 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Chain: Benchmarking Coding Agents on Chained Release-Level Package Upgrades
May 14, 2026Coding agents powered by large language models are increasingly expected to perform realistic software maintenance tasks beyond isolated issue resolution. Existing benchmarks have shifted toward realistic software evolution, but they rarely capture continuous maintenance at the granularity of package releases, where changes are bundled, shipped, and inherited by subsequent versions. We present SWE-Chain, a benchmark for evaluating agents on chained release-level package upgrades, where each transition builds on the agent's prior codebase. To produce upgrade specifications, we design a divide-and-conquer synthesis pipeline that aligns release notes with code diffs for each version transition, ensuring the requirements are grounded in actual code changes, informative to agents, and feasible to implement. SWE-Chain contains 12 upgrade chains across 9 real Python packages, with 155 version transitions and 1,660 grounded upgrade requirements. Across nine frontier agent-model configurations, agents achieve an average of 44.8% resolving, 65.4% precision, and 50.2% F1 under the Build+Fix regime, with Claude-Opus-4.7 (Claude Code) leading at 60.8% resolving, 80.6% precision, and 68.5% F1. These results show that SWE-Chain is both feasible and discriminative, and reveal that current agents still struggle to make correct upgrades across chained package releases without breaking existing functionality.
ShredBench: Evaluating the Semantic Reasoning Capabilities of Multimodal LLMs in Document Reconstruction
Apr 26, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable performance in Visually Rich Document Understanding (VRDU) tasks, but their capabilities are mainly evaluated on pristine, well-structured document images. We consider content restoration from shredded fragments, a challenging VRDU setting that requires integrating visual pattern recognition with semantic reasoning under significant content discontinuities. To facilitate systematic evaluation of complex VRDU tasks, we introduce ShredBench, a benchmark supported by an automated generation pipeline that renders fragmented documents directly from Markdown. The proposed pipeline ensures evaluation validity by allowing the flexible integration of latest or unseen textual sources to prevent training data contamination. ShredBench assesses four scenarios (English, Chinese, Code, Table) with three fragmentation granularities (8, 12, 16 pieces). Empirical evaluations on state-of-the-art MLLMs reveal a significant performance gap: The method is effective on intact documents; however, once the document is shredded, restoration becomes a significant challenge, with NED dropping sharply as fragmentation increases. Our findings highlight that current MLLMs lack the fine-grained cross-modal reasoning required to bridge visual discontinuities, identifying a critical gap in robust VRDU research.
TRAJEVAL: Decomposing Code Agent Trajectories for Fine-Grained Diagnosis
Mar 25, 2026Code agents can autonomously resolve GitHub issues, yet when they fail, current evaluation provides no visibility into where or why. Metrics such as Pass@1 collapse an entire execution into a single binary outcome, making it difficult to identify where and why the agent went wrong. To address this limitation, we introduce TRAJEVAL, a diagnostic framework that decomposes agent trajectories into three interpretable stages: search (file localization), read (function comprehension), and edit (modification targeting). For each stage, we compute precision and recall by comparing against reference patches. Analyzing 16,758 trajectories across three agent architectures and seven models, we find universal inefficiencies (all agents examine approximately 22x more functions than necessary) yet distinct failure modes: GPT-5 locates relevant code but targets edits incorrectly, while Qwen-32B fails at file discovery entirely. We validate that these diagnostics are predictive, achieving model-level Pass@1 prediction within 0.87-2.1% MAE, and actionable: real-time feedback based on trajectory signals improves two state-of-the-art models by 2.2-4.6 percentage points while reducing costs by 20-31%. These results demonstrate that our framework not only provides a more fine-grained analysis of agent behavior, but also translates diagnostic signals into tangible performance gains. More broadly, TRAJEVAL transforms agent evaluation beyond outcome-based benchmarking toward mechanism-driven diagnosis of agent success and failure.
