 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTONGuard: Automatic Detection and Authentication of AI-Generated Virtual Try-On Content
Jan 20, 2026With the rapid advancement of generative AI, virtual try-on (VTON) systems are becoming increasingly common in e-commerce and digital entertainment. However, the growing realism of AI-generated try-on content raises pressing concerns about authenticity and responsible use. To address this, we present VTONGuard, a large-scale benchmark dataset containing over 775,000 real and synthetic try-on images. The dataset covers diverse real-world conditions, including variations in pose, background, and garment styles, and provides both authentic and manipulated examples. Based on this benchmark, we conduct a systematic evaluation of multiple detection paradigms under unified training and testing protocols. Our results reveal each method's strengths and weaknesses and highlight the persistent challenge of cross-paradigm generalization. To further advance detection, we design a multi-task framework that integrates auxiliary segmentation to enhance boundary-aware feature learning, achieving the best overall performance on VTONGuard. We expect this benchmark to enable fair comparisons, facilitate the development of more robust detection models, and promote the safe and responsible deployment of VTON technologies in practice.
COCO-Inpaint: A Benchmark for Image Inpainting Detection and Manipulation Localization
Apr 25, 2025
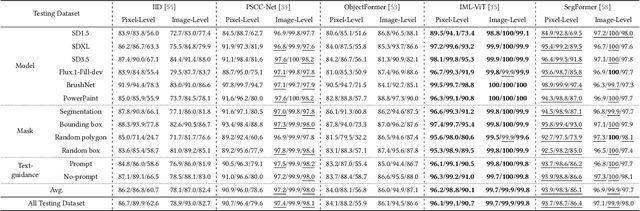


Recent advancements in image manipulation have achieved unprecedented progress in generating photorealistic content, but also simultaneously eliminating barriers to arbitrary manipulation and editing, raising concerns about multimedia authenticity and cybersecurity. However, existing Image Manipulation Detection and Localization (IMDL) methodologies predominantly focus on splicing or copy-move forgeries, lacking dedicated benchmarks for inpainting-based manipulations. To bridge this gap, we present COCOInpaint, a comprehensive benchmark specifically designed for inpainting detection, with three key contributions: 1) High-quality inpainting samples generated by six state-of-the-art inpainting models, 2) Diverse generation scenarios enabled by four mask generation strategies with optional text guidance, and 3) Large-scale coverage with 258,266 inpainted images with rich semantic diversity. Our benchmark is constructed to emphasize intrinsic inconsistencies between inpainted and authentic regions, rather than superficial semantic artifacts such as object shapes. We establish a rigorous evaluation protocol using three standard metrics to assess existing IMDL approaches. The dataset will be made publicly available to facilitate future research in this area.
Towards Explainable Fake Image Detection with Multi-Modal Large Language Models
Apr 19, 2025
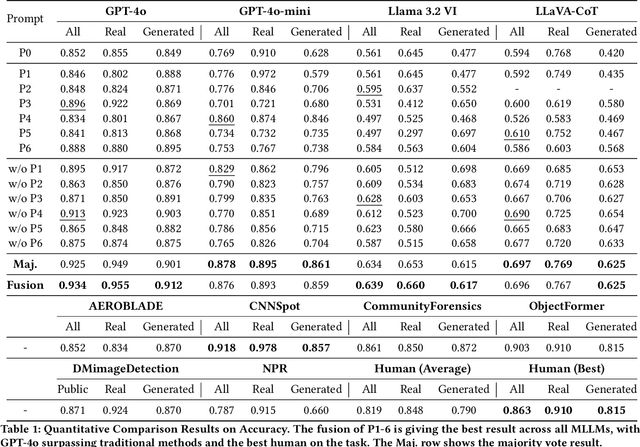

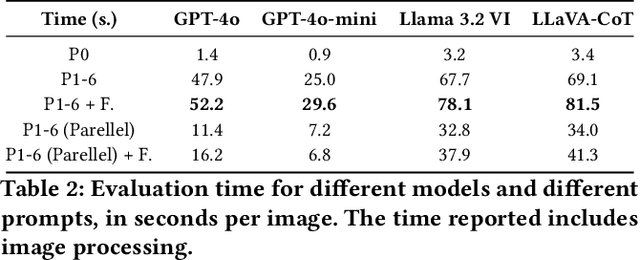
Progress in image generation raises significant public security concerns. We argue that fake image detection should not operate as a "black box". Instead, an ideal approach must ensure both strong generalization and transparency. Recent progress in Multi-modal Large Language Models (MLLMs) offers new opportunities for reasoning-based AI-generated image detection. In this work, we evaluate the capabilities of MLLMs in comparison to traditional detection methods and human evaluators, highlighting their strengths and limitations. Furthermore, we design six distinct prompts and propose a framework that integrates these prompts to develop a more robust, explainable, and reasoning-driven detection system. The code is available at https://github.com/Gennadiyev/mllm-defake.
High-Quality 3D Head Reconstruction from Any Single Portrait Image
Mar 11, 2025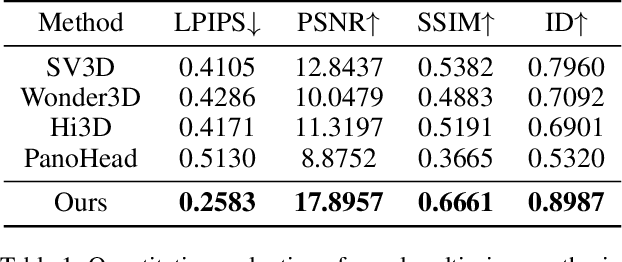
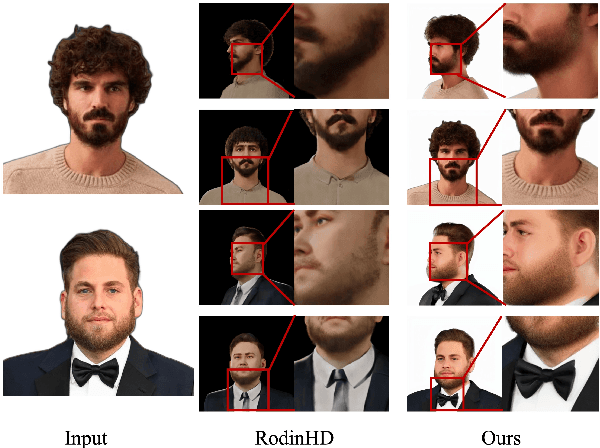
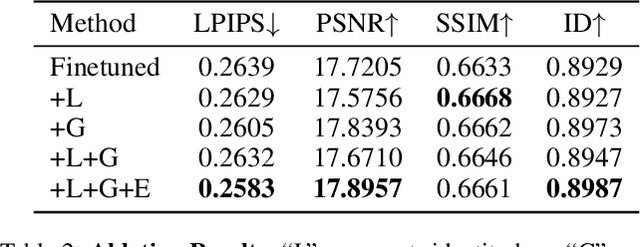
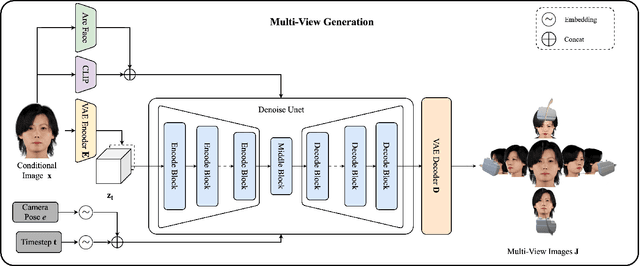
In this work, we introduce a novel high-fidelity 3D head reconstruction method from a single portrait image, regardless of perspective, expression, or accessories. Despite significant efforts in adapting 2D generative models for novel view synthesis and 3D optimization, most methods struggle to produce high-quality 3D portraits. The lack of crucial information, such as identity, expression, hair, and accessories, limits these approaches in generating realistic 3D head models. To address these challenges, we construct a new high-quality dataset containing 227 sequences of digital human portraits captured from 96 different perspectives, totalling 21,792 frames, featuring diverse expressions and accessories. To further improve performance, we integrate identity and expression information into the multi-view diffusion process to enhance facial consistency across views. Specifically, we apply identity- and expression-aware guidance and supervision to extract accurate facial representations, which guide the model and enforce objective functions to ensure high identity and expression consistency during generation. Finally, we generate an orbital video around the portrait consisting of 96 multi-view frames, which can be used for 3D portrait model reconstruction. Our method demonstrates robust performance across challenging scenarios, including side-face angles and complex accessories
PersonaMagic: Stage-Regulated High-Fidelity Face Customization with Tandem Equilibrium
Dec 20, 2024Personalized image generation has made significant strides in adapting content to novel concepts. However, a persistent challenge remains: balancing the accurate reconstruction of unseen concepts with the need for editability according to the prompt, especially when dealing with the complex nuances of facial features. In this study, we delve into the temporal dynamics of the text-to-image conditioning process, emphasizing the crucial role of stage partitioning in introducing new concepts. We present PersonaMagic, a stage-regulated generative technique designed for high-fidelity face customization. Using a simple MLP network, our method learns a series of embeddings within a specific timestep interval to capture face concepts. Additionally, we develop a Tandem Equilibrium mechanism that adjusts self-attention responses in the text encoder, balancing text description and identity preservation, improving both areas. Extensive experiments confirm the superiority of PersonaMagic over state-of-the-art methods in both qualitative and quantitative evaluations. Moreover, its robustness and flexibility are validated in non-facial domains, and it can also serve as a valuable plug-in for enhancing the performance of pretrained personalization models.
One-for-All: Towards Universal Domain Translation with a Single StyleGAN
Oct 22, 2023


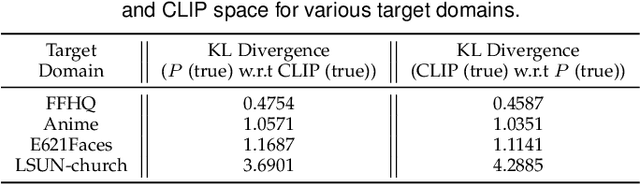
In this paper, we propose a novel translation model, UniTranslator, for transforming representations between visually distinct domains under conditions of limited training data and significant visual differences. The main idea behind our approach is leveraging the domain-neutral capabilities of CLIP as a bridging mechanism, while utilizing a separate module to extract abstract, domain-agnostic semantics from the embeddings of both the source and target realms. Fusing these abstract semantics with target-specific semantics results in a transformed embedding within the CLIP space. To bridge the gap between the disparate worlds of CLIP and StyleGAN, we introduce a new non-linear mapper, the CLIP2P mapper. Utilizing CLIP embeddings, this module is tailored to approximate the latent distribution in the P space, effectively acting as a connector between these two spaces. The proposed UniTranslator is versatile and capable of performing various tasks, including style mixing, stylization, and translations, even in visually challenging scenarios across different visual domains. Notably, UniTranslator generates high-quality translations that showcase domain relevance, diversity, and improved image quality. UniTranslator surpasses the performance of existing general-purpose models and performs well against specialized models in representative tasks. The source code and trained models will be released to the public.
Curricular Contrastive Regularization for Physics-aware Single Image Dehazing
Mar 24, 2023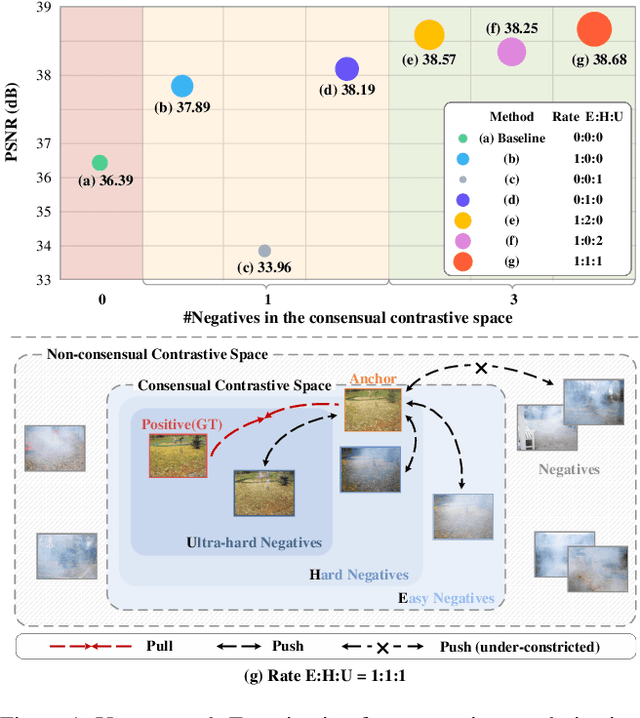
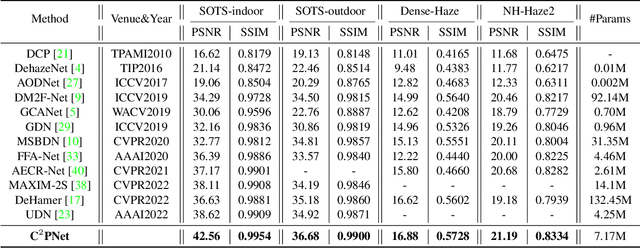
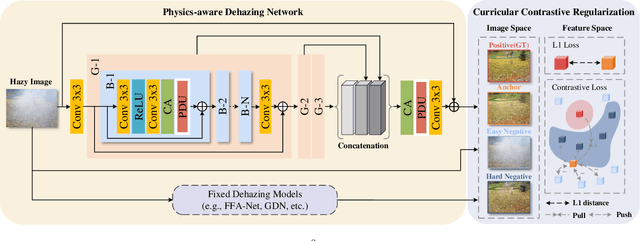

Considering the ill-posed nature, contrastive regularization has been developed for single image dehazing, introducing the information from negative images as a lower bound. However, the contrastive samples are nonconsensual, as the negatives are usually represented distantly from the clear (i.e., positive) image, leaving the solution space still under-constricted. Moreover, the interpretability of deep dehazing models is underexplored towards the physics of the hazing process. In this paper, we propose a novel curricular contrastive regularization targeted at a consensual contrastive space as opposed to a non-consensual one. Our negatives, which provide better lower-bound constraints, can be assembled from 1) the hazy image, and 2) corresponding restorations by other existing methods. Further, due to the different similarities between the embeddings of the clear image and negatives, the learning difficulty of the multiple components is intrinsically imbalanced. To tackle this issue, we customize a curriculum learning strategy to reweight the importance of different negatives. In addition, to improve the interpretability in the feature space, we build a physics-aware dual-branch unit according to the atmospheric scattering model. With the unit, as well as curricular contrastive regularization, we establish our dehazing network, named C2PNet. Extensive experiments demonstrate that our C2PNet significantly outperforms state-of-the-art methods, with extreme PSNR boosts of 3.94dB and 1.50dB, respectively, on SOTS-indoor and SOTS-outdoor datasets.