 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAMMAR: Grounded and Modular Methodology for Assessment of Domain-Specific Retrieval-Augmented Language Model
Paper and Code
May 02, 2024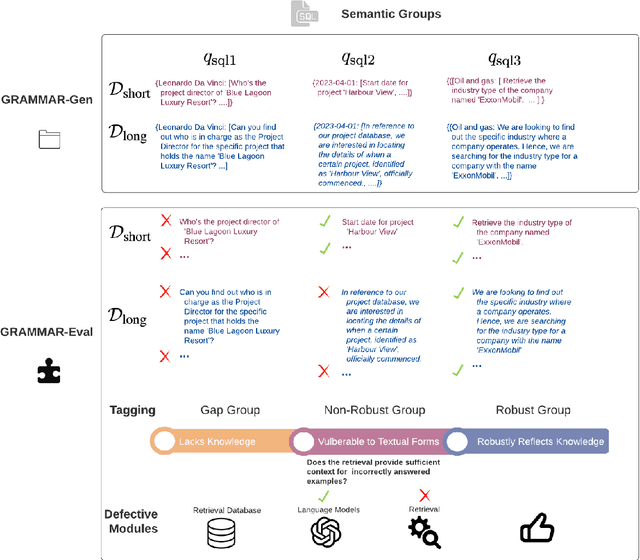

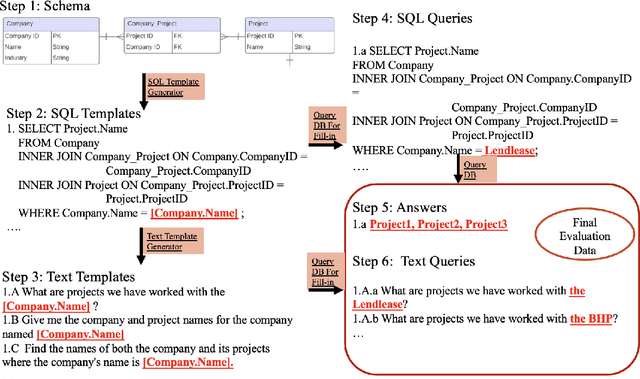

Retrieval-augmented Generation (RAG) systems have been actively studied and deployed across various industries to query on domain-specific knowledge base. However, evaluating these systems presents unique challenges due to the scarcity of domain-specific queries and corresponding ground truths, as well as a lack of systematic approaches to diagnosing the cause of failure cases -- whether they stem from knowledge deficits or issues related to system robustness. To address these challenges, we introduce GRAMMAR (GRounded And Modular Methodology for Assessment of RAG), an evaluation framework comprising two key elements: 1) a data generation process that leverages relational databases and LLMs to efficiently produce scalable query-answer pairs. This method facilitates the separation of query logic from linguistic variations for enhanced debugging capabilities; and 2) an evaluation framework that differentiates knowledge gaps from robustness and enables the identification of defective modules. Our empirical results underscore the limitations of current reference-free evaluation approaches and the reliability of GRAMMAR to accurately identify model vulnerabilities.