code models, and foster further exploration in this sphere. Complementing this, we present a continually updated GitHub repository that hosts a list of update-to-date papers on DA for source code models, accessible at \url{https://github.com/terryyz/DataAug4Code}.