 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiTS: A Modular Framework for LLM Tree Search
Feb 28, 2026LiTS is a modular Python framework for LLM reasoning via tree search. It decomposes tree search into three reusable components (Policy, Transition, and RewardModel) that plug into algorithms like MCTS and BFS. A decorator-based registry enables domain experts to extend to new domains by registering components, and algorithmic researchers to implement custom search algorithms. We demonstrate composability on MATH500 (language reasoning), Crosswords (environment planning), and MapEval (tool use), showing that components and algorithms are orthogonal: components are reusable across algorithms within each task type, and algorithms work across all components and domains. We also report a mode-collapse finding: in infinite action spaces, LLM policy diversity (not reward quality) is the bottleneck for effective tree search. A demonstration video is available at https://youtu.be/nRGX43YrR3I. The package is released under the Apache 2.0 license at https://github.com/xinzhel/lits-llm, including installation instructions and runnable examples that enable users to reproduce the demonstrated workflows.
OmniVTON++: Training-Free Universal Virtual Try-On with Principal Pose Guidance
Feb 16, 2026Image-based Virtual Try-On (VTON) concerns the synthesis of realistic person imagery through garment re-rendering under human pose and body constraints. In practice, however, existing approaches are typically optimized for specific data conditions, making their deployment reliant on retraining and limiting their generalization as a unified solution. We present OmniVTON++, a training-free VTON framework designed for universal applicability. It addresses the intertwined challenges of garment alignment, human structural coherence, and boundary continuity by coordinating Structured Garment Morphing for correspondence-driven garment adaptation, Principal Pose Guidance for step-wise structural regulation during diffusion sampling, and Continuous Boundary Stitching for boundary-aware refinement, forming a cohesive pipeline without task-specific retraining. Experimental results demonstrate that OmniVTON++ achieves state-of-the-art performance across diverse generalization settings, including cross-dataset and cross-garment-type evaluations, while reliably operating across scenarios and diffusion backbones within a single formulation. In addition to single-garment, single-human cases, the framework supports multi-garment, multi-human, and anime character virtual try-on, expanding the scope of virtual try-on applications. The source code will be released to the public.
AvatarVTON: 4D Virtual Try-On for Animatable Avatars
Oct 06, 2025We propose AvatarVTON, the first 4D virtual try-on framework that generates realistic try-on results from a single in-shop garment image, enabling free pose control, novel-view rendering, and diverse garment choices. Unlike existing methods, AvatarVTON supports dynamic garment interactions under single-view supervision, without relying on multi-view garment captures or physics priors. The framework consists of two key modules: (1) a Reciprocal Flow Rectifier, a prior-free optical-flow correction strategy that stabilizes avatar fitting and ensures temporal coherence; and (2) a Non-Linear Deformer, which decomposes Gaussian maps into view-pose-invariant and view-pose-specific components, enabling adaptive, non-linear garment deformations. To establish a benchmark for 4D virtual try-on, we extend existing baselines with unified modules for fair qualitative and quantitative comparisons. Extensive experiments show that AvatarVTON achieves high fidelity, diversity, and dynamic garment realism, making it well-suited for AR/VR, gaming, and digital-human applications.
An Empirical Study of Vulnerabilities in Python Packages and Their Detection
Sep 04, 2025In the rapidly evolving software development landscape, Python stands out for its simplicity, versatility, and extensive ecosystem. Python packages, as units of organization, reusability, and distribution, have become a pressing concern, highlighted by the considerable number of vulnerability reports. As a scripting language, Python often cooperates with other languages for performance or interoperability. This adds complexity to the vulnerabilities inherent to Python packages, and the effectiveness of current vulnerability detection tools remains underexplored. This paper addresses these gaps by introducing PyVul, the first comprehensive benchmark suite of Python-package vulnerabilities. PyVul includes 1,157 publicly reported, developer-verified vulnerabilities, each linked to its affected packages. To accommodate diverse detection techniques, it provides annotations at both commit and function levels. An LLM-assisted data cleansing method is incorporated to improve label accuracy, achieving 100% commit-level and 94% function-level accuracy, establishing PyVul as the most precise large-scale Python vulnerability benchmark. We further carry out a distribution analysis of PyVul, which demonstrates that vulnerabilities in Python packages involve multiple programming languages and exhibit a wide variety of types. Moreover, our analysis reveals that multi-lingual Python packages are potentially more susceptible to vulnerabilities. Evaluation of state-of-the-art detectors using this benchmark reveals a significant discrepancy between the capabilities of existing tools and the demands of effectively identifying real-world security issues in Python packages. Additionally, we conduct an empirical review of the top-ranked CWEs observed in Python packages, to diagnose the fine-grained limitations of current detection tools and highlight the necessity for future advancements in the field.
HarmonPaint: Harmonized Training-Free Diffusion Inpainting
Jul 22, 2025Existing inpainting methods often require extensive retraining or fine-tuning to integrate new content seamlessly, yet they struggle to maintain coherence in both structure and style between inpainted regions and the surrounding background. Motivated by these limitations, we introduce HarmonPaint, a training-free inpainting framework that seamlessly integrates with the attention mechanisms of diffusion models to achieve high-quality, harmonized image inpainting without any form of training. By leveraging masking strategies within self-attention, HarmonPaint ensures structural fidelity without model retraining or fine-tuning. Additionally, we exploit intrinsic diffusion model properties to transfer style information from unmasked to masked regions, achieving a harmonious integration of styles. Extensive experiments demonstrate the effectiveness of HarmonPaint across diverse scenes and styles, validating its versatility and performance.
A Survey on LLM Test-Time Compute via Search: Tasks, LLM Profiling, Search Algorithms, and Relevant Frameworks
Jan 17, 2025



LLM test-time compute (or LLM inference) via search has emerged as a promising research area with rapid developments. However, current frameworks often adopt distinct perspectives on three key aspects (task definition, LLM profiling, and search procedures), making direct comparisons challenging. Moreover, the search algorithms employed often diverge from standard implementations, and their specific characteristics are not thoroughly specified. In this survey, we provide a comprehensive technical review that unifies task definitions and provides modular definitions of LLM profiling and search procedures. The definitions enable precise comparisons of various LLM inference frameworks while highlighting their departures from conventional search algorithms. We also discuss the applicability, performance, and efficiency of these methods. For further details and ongoing updates, please refer to our GitHub repository: https://github.com/xinzhel/LLM-Agent-Survey/blob/main/search.md
PersonaMagic: Stage-Regulated High-Fidelity Face Customization with Tandem Equilibrium
Dec 20, 2024Personalized image generation has made significant strides in adapting content to novel concepts. However, a persistent challenge remains: balancing the accurate reconstruction of unseen concepts with the need for editability according to the prompt, especially when dealing with the complex nuances of facial features. In this study, we delve into the temporal dynamics of the text-to-image conditioning process, emphasizing the crucial role of stage partitioning in introducing new concepts. We present PersonaMagic, a stage-regulated generative technique designed for high-fidelity face customization. Using a simple MLP network, our method learns a series of embeddings within a specific timestep interval to capture face concepts. Additionally, we develop a Tandem Equilibrium mechanism that adjusts self-attention responses in the text encoder, balancing text description and identity preservation, improving both areas. Extensive experiments confirm the superiority of PersonaMagic over state-of-the-art methods in both qualitative and quantitative evaluations. Moreover, its robustness and flexibility are validated in non-facial domains, and it can also serve as a valuable plug-in for enhancing the performance of pretrained personalization models.
D$^4$-VTON: Dynamic Semantics Disentangling for Differential Diffusion based Virtual Try-On
Jul 21, 2024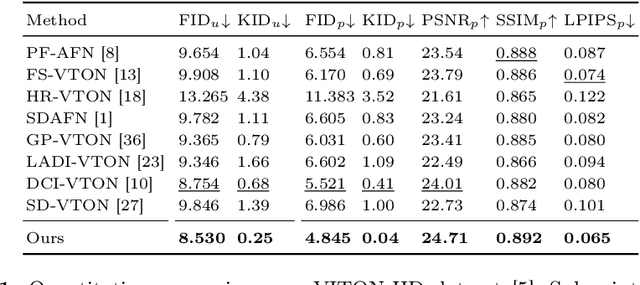
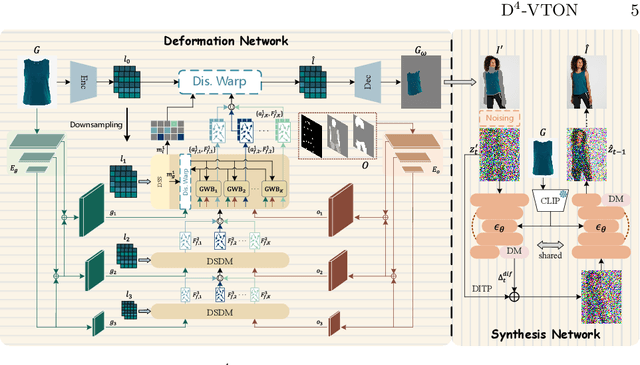
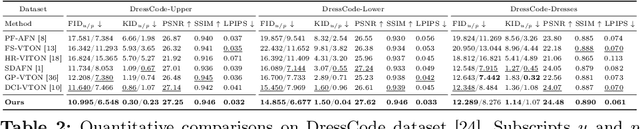
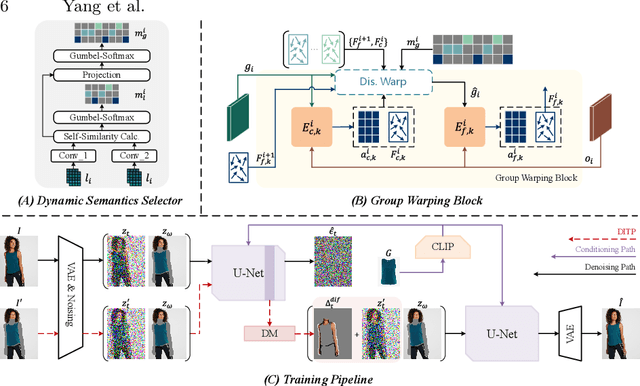
In this paper, we introduce D$^4$-VTON, an innovative solution for image-based virtual try-on. We address challenges from previous studies, such as semantic inconsistencies before and after garment warping, and reliance on static, annotation-driven clothing parsers. Additionally, we tackle the complexities in diffusion-based VTON models when handling simultaneous tasks like inpainting and denoising. Our approach utilizes two key technologies: Firstly, Dynamic Semantics Disentangling Modules (DSDMs) extract abstract semantic information from garments to create distinct local flows, improving precise garment warping in a self-discovered manner. Secondly, by integrating a Differential Information Tracking Path (DITP), we establish a novel diffusion-based VTON paradigm. This path captures differential information between incomplete try-on inputs and their complete versions, enabling the network to handle multiple degradations independently, thereby minimizing learning ambiguities and achieving realistic results with minimal overhead. Extensive experiments demonstrate that D$^4$-VTON significantly outperforms existing methods in both quantitative metrics and qualitative evaluations, demonstrating its capability in generating realistic images and ensuring semantic consistency.
A Survey on LLM-Based Agents: Common Workflows and Reusable LLM-Profiled Components
Jun 16, 2024Recent advancements in Large Language Models (LLMs) have catalyzed the development of sophisticated frameworks for developing LLM-based agents. However, the complexity of these frameworks r poses a hurdle for nuanced differentiation at a granular level, a critical aspect for enabling efficient implementations across different frameworks and fostering future research. Hence, the primary purpose of this survey is to facilitate a cohesive understanding of diverse recently proposed frameworks by identifying common workflows and reusable LLM-Profiled Components (LMPCs).
A Survey on LLM-Based Agentic Workflows and LLM-Profiled Components
Jun 09, 2024Recent advancements in Large Language Models (LLMs) have catalyzed the development of sophisticated agentic workflows, offering improvements over traditional single-path, Chain-of-Thought (CoT) prompting techniques. This survey summarize the common workflows, with the particular focus on LLM-Profiled Components (LMPCs) and ignorance of non-LLM components. The reason behind such exploration is to facilitate a clearer understanding of LLM roles and see how reusabile of the LMPCs.