SecCodeBench-V2 Technical Report
Feb 17, 2026We introduce SecCodeBench-V2, a publicly released benchmark for evaluating Large Language Model (LLM) copilots' capabilities of generating secure code. SecCodeBench-V2 comprises 98 generation and fix scenarios derived from Alibaba Group's industrial productions, where the underlying security issues span 22 common CWE (Common Weakness Enumeration) categories across five programming languages: Java, C, Python, Go, and Node.js. SecCodeBench-V2 adopts a function-level task formulation: each scenario provides a complete project scaffold and requires the model to implement or patch a designated target function under fixed interfaces and dependencies. For each scenario, SecCodeBench-V2 provides executable proof-of-concept (PoC) test cases for both functional validation and security verification. All test cases are authored and double-reviewed by security experts, ensuring high fidelity, broad coverage, and reliable ground truth. Beyond the benchmark itself, we build a unified evaluation pipeline that assesses models primarily via dynamic execution. For most scenarios, we compile and run model-generated artifacts in isolated environments and execute PoC test cases to validate both functional correctness and security properties. For scenarios where security issues cannot be adjudicated with deterministic test cases, we additionally employ an LLM-as-a-judge oracle. To summarize performance across heterogeneous scenarios and difficulty levels, we design a Pass@K-based scoring protocol with principled aggregation over scenarios and severity, enabling holistic and comparable evaluation across models. Overall, SecCodeBench-V2 provides a rigorous and reproducible foundation for assessing the security posture of AI coding assistants, with results and artifacts released at https://alibaba.github.io/sec-code-bench. The benchmark is publicly available at https://github.com/alibaba/sec-code-bench.
Secure Code Generation via Online Reinforcement Learning with Vulnerability Reward Model
Feb 07, 2026Large language models (LLMs) are increasingly used in software development, yet their tendency to generate insecure code remains a major barrier to real-world deployment. Existing secure code alignment methods often suffer from a functionality--security paradox, improving security at the cost of substantial utility degradation. We propose SecCoderX, an online reinforcement learning framework for functionality-preserving secure code generation. SecCoderX first bridges vulnerability detection and secure code generation by repurposing mature detection resources in two ways: (i) synthesizing diverse, reality-grounded vulnerability-inducing coding tasks for online RL rollouts, and (ii) training a reasoning-based vulnerability reward model that provides scalable and reliable security supervision. Together, these components are unified in an online RL loop to align code LLMs to generate secure and functional code. Extensive experiments demonstrate that SecCoderX achieves state-of-the-art performance, improving Effective Safety Rate (ESR) by approximately 10% over unaligned models, whereas prior methods often degrade ESR by 14-54%. We release our code, dataset and model checkpoints at https://github.com/AndrewWTY/SecCoderX.
To Defend Against Cyber Attacks, We Must Teach AI Agents to Hack
Feb 01, 2026For over a decade, cybersecurity has relied on human labor scarcity to limit attackers to high-value targets manually or generic automated attacks at scale. Building sophisticated exploits requires deep expertise and manual effort, leading defenders to assume adversaries cannot afford tailored attacks at scale. AI agents break this balance by automating vulnerability discovery and exploitation across thousands of targets, needing only small success rates to remain profitable. Current developers focus on preventing misuse through data filtering, safety alignment, and output guardrails. Such protections fail against adversaries who control open-weight models, bypass safety controls, or develop offensive capabilities independently. We argue that AI-agent-driven cyber attacks are inevitable, requiring a fundamental shift in defensive strategy. In this position paper, we identify why existing defenses cannot stop adaptive adversaries and demonstrate that defenders must develop offensive security intelligence. We propose three actions for building frontier offensive AI capabilities responsibly. First, construct comprehensive benchmarks covering the full attack lifecycle. Second, advance from workflow-based to trained agents for discovering in-wild vulnerabilities at scale. Third, implement governance restricting offensive agents to audited cyber ranges, staging release by capability tier, and distilling findings into safe defensive-only agents. We strongly recommend treating offensive AI capabilities as essential defensive infrastructure, as containing cybersecurity risks requires mastering them in controlled settings before adversaries do.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
An Empirical Study of Vulnerabilities in Python Packages and Their Detection
Sep 04, 2025In the rapidly evolving software development landscape, Python stands out for its simplicity, versatility, and extensive ecosystem. Python packages, as units of organization, reusability, and distribution, have become a pressing concern, highlighted by the considerable number of vulnerability reports. As a scripting language, Python often cooperates with other languages for performance or interoperability. This adds complexity to the vulnerabilities inherent to Python packages, and the effectiveness of current vulnerability detection tools remains underexplored. This paper addresses these gaps by introducing PyVul, the first comprehensive benchmark suite of Python-package vulnerabilities. PyVul includes 1,157 publicly reported, developer-verified vulnerabilities, each linked to its affected packages. To accommodate diverse detection techniques, it provides annotations at both commit and function levels. An LLM-assisted data cleansing method is incorporated to improve label accuracy, achieving 100% commit-level and 94% function-level accuracy, establishing PyVul as the most precise large-scale Python vulnerability benchmark. We further carry out a distribution analysis of PyVul, which demonstrates that vulnerabilities in Python packages involve multiple programming languages and exhibit a wide variety of types. Moreover, our analysis reveals that multi-lingual Python packages are potentially more susceptible to vulnerabilities. Evaluation of state-of-the-art detectors using this benchmark reveals a significant discrepancy between the capabilities of existing tools and the demands of effectively identifying real-world security issues in Python packages. Additionally, we conduct an empirical review of the top-ranked CWEs observed in Python packages, to diagnose the fine-grained limitations of current detection tools and highlight the necessity for future advancements in the field.
EffiBench-X: A Multi-Language Benchmark for Measuring Efficiency of LLM-Generated Code
May 19, 2025
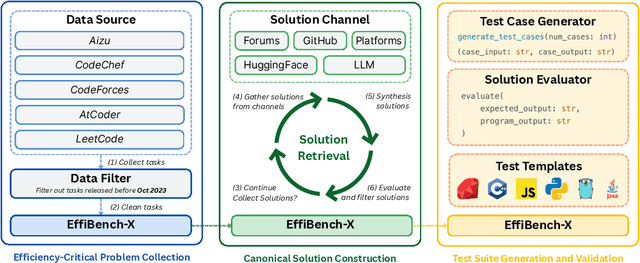


Existing code generation benchmarks primarily evaluate functional correctness, with limited focus on code efficiency and often restricted to a single language like Python. To address this gap, we introduce EffiBench-X, the first multi-language benchmark designed to measure the efficiency of LLM-generated code. EffiBench-X supports Python, C++, Java, JavaScript, Ruby, and Golang. It comprises competitive programming tasks with human-expert solutions as efficiency baselines. Evaluating state-of-the-art LLMs on EffiBench-X reveals that while models generate functionally correct code, they consistently underperform human experts in efficiency. Even the most efficient LLM-generated solutions (Qwen3-32B) achieve only around \textbf{62\%} of human efficiency on average, with significant language-specific variations. LLMs show better efficiency in Python, Ruby, and JavaScript than in Java, C++, and Golang. For instance, DeepSeek-R1's Python code is significantly more efficient than its Java code. These results highlight the critical need for research into LLM optimization techniques to improve code efficiency across diverse languages. The dataset and evaluation infrastructure are submitted and available at https://github.com/EffiBench/EffiBench-X.git and https://huggingface.co/datasets/EffiBench/effibench-x.
Less is More: Towards Green Code Large Language Models via Unified Structural Pruning
Dec 20, 2024The extensive application of Large Language Models (LLMs) in generative coding tasks has raised concerns due to their high computational demands and energy consumption. Unlike previous structural pruning methods designed for classification models that deal with lowdimensional classification logits, generative Code LLMs produce high-dimensional token logit sequences, making traditional pruning objectives inherently limited. Moreover, existing single component pruning approaches further constrain the effectiveness when applied to generative Code LLMs. In response, we propose Flab-Pruner, an innovative unified structural pruning method that combines vocabulary, layer, and Feed-Forward Network (FFN) pruning. This approach effectively reduces model parameters while maintaining performance. Additionally, we introduce a customized code instruction data strategy for coding tasks to enhance the performance recovery efficiency of the pruned model. Through extensive evaluations on three state-of-the-art Code LLMs across multiple generative coding tasks, the results demonstrate that Flab-Pruner retains 97% of the original performance after pruning 22% of the parameters and achieves the same or even better performance after post-training. The pruned models exhibit significant improvements in storage, GPU usage, computational efficiency, and environmental impact, while maintaining well robustness. Our research provides a sustainable solution for green software engineering and promotes the efficient deployment of LLMs in real-world generative coding intelligence applications.