 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Vulnerabilities in Python Packages and Their Detection
Sep 04, 2025In the rapidly evolving software development landscape, Python stands out for its simplicity, versatility, and extensive ecosystem. Python packages, as units of organization, reusability, and distribution, have become a pressing concern, highlighted by the considerable number of vulnerability reports. As a scripting language, Python often cooperates with other languages for performance or interoperability. This adds complexity to the vulnerabilities inherent to Python packages, and the effectiveness of current vulnerability detection tools remains underexplored. This paper addresses these gaps by introducing PyVul, the first comprehensive benchmark suite of Python-package vulnerabilities. PyVul includes 1,157 publicly reported, developer-verified vulnerabilities, each linked to its affected packages. To accommodate diverse detection techniques, it provides annotations at both commit and function levels. An LLM-assisted data cleansing method is incorporated to improve label accuracy, achieving 100% commit-level and 94% function-level accuracy, establishing PyVul as the most precise large-scale Python vulnerability benchmark. We further carry out a distribution analysis of PyVul, which demonstrates that vulnerabilities in Python packages involve multiple programming languages and exhibit a wide variety of types. Moreover, our analysis reveals that multi-lingual Python packages are potentially more susceptible to vulnerabilities. Evaluation of state-of-the-art detectors using this benchmark reveals a significant discrepancy between the capabilities of existing tools and the demands of effectively identifying real-world security issues in Python packages. Additionally, we conduct an empirical review of the top-ranked CWEs observed in Python packages, to diagnose the fine-grained limitations of current detection tools and highlight the necessity for future advancements in the field.
Pop Quiz! Do Pre-trained Code Models Possess Knowledge of Correct API Names?
Sep 14, 2023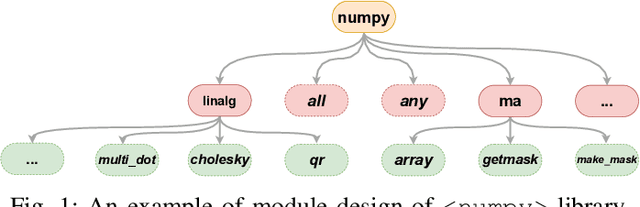
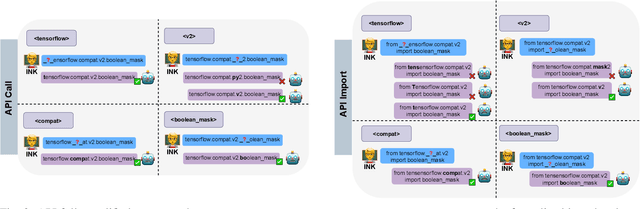
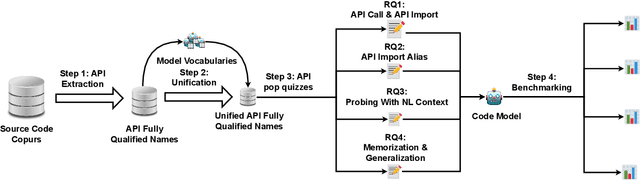
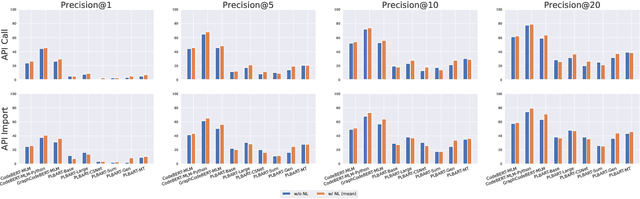
Recent breakthroughs in pre-trained code models, such as CodeBERT and Codex, have shown their superior performance in various downstream tasks. The correctness and unambiguity of API usage among these code models are crucial for achieving desirable program functionalities, requiring them to learn various API fully qualified names structurally and semantically. Recent studies reveal that even state-of-the-art pre-trained code models struggle with suggesting the correct APIs during code generation. However, the reasons for such poor API usage performance are barely investigated. To address this challenge, we propose using knowledge probing as a means of interpreting code models, which uses cloze-style tests to measure the knowledge stored in models. Our comprehensive study examines a code model's capability of understanding API fully qualified names from two different perspectives: API call and API import. Specifically, we reveal that current code models struggle with understanding API names, with pre-training strategies significantly affecting the quality of API name learning. We demonstrate that natural language context can assist code models in locating Python API names and generalize Python API name knowledge to unseen data. Our findings provide insights into the limitations and capabilities of current pre-trained code models, and suggest that incorporating API structure into the pre-training process can improve automated API usage and code representations. This work provides significance for advancing code intelligence practices and direction for future studies. All experiment results, data and source code used in this work are available at \url{https://doi.org/10.5281/zenodo.7902072}